第一步,环境的配置
由于Hadoop的底层是java,所以需要安装jdk,并配置好java环境。
安装jdk就不详细说明了,这里主要说配置java的环境变量。进入/etc/profile文件中配置java环境变量
编辑文件
vi /etc/profile
在最末尾加入配置的命令如下
export JAVA_HOME=/usr/java/jdk1.7.0_67(这里的路径根据个人jdk所在路径所决定)
export PATH=$PATH:$JAVA_HOME/bin
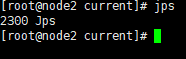
配置好以后,通过source /etc/profile更新一下配置,然后使用jps命令测试java环境是否配置好了。如果出现下图,则说明配置成功。
第二步,配置免密钥。
通过这两个命令,可以配置免密钥。为了切换节点不需要验证用户的密码
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
第三步,下载安装包,并配置环境变量
我下载的安装包是 hadoop-2.6.5.tar.gz
解压
tar xf hadoop-2.6.5.tar.gz(压缩包是自己下载的压缩包)
解压完成后,进行Hadoop的环境变量的配置
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_HOME=/root/hadoop-2.6.5(这里是你Hadoop安装的路径)
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
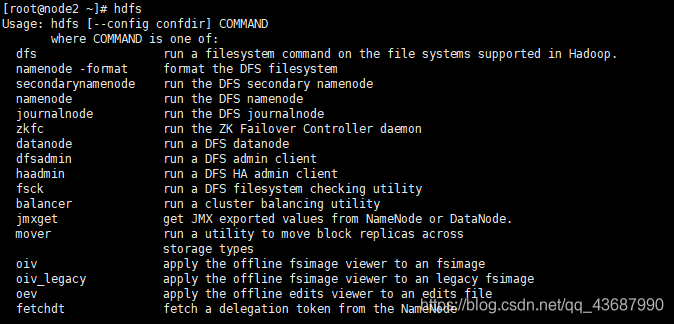
检查是否配置成功,可以通过输入hdfs进行验证
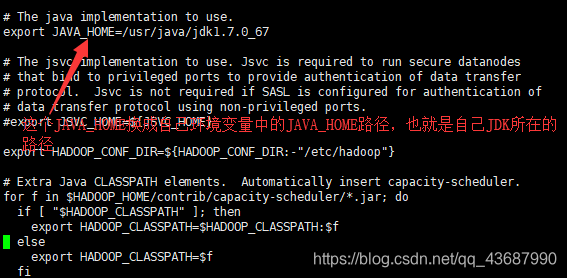
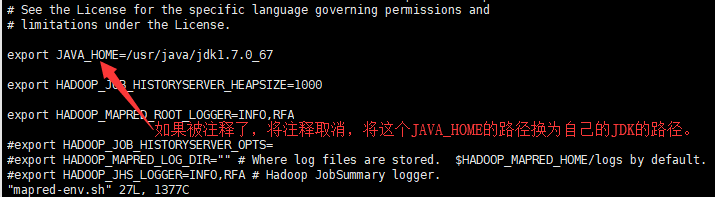
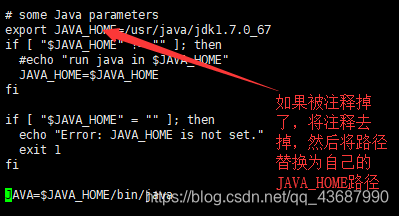
第四步,Hadoop的第二次JAVA_HOME环境变量配置
需要配置三个文件上的 hadoop-env.sh、 mapred-env.sh 、yarn-env.sh
首先进入到 hadoop-2.6.5/etc/hadop目录下
vi hadoop-env.sh
vi mapred-env.sh
vi yarn-env.sh
第五步,配置core-site.xml
vi core-site.xml
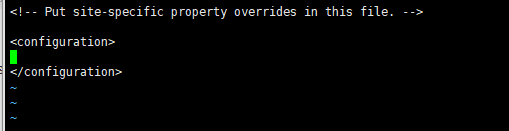
在configuration中插入一下配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://node2[此处node2是你虚拟机中IP的别名,对应着你节点的IP,如我的node2对应着虚拟机IP:192.168.163.xx]:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/sxt/hadoop/local</value> #此处路径为自由设置,用来存dataNode和nameNode等数据
</property>
第六步,配置hdf-site.xml
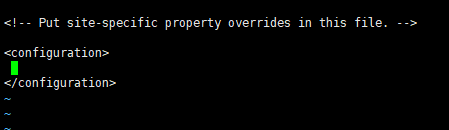
在configuration中添加如下配置:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node06(改为自己虚拟机IP对应的别名):50090</value>
</property>
第七步,配置slaves文件
将里边的localhost改为自己虚拟机IP对应的别名,如我改为了node2
第八步,格式化hdfs
hdfs namenode -format (只能格式化一次,再次启动集群不要执行)

第九步,启动集群
start-dfs.sh
通过jps查看角色进程
查看web UI: IP:50070,可以看到下面的页面
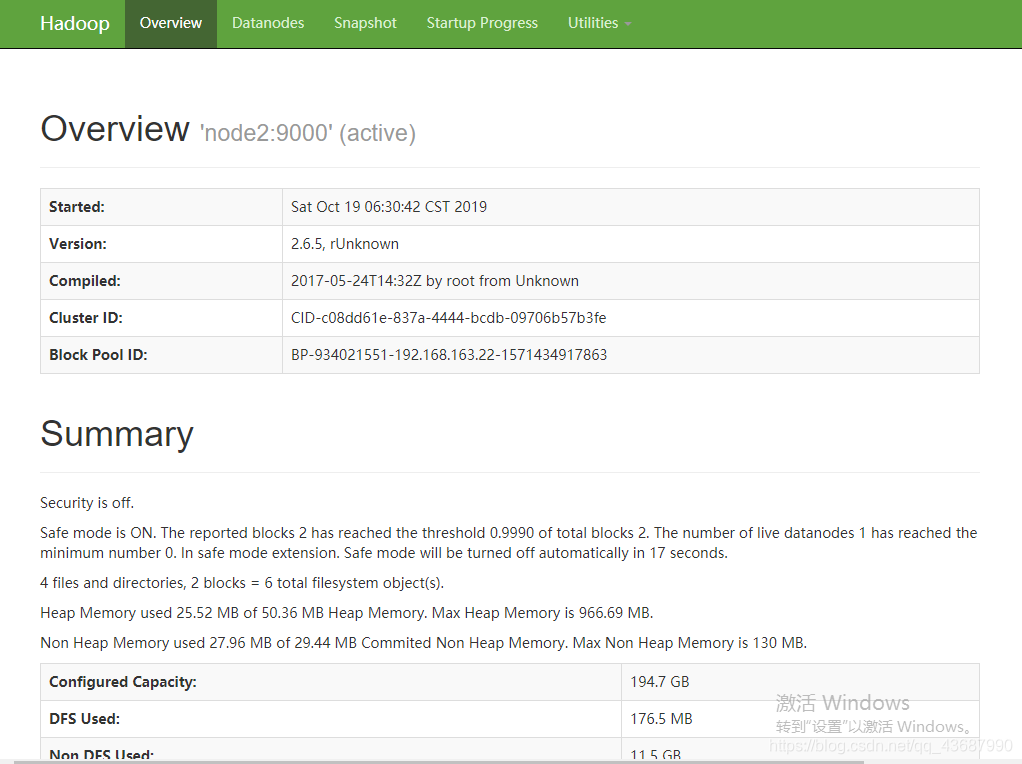
第十步,上传文件测试
创建目录,将文件上传到自己所创建的目录中:hdfs dfs -mkdir -p /user/root (我的路径:/user/root)
查看目录: hdfs dfs -ls /
上传文件: hdfs dfs -put hadoop-2.6.5.tar.gz /user/root
停止集群:stop-dfs.dh