讲授Lenet、Alexnet、VGGNet、GoogLeNet等经典的卷积神经网络、Inception模块、小尺度卷积核、1x1卷积核、使用反卷积实现卷积层可视化等。
大纲:
LeNet网络
AlexNet网络
VGG网络
GoogLeNnet网络
反卷积可视化
数学特性
根据卷积结果重构图像
本集总结
LeNet网络:
LeNet-5网络是Y.LeCun1998年提出来的,现在尊称Y.LeCun为卷积神经网络之父,后来他去了Facebook的AI实验室。
这是第一个广为传播的卷积网络,规模很小,但五脏俱全(卷积、池化、全连接层都有),用于手写文字的识别,采用了标准的卷积层,池化层,全连接层结构,此后各种卷积网络的设计都借鉴了它的思想。
这篇文章提出的方法并没有大规模的被使用和广泛地引起关注,当时是SVM、AdaBoost占据优势,从1998年LeNet出现以后到2012年AlexNet出现,之间的十几年里边,卷积神经网络并没有得到很好的发展。
LeNet网络的结构:

MINIST数据集,两个卷积层、两个池化层、一些全连接层,输入图像32×32的灰度图像,第一个卷积层的卷积核的尺寸是5×5的六组卷积核,第一层卷积之后,得到6张(6通道)28×28的图像,再经过2×2的池化层变为6张14×14的图像。
第二个卷积层为16组卷积核,卷积核尺寸也是5×5的,前面讲的多通道卷积的时候按照常规的做法是,上层池化层输出是6通道的,这16组卷积核,每组应该是6通道的分别和输入的6通道卷积加起来,但是这里没有这样做,第0个卷积核只用了前三个通道卷积,后边的卷积核分别不同,如下图
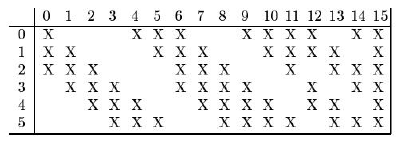
卷积完之后得到16个10×10的图像(16通道),然后第二个池化层进行下采样,得到16个5×5的图像。
然后是全连接层,把16中5×5的图像一字摆开,所有图形的像素拼接成一个向量,当成全连接网络的输入层,后边跟着一个120个神经元的全连接层,再跟着一个84个神经元的全连接层,最后一个是输出层10个神经元,即10个类的数字。
每个卷积层、全连接层都带有一个激活函数的作用,激活函数统一采用tanh函数,损失函数采用欧氏距离(之前多用欧氏距离损失函数,后边采用交叉熵和其他损失函数)。训练的时候采用梯度下降法进行训练,样本的标签值(十个类)采用one-hot编码形式的。
AlexNet网络:
由于计算能力(GPU没有用来做大规模机器学习使用)和训练样本数(没有数码相机和手机)的限制,网络层数增加带来的梯度消失等问题的困扰,在1989年LeNet提出后到2012年之间卷积神经网络并没有得到广泛的关注与大规模的应用。
直到2012年,Hinton等人设计出一个称为AlexNet(也是用人的名字命名的×××Net,Alex是人名,是一个深层的神经网络,本质上和LeNet没有多大差别)的深层卷积神经网络,在图像分类(ImageNet数据集,有大量图像和标签,而LeNet是MINIST数据集)任务上取得了成功。
Alex Krizhevsky, Ilya Sutskever, Geoffrey E.Hinton. ImageNet Classification with Deep Convolutional Neural Networks.2012
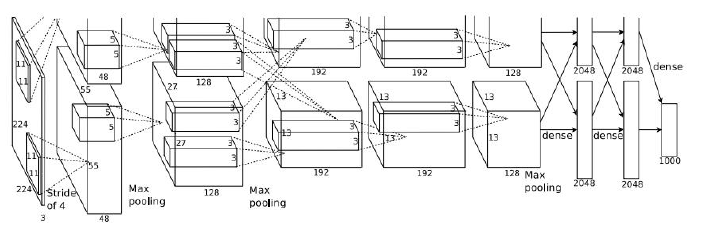
卷积核是11×11,图像输入是224×224的图像三通道RGB彩色图像(LeNet输入是32×32单通道,卷积核是5×5),卷积完分成两个组进行卷积,输出使用softmax变换,卷积核逐渐变小。结构上和LeNet相比,层次加深了,神经元的个数增多了,参数多了很多。
AlexNex网络的主要改进:
层数更深,参数更多,规模更大,训练样本更多(ImageNet数据集,而LeNet是MINIST数据集),采用了GPU加速。
真正的创新:
①新的激活函数ReLU函数(LeNet是tanh函数,更早的是sigmoid函数),tanh函数容易饱和产生梯度消失问题。
ReLU(x) = max(0,x)一定程度上缓解梯度消失问题(只是缓解没有根除,导数算起来简单,很多时候导数为1多次连乘梯度幅度不变,梯度消失是多个小于1的导数相乘值为0),在x=0不可导,并不影响全局。
②dropout机制
是一种正则化的技术,在训练的时候,挑出一部分神经元,如128个神经元随机挑出64个神经元不参加训练,即数据透明通过输入和输出一样,反向传播的时候也是那些神经元不更新,只是神经网络训练的时候用,训练完就不用这种机制了。
在训练时随机的选择一部分神经元进行正向传播和反向传播,另外一些神经元的参数值保持不变,以减轻过拟合。
dropout机制使得每个神经元在训练时只用了样本集中的部分样本,这相当于对样本集进行采样,即bagging的做法。最终得到的是多个神经网络的组合,但这不是一种严格的解释。
同机器学习的bagging机制类似,从整个大样本集中随机抽样抽出N个样本集出来,来训练每一个弱学习器,训练出来的每一个若学习器之间是相互独立的用各自的样本集训练的,但这里的神经网络是一个整体的,并不能看成是多个弱学习器的集成。
这个小的技巧可以取得很好的效果,可以减轻过拟合并不能消除过拟合。2012年在ImageNet一千个类的分类问题取得第一名遥遥领先于第二名,相比于2011年冠军的结果提高了很多个百分点,从此卷积神经网络得到了大规模的关注。ReLU函数很早就出来了,是第一次用到是卷积神经网络,缓解梯度消失非根除梯度消失。