Python Scrapy爬虫
预备知识:
1、Scrapy框架:是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架。
2、Scrapy去重原理:Scrapy本身自带有一个中间件。scrapy源码中可以找到一个dupefilters.py去重器,需要将dont_filter设置为False开启去重,默认是True,没有开启去重。
3、指纹去重:对于每一个URL的请求,调度器都会根据请求得相关信息加密得到一个指纹信息,并且将该URL的指纹信息和set()集合中的指纹信息进行比对。如果set()集合中已经存在这个数据,就不在将这个Request放入队列中,如果set()集合中没有存在这个加密后的数据,就将这个Request对象放入队列中,等待被调度。
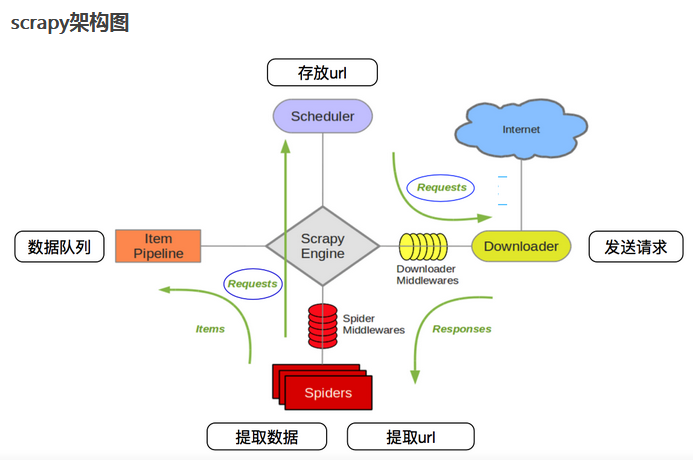
4、Scrapy框架下各个模块:
-
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
-
Scheduler(调度器): 假设其为一个URL的优先队列,由其来决定下一个要抓取的网址是什么,同时去除重复的网址。用户可以自己的需求定制调度器
-
Downloader(下载器):用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上
-
Spider(爬虫):用户定制自己的爬虫,用于从特定的网页中提取需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接(URL),让Scrapy继续抓取下一个页面。
-
Item Pipeline(实体管道):用于处理爬虫提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息
-
Downloader Middlewares(下载中间件/有User_Agent、Proxy代理):可以当作是一个可以自定义扩展下载功能的组件
-
Spider Middlewares(Spider中间件):可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
图-1 scrapy框架