深度度量学习的目标是学习一个嵌入空间来从数据点中捕捉语义信息。现有的成对或者三元组方法随着模型迭代过程会出现大量的平凡组导致收敛缓慢。针对这个问题,一些基于排序结构的损失取得了不错的结果,本文主要是针对排序loss存在的两个限制做的改进。
- 限制一:给定一个query,只利用了小部分的数据点来构建相似度结构,导致一些有用信息被忽略。本文给出的解决方案是把样本划分为正例集和负例集,目标是使得query离正例集比负例集近一个间隔。
- 限制二:此前方法都是在嵌入空间尽可能推进正样本的距离忽略了类内差异,作者使用一个超参来保留类内分布。

作者先是回顾了目前存在的一些loss, 从上图可以看到,ranked list loss也就是本文提出的方法,在训练中充分利用了输入样本信息。
本文的想法是把正例样本与负例样本以$m$隔开,类内样本允许存在$\alpha-m$的分布差异,如下图所示:
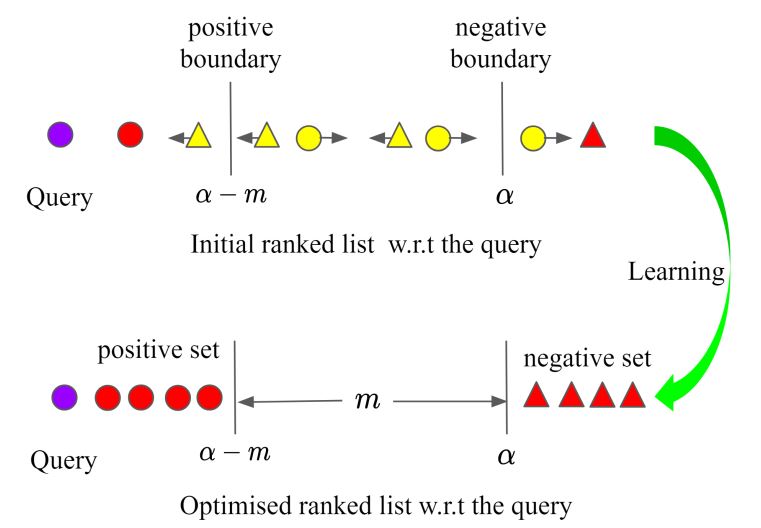
其基于成对损失,上图可以表示为:
$L_{\mathrm{m}}\left(\mathbf{x}_{i}, \mathbf{x}_{j} ; f\right)=\left(1-y_{i j}\right)\left[\alpha-d_{i j}\right]_{+}+y_{i j}\left[d_{i j}-(\alpha-m)\right]_{+}$
其中${x}_{i}$为query,$d_{i j}=\left\|f\left(\mathbf{x}_{i}\right)-f\left(\mathbf{x}_{j}\right)\right\|_{2}$为样本间欧式距离,当$y_{i}=y_{j}$时,$y_{i j}=1$,反之为0。