曼哈顿距离(CityBlockSimilarity)
同欧式距离相似,都是用于多维数据空间距离的测度。
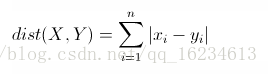
欧式距离(Euclidean Distance)
用于衡量多维空间中各个点之间的绝对距离。欧式距离的缺点就是将每个维度同等看待,但显然不是,比如人脸vector,显然眼睛、鼻子、嘴部特征应该更为重要。因此使用时各个维度量级最好能够在同一个尺度上。

马氏距离(Mahalanobis distance)
一种有效的计算两个未知样本集的相似度的方法。与欧氏距离将所有维度同等看待不同,其考虑到各种维度之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的),并且是尺度无关的(scale-invariant),即独立于测量尺度。作为欧式距离的标准化版,归一化特征的同时也有可能过分看重微小变化的特征。
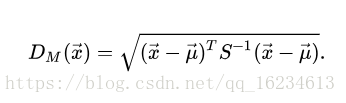
其中x为单个样本,u为样本集合均值,S为样本集合协方差。
明可夫斯基距离(Minkowski Distance)
明氏距离,是欧氏空间中的一种测度,被看做是欧氏距离和曼哈顿距离的一种推广。
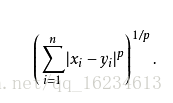
切比雪夫距离(Chebyshev Distance)
各坐标数值差的最大值。

余弦相似度(Cosine Similarity)
用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
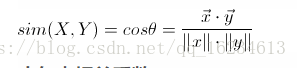
调整余弦相似度(Adjusted Cosine Similarity)
在余弦相似度的介绍中说到:余弦相似度更多的是从方向上区分差异,而对绝对的数值不敏感。因此没法衡量每个维数值的差异,会导致这样一个情况:比如用户对内容评分,5分制,X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得出的结果是0.98,两者极为相似,但从评分上看X似乎不喜欢这两个内容,而Y比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,
需要修正这种不合理性,就出现了调整余弦相似度,即所有维度上的数值都减去一个均值,比如X和Y的评分均值都是3,那么调整后为(-2,-1)和(1,2),再用余弦相似度计算,得到-0.8,相似度为负值并且差异不小,但显然更加符合现实。
皮尔森相关性(Pearson correlation-based similarity)
用于表示两个变量之间的线性相关程度,它的取值在[-1, 1]之间。当两个变量的线性关系增强时,相关系数趋于1或-1;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0;如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。
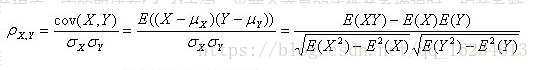
斯皮尔曼秩相关系数(SpearmanCorrelationSimilarity)
用来度量两个变量之间联系。

Tanimoto系数(TanimotoCoefficientSimilarity),又称广义杰卡德系数(Jaccardsimilarity coefficient)
Tanimoto Coefficient主要用于计算符号度量或布尔值度量的个体间的相似度,因为个体的特征属性都是由符号度量或者布尔值标识,因此无法衡量差异具体值的大小,只能获得“是否相同”这个结果。其值介于[0, 1]之间,如果两个用户关联的物品完全相同,交集等于并集,值为1;如果没有任何关联,交集为空,值为0。
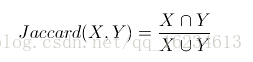
对数似然相似度(LogLikelihoodSimilarity)
主要应用于自然文本语言库中两个词的搭配关系问题。它是基于这样一种思想,即统计假设可以确定一个空间的很多子空间,而这个空间是被统计模型的位置参数所描述。似然比检验假设模型是已知的,但是模型的参数是未知的。


海明距离(Hamming distance)
在信息领域,两个长度相等的字符串的海明距离是在相同位置上不同的字符的个数,也就是将一个字符串替换成另一个字符串需要的替换的次数。
1011101与1001001之间的汉明距离是2。
2143896与2233796之间的汉明距离是3。
“toned”与“roses”之间的汉明距离是3。
深度度量学习(deep metric learning)
Center loss:
优化各个样本到其聚类中心的距离。
xi:第i张图片的特征值
cyi:该图片所属分类的中心(该分类的特征值的中心)
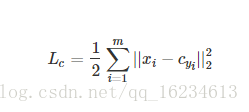
Contrastive embedding:
在 paired data (xi,xj,yij)上进行训练。 contrastive training 最小化具有相同 label 类别的样本之间的距离,然后对不同label的样本,其距离小于 α 的 negative pair 给予惩罚(距离大于α的被max(0,)置为0,可能觉得距离过大时,再优化没有意义,还会导致影响其他距离小的异类样本的优化)。每次优化只是在一对样本间。

Triplet embedding(Triplet Loss):
找一个 anchor,然后找一个正样本p,一个负样本n。训练的目的就是:鼓励网络找到一个 embedding 使得 anchor 和 negative 之间的距离大于 anchor 和 positive 加上一个 margin α 的和。相比Contrastive,其优化是在三个样本之间,彼此有了参照。
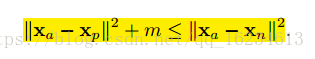

lifted structured feature embedding:
Contrastive 和 Triplet存在拟合速度慢,易陷入局部极小点问题。
Deep Metric Learning via Lifted Structured Feature Embedding
文章认为过去方法没有充分考虑一个mini-batch中存在的各个样本距离关系。因此提出考虑一个batch中所有样本距离,公式i,j表示相同label,N表示与其相异的样本集合。如下图,同样是6个样本lifted不仅考虑每个pair对关系,还考虑每个相异样本距离关系。

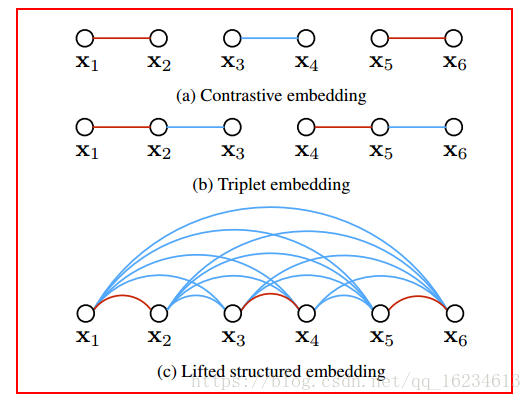
红色线条代表两个样本同label,蓝色表示相异。
但上述损失函数又两个问题:不够平滑;计算时同个pair重复计算了多次。


同时文章还引入难分样本挖掘思想:

Multi-class N-pair Loss Objective:
文章同样认为过去方法没有充分考虑一个mini-batch中存在的各个样本距离关系。并且在训练的末期,许多随机选择negative example由于和positive example距离太大,已经不能提供梯度信息了,因此需要使用mini negative。思想和前面的lifted非常像,就是一个特例。
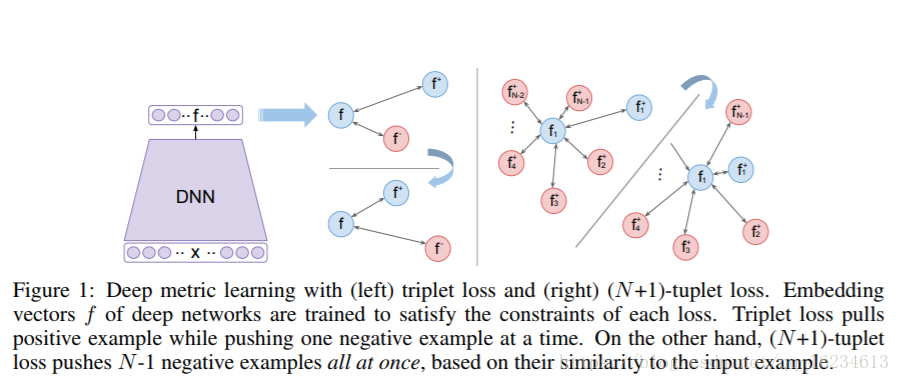

如果按照原本的N-pair方法采集样本,当类别很大时,模型将需要一次载入大量数据样本。因此作者重建了一种高效新的办法,只需要2N个不同类别样本,就形成原本的N-pair方法。

Hard negative class mining步骤:

regularize L2:

Angular Loss:
Deep Metric Learning with Angular Loss
从角度相似性方向考虑对triplet loss,增强了其尺度不变性,并且考虑了3阶几何约束。这篇文章的逻辑推理很nice。
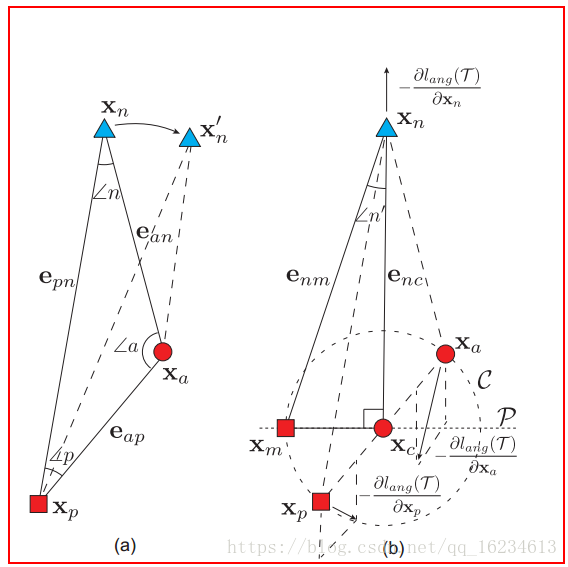
文章认为triplet loss的优化使得an的距离相比ap的距离变化程度更大,an距离的变大导致角n变小。如果从角度方向可以认为triplet loss的优化可以等效于优化角n。然而如果直接使用上式进行优化,会导致一些问题。如下图a,角n的减小导致xn移动到xn’,当这会减小an的距离,形成相反效果。
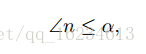
因此作者试图优化样本n和有样本p和a组成的样本分布的关系。通过样本p和a组成的圆,认为是样本分布区域,然后使用圆的中心和左点m重新构建三角关系。
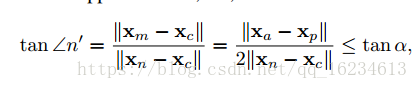
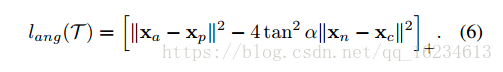
global loss functions:
Learning local image descriptors with deep siamese and triplet convolutional networks by minimising global loss functions

