SSD目标检测算法详解 (一)论文讲解
这一篇讲几个方面:
一、提要
二、论文详解:
(1) SSD算法的特点
(2) SSD算法总体结构
(3) 前馈神经网络——VGG
(4) 不同特征层的提取
(5) defalut box(预选框)的生成
(6) Loss 函数的计算(正负样本提取)
三、如何使用balance/SSD-tensorflow检测图片

—————————————正文分割线————————————
一、先扯淡:
最近导师给我发了几篇论文让我复现,前几篇识别分类(GoogleNet,Resnet之类的)还是比较好写的,但到了目标检测这里,faster-rcnn和SSD两篇前后写、训练、调参,总共用了将近两个月,所以目标检测还是比较难的。
因为自己是参考论文从头复现而非直接搬Github,也可以稍微大言不惭地说对SSD有了一定的了解。然后写完之后也试了一下Github上balance大佬的SSD-tensorflow,用的是300×300模型。文章会讲一下我自己写的SSD算法实现,然后也会讲一下如何直接去Github下载并调用balance大佬写的模型。
两个模型比较
这里先做一下比较:
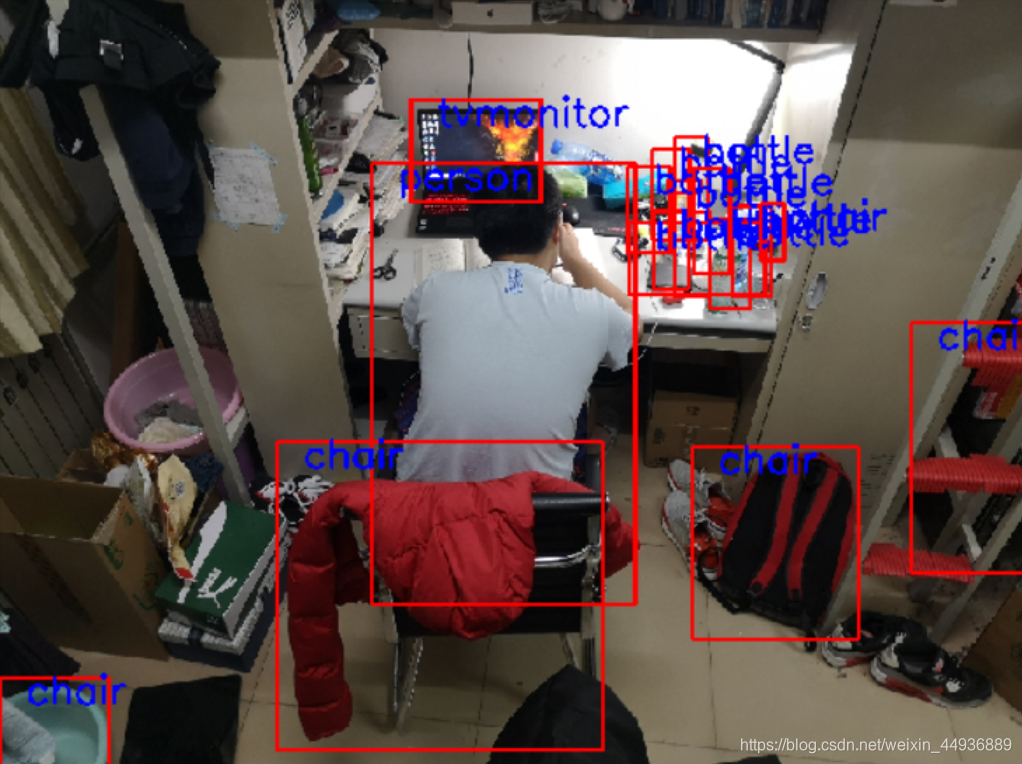
在宿舍随手拍了一张图(然后发现特征很多,干扰也很多,正好适合测试一下目标检测算法),然后第一张是balance大神的300×300的模型的结果,第二张是我自己从头搭建和训练的模型的结果。果然跟大佬的模型还是有很大差距,,,
分析
可以看到我们的模型对于小目标检测效果似乎更好一点(比如桌子上的一些bottles),对遮挡目标的检测也比较好(比如这个被衣服挡住的chair);
但是可能存在过拟合的现象,比如把左下角的盆当成了chair(盆:我冤枉啊!),也有把书包检测成chair的情况(书包:我也冤枉啊!)。
二、论文详解:
论文传送门:https://arxiv.org/abs/1512.02325
(1)SSD算法特点:

这里的Abstract提到了Faster-rcnn,即相比与Faster-rcnn复杂的网络结构(包括RNP网络和ROI-pooling层),SSD更加简单而且准确率更高,并实现了真正的端到端的训练;而相比于YOLO使用了全连接层只能接受固定的大小输入,SSD使用了全卷积层而摒弃了全连接层,使得其能够接受任意大小图片的输入,并产生相应大小的输出。
总结一下:
一、SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。
二、SSD采用了不同尺度和长宽比的先验框。
三、SSD实现了端到端的训练。
四、SSD能够接受不同大小的图片输入。
(2)SSD算法总体结构:

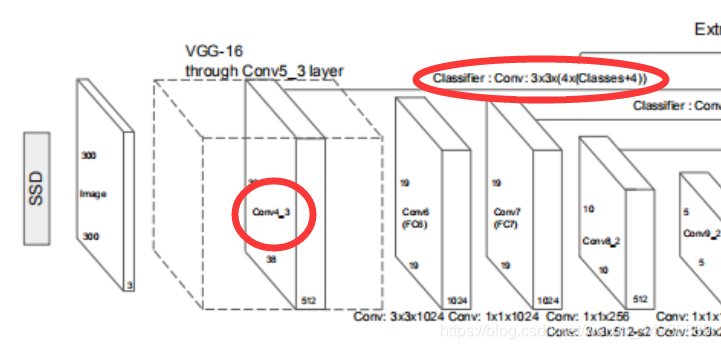
SSD算法的网络结构如图所示:
1、前馈神经网络:使用VGG(或者其他网络),摒弃了最后的全连接层;
2、在前馈神经网络后连接了多个卷积层,提供不同感受野的特征图;
3、在不同大小特征图上,生成不同大小和长宽比的default box,应对不同大小的目标;
4、通过对特征图进行卷积,生成每个default box对应的类别得分和预测坐标,每个点生成预测向量长度为(分类数+坐标数)×该点default box数;
5、最后通过非极大值抑制筛选出合适的预测框;
(3)前馈神经网络——VGG
我们这里使用VGG-16网络,结构如图: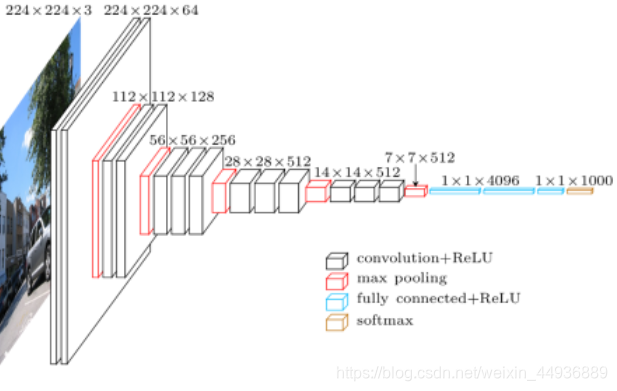
VGG结构: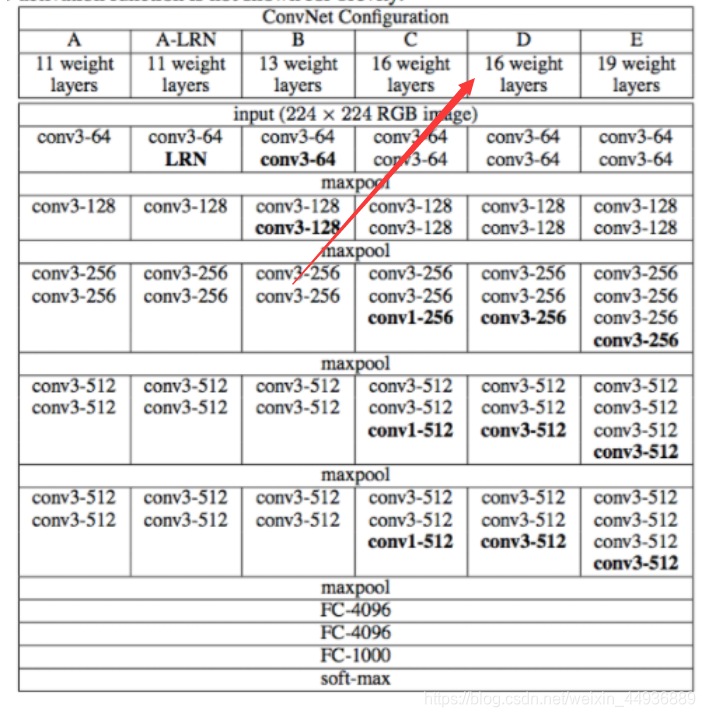
一个典型的VGG结构在卷积层之后,使用了一个步长为7的池化层和几个全连接层生成图像识别的类别得分;
当我们使用VGG作为前馈神经网络时,只需要取出前面的卷积层的输出,而不需要后面的全连接层;并在最后一层输出上加上额外的卷积层。
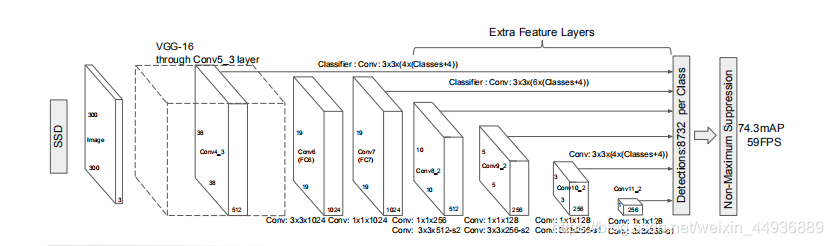
就像图片上标注的一样,从左到右依次是:
输入图片 ——> VGG-16的卷积层 ——> 6个额外的卷积层 ——> 总共7个(加上VGG的第4层)特征层对应default box的预测 ——> 非极大值抑制
每层具体卷积核大小和数目可以从VGG结构图和SSD结构图下方的标注看出;
(4)不同特征层的提取
正如我们所说,SSD相比于faster-rcnn最大的改进就是:SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。
提取出特征图,需要对其生成相应的default box(下面会讲一下生成方法),并通过卷积层生成每个特征点的预测;
我们以Conv4_3 为例:
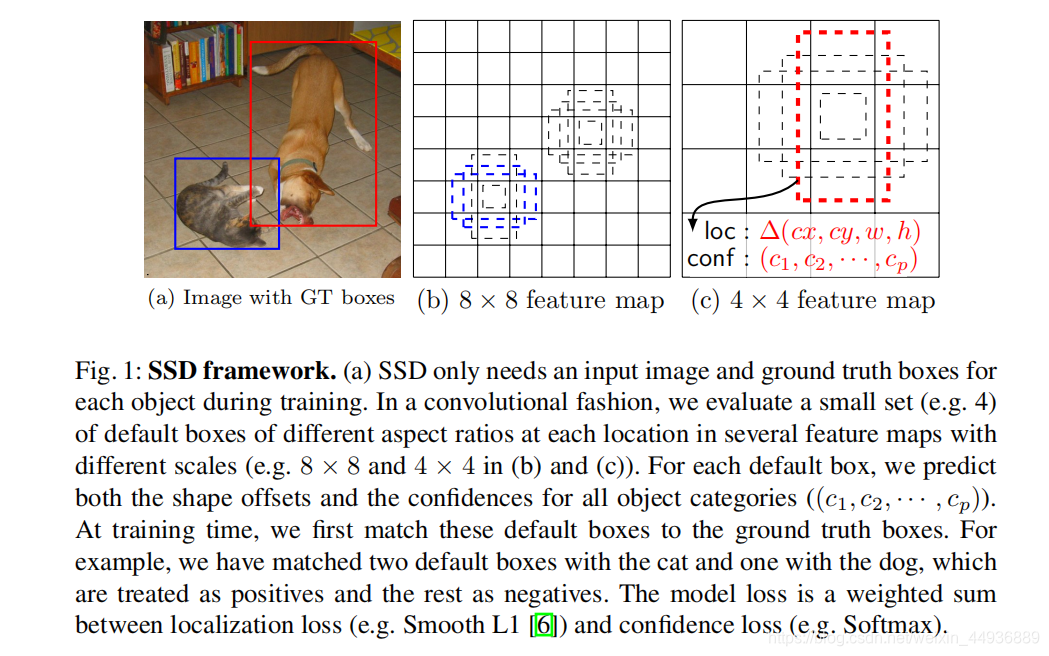
 先讲一下感受野的概念:
先讲一下感受野的概念:
感受野就是特征图上每个特征点对应原图的映射区域的大小;
以SSD_300为例,即输入图片大小为300×300。Conv4_3 前面共有三个步长为2的pooling池化层,感受野大小就是23等于8,我们就称步长为8,特征图大小为38×38×256,记为h×w×c;
这样特征图上h×w个特征点,在原图上就对应了h×w个区域;不同大小的特征层的特征点在原图上就对应不同大小,这样就可以实现对不同大小物体的检测。

圈出来的Classifier表示:在Conv4_3这层,预测使用了(3,3)大小的卷积核;4代表这一层每个特征点对应4个不同长宽比的defalut box;(Classes + 4)代表每个default box需要的预测值个数,包括(1+分类数目+回归坐标数4),额外的一个分类是背景得分(用于判定default box是否为背景或非背景)
(5)defalut box(预选框)的生成
原文中描述:
还是以Conv4_3为例:
Conv4_3 为第一个提取特征层,步长为8,则每个特征点对应区域为原图上相隔8像素的分立点,即Conv4_3上(0,0),(0,1),(0,2)等坐标点,在原图上对应的区域中心点为(0×8+4,0×8+4),(0×8+4,1×8+4),(0×8+4,2×8+4)等(×8中的8为步长,+4中的4为半步长),这样我们就得到了default box的中心坐标central_x,central_y;
对于default box边长的计算,可以参考论文给出的公式:
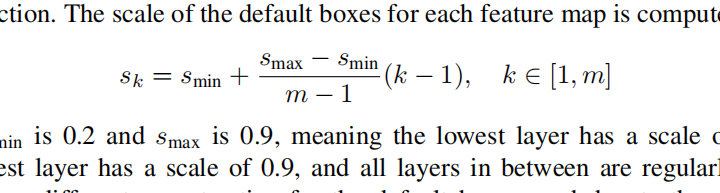
Sk 代表某一特征层对应default box的边长大小(边长÷原图最短边),Balance大佬对这个公式做了调整,我们直接用这个结果就ok:
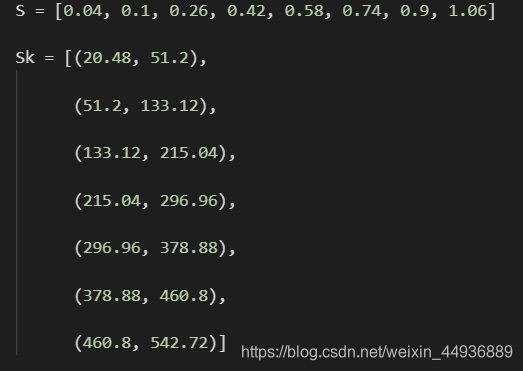
S是比率大小,Sk是对应的default box边长(第一个元素是这一层边长,第二个元素是下一层边长;
到这里每个特征点就相应生成了一个正方形default box,在原图上坐标为(central_y, central_x, height, width)。(注意:1.python中numpy矩阵第一维度是高度y轴,图片默认第一维度是x轴;2.这里的height, width大小和边长相等)
再对这个default box生成不同长宽比的default box;
不同层长宽比为:

对于Conv4_3我们可以看到有两个比率:2和1/2,在保持default box面积不变情况下改变长宽,这样又额外生成了两个default box;
欸,不是说这一层每个特征点有四个default box吗?
剩下一个还是一个正方形,边长为:
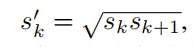
(这就是为什么我们的Sk中要保存下一层的default box的边长)
还要另外注意一点是,坐标回归值要做一下变换:
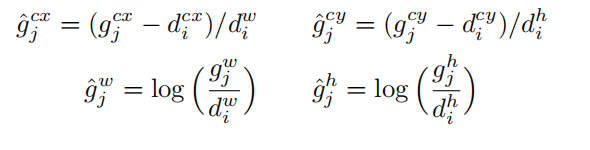
g表示真实坐标,d表示default坐标,g_hat可以理解为变换后的坐标,即我们卷积网络需要预测的值;
这样的话我们的每个特征点需要的预测值就出来啦:
每个特征点default box数:
【长宽比数+1】
预测值数:
【1(背景)+20(物体分类)+4(变换坐标)】×【长宽比数+1】
(6)Loss 函数的计算(正负样本提取)
我们将不同的default box进行分类,分为正样本(物体)和负样本(背景)。通过计算default box和true boxes(真值框)的IOU值,IOU>0.5的标注为正样本,则该default box的标签就是跟这个default box的IOU最大的真值框的标签;IOU<0.5的标注为负样本,由于我们的分类向量有一个背景得分,故负样本可以参与类别的loss计算,但不参与坐标回归的loss计算。
IOU描述两个坐标框的重叠程度,计算公式如图:
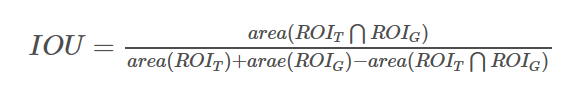
当然,由于default box绝大部分是负样本,如果对所有default box进行梯度下降,可能导致模型难以收敛;
故我们选取所有的正样本,然后按照正、负样本比为 1 :3 的比例选取IOU得分最小的负样本参与Loss计算,其余default box的Loss记为0。(其中分类Loss使用交叉熵Loss,坐标回归Loss使用SmoothL1)
三、如何使用balance/SSD-tensorflow检测图片
这里就不多介绍Balance大佬的源码了(下一期会详细介绍一个简洁但是效果一样好的版本),这里先只放一下使用方法:
通过调用 demo_test.py, 在程序内标注的地方传入图片即可~
效果如图:

源码传送门:https://pan.baidu.com/s/18bw1nfgV62qnS5nybnqYMA
提取码:y9ka
(百度云不是很快呀,,,也可以留下你的邮箱地址哦)

{kind=link}