前一篇文章 Java 8 之 Stream 的创建 对 Stream 特性以及如何创建 Stream 做了说明,这篇文章对 Stream 的操作符(方法) 进行探讨。
filter
Stream 的 filter() 方法执行过滤操作
Stream<T> filter(Predicate<? super T> predicate);filter() 方法使用的是 Predicate 的函数接口,用一个图可以很容易理解 Predicate 函数接口所表达的意思
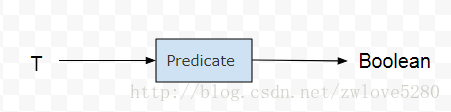
在转换为 Lambda 表达式之前,必须对函数接口比较熟悉,知道这个函数接口表示什么行为,从图中可以看出,
Predicate 函数接口用 T 类对象作为参数,返回一个 Boolean 对象用作判断标准。
有了这层理解后,转化为 Lambda 表达式就比较容易理解了
Stream.of(1, 4, 6).filter(aInteger -> aInteger > 3);Lambda 表达式 aInteger -> aInteger > 3 的意思是说,取 Stream 中的元素 aInteger,给出判断标准是 aInteger > 3,然后用 filter() 方法进行过滤。
map
Stream 的 map() 方法,简单的说就是把一种类型的流,转换为另外一种类型的流
<R> Stream<R> map(Function<? super T, ? extends R> mapper);map() 方法使用的是 Function 函数接口,还是用一个图来理解 Function 函数接口
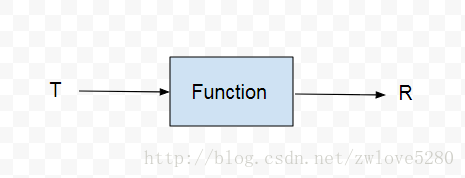
图中很清晰的表达了,把 Function 函数接口把类型 T 转换为 类型 R
Stream<Integer> integerStream = Stream.of(1, 2, 3);
Stream<String> stringStream = integerStream.map(String::valueOf);从例子可以看出,map 操作符把 Stream< Integer> 转化为 Stream< String> 。
这个例子中, String::valueOf 是方法引用,等价
的Lambda 表达式为 aInteger -> String.valueOf(aInteger).
mapToInt, mapToLong, mapToDouble
IntStream mapToInt(ToIntFunction<? super T> mapper);
LongStream mapToLong(ToLongFunction<? super T> mapper);
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);Java 的基本类型,都有对应的包装类型,例如 int 对应 Integer。然而对于泛型,只能操作包装类型,例如 Integer。然而包装类型对象相比于基本类型内存开销要大的。
如果需要,Java 会自动在包装类型对象和基本类型对象之间转换,然而这个转换也是有开销的。
从这两点看,这显然减缓程序的运行速度,所以 Java 8 用 IntStream, DoubleStream, LongStream 以 Stream 的形式,底层来操作基本类型,从而减少这些开销。 我把这三个 Stream 称之为 三大基本类型 Stream。
Java 有 8 中基本类型,然而 Java 8 中却只有对应的三种基本 Stream。
用 IntStream 举例
Stream<Integer> integerStream = Stream.of(1, 2, 3);
IntStream intStream = integerStream.mapToInt(integer -> integer);其实这2行代码可以用函数式风格链式调用,我这里是为了方便观察,所以写成了2行。
那么,现在可以直接操作基本类型 Stream,也就没有那些转换和内存的额外开销了。IntStream 接口虽然不是直接继承 Stream 接口,但是 IntStream 也有与 Stream 中对等的操作,例如 filter(), map()。
既然都把 IntStream 设计出来了,当然也要为它封装一些常用的操作,例如求和 sum(),求最大值 max(),求最小值 min(),计数 count(),
例如
OptionalInt min = Stream.of(1, 2, 3)
.mapToInt(integer -> integer)
.min();Optional
前面例子中代码返回了 OptionalInt,它和 Optional 原理是一样的。
Optional 是一个容器,它可以包含或者不包含一个值,如果值存在,isPresent() 就返回 true,get() 就返回包含的值。Optional 就是对一个值进行一次包装,好像就是为了对付空指针异常设计的,使用方法如下。
if (optionalInt.isPresent()) {
int min = optionalInt.getAsInt();
}针对包含的值是否存在,Optional 类有一系列的操作符。
orElse(T other) 会返回一个默认值,如果值不存在,更有甚者 orElseGet(Supplier< ? extends T> other),当值不存在的时候,执行一个操作来返回一个默认值。
ifPresent(Consumer
Stream.of(1, 2, 3)
.mapToInt(integer -> integer)
.min()
.ifPresent(System.out::println); IntSummaryStatistics
再回到 IntStream 话题,IntStream 还有个 summaryStatistics() 方法,这个方法返回一个 IntSummaryStatistics 对象,它用来统计
数据的,例如 计数 getCount(),求和 getSum(),求最大和最小值 getMax()/getMin(),更甚者,返回平均值 getAverage()。
你可能发现了 IntStream 与 IntSummaryStatistics 有重复功能的方法,为什么重复设计?
- IntStream 的 min() 返回值是 OptionalInt, 需要检查返回值是否为 null,而 IntSummaryStatistics 的 getMin() 方法返回的是基本类型 Int,自动过滤了 null 值,因此后者更快。
- 上篇文章对 Stream 讲解的时候说到,Stream 的一次性特性,
一个 Stream 只能被一个操作符操作,而且只能操作一次。 如果不把 IntStream 转换为 IntSummaryStatistics, 如果想既求出最大值也求出最小值,那就不行了。因此用统计的数据的角度看,后者也更胜一筹,个人觉得这也是主要原因吧。
另外,IntSummaryStatistics 还有添加数据的方法, accept() 和 combine(IntSummaryStatistics other) 方法
IntSummaryStatistics intSummaryStatistics = Stream.of(1, 2, 3)
.mapToInt(integer -> integer)
.summaryStatistics();
intSummaryStatistics.accept(888);
int max = intSummaryStatistics.getMax();max 的值获取到的为 888.
combine(IntSummaryStatistics other) 方法,用来合并另外一个 IntSummaryStatistics
那么总结下,IntSummaryStatistics 是用来方便数据统计的,可以向其中加入数据(accept()/combine()), 并且可以重复地对数据进行一些常用操作(求平均值,最大值等等)。
flatMap
Stream 的 flatMap() 方法,从返回值看,就是把 Stream< T> 转换为 Stream< R>,但是 flatMap() 调用的函数接口 Function ,是把类型 T 转换为 Stream < R> ,这点是需要注意的。
Person user1 = new Person().setName("user1").setAge(18).setWhere("GuangDong", "ShenZhen");
Person user2 = new Person().setName("user2").setAge(28).setWhere("HuBei", "WuHan");
Stream<Person> userStream = Stream.of(user1, user2);
Stream<String> stringStream = userStream
.flatMap(Person::getFromWhere);
public Stream<String> getFromWhere() {
return fromWhere.stream();
} Lambda 表达式 Person::getFromWhere 其实是把 Stream< Person> 转换为了 Stream< Stream< String>>,而 flatMap() 最终就把 Stream< Stream< String>> 转换为 Stream< String>。
理解起来确实有点别扭,但是你只要知道过程以及最终结果是什么样的就行,其实原理不太需要深究。
flatMapToInt, flatMapToLong, flatMapToDouble
以 flatMapToInt 为例
IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper);从返回值以及参数可以猜测,flatMapToInt 就是 flatMap() 和 mapToInt() 的结合版。
IntStream intStream = Stream.of(user1, user2)
.flatMapToInt(person -> IntStream.of(person.getAge()));猜一下过程,先把 Stream< Person> 转换为 Stream< IntStream> ,然后用 flatMapToInt 把 Stream< IntStream> 转换为 IntStream。
forEach, forEachOrdered
void forEach(Consumer<? super T> action);
void forEachOrdered(Consumer<? super T> action);这2个方法都是为 Stream 中的每个元素执行一次动作(参数action)。然而从命名看就知道这2个方法有点小小的区别:
- forEach():对于并行的流,并不能保证流中元素的顺序,如果保证了顺序就会牺牲掉并行所带来的好处。对于任意一个元素,它的 action 可能会在任意时间,任意线程中执行,这是由库选择的。如果 action 要访问一个共享状态,这个方法需要提供了同步机制。
- forEachOrdered():按照 Stream 中元素的顺序执行 action,也就是说同一时间只有一个 action 在进行,但是这个 action 可能在任意线程中执行,这也是由库选择的。
Stream.of(user1, user2)
.parallel()
.forEach(person -> {
System.out.println(Thread.currentThread().getName());
System.out.println(person);
});看下 Log
System.out: main
System.out: Person{name='user2', age=28, fromWhere='null'}
System.out: ForkJoinPool.commonPool-worker-1
System.out: Person{name='user1', age=18, fromWhere='null'}
从 Log 中可以看出,forEach() 并没有保证并行 Stream 的元素顺序,而且执行代码的先成也不一样。
distinct
Stream<T> distinct();从名字可以猜测出,distinct() 方法作用是去掉重复的元素。
Stream.of("a", "b", "a", "c")
.distinct()
.forEach(System.out::print); 结果为
System.out: a
System.out: b
System.out: csorted
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);2个方法都是对 Stream 中的元素进行排序,sorted() 使用的是自然排序,而 sorted(comparator) 需要给定一个排序标准。
先看看 Java 8 之前如何比较两个对象
Stream.of(user1, user2, user3)
.sorted((person1, person2) -> person2.getAge() - person1.getAge())
.forEach(person -> System.out.println(person.getName()));这个例子中,comparator 是用匿名内部类的方式创建的,但是这种方式很难理解(尤其对新手,例如曾经的我),这个 Lambda 表达式 ((person1, person2) -> person2.getAge() - person1.getAge()) 用 person1 和 person2 作为参数,然后用 person2.getAge() - person1.getAge() 给出判断标准,然而这个标准确是很模糊。
Java 8 中给函数接口 Comparator 创建一个 default 方法 comparing 方法
static default <T, U extends Comparable<? super U>> Comparator<T> comparing(Function<? super T, ? extends U> keyExtractor) {
// ...
}这个方法很长,看看例子
Stream.of(user1, user2, user3)
.sorted(Comparator.comparing(Person::getAge))
.forEach(person -> System.out.println(person.getName()));Comparator.comparing(Person::getAge) 这个 Lambda 表达式可以这样理解,它创建了一个标准,这个标准就是来比较 Person 的 Age,sorted() 方法用这个标准来排序。
这样理解起来就 so easy!
peek
Stream<T> peek(Consumer<? super T> action);peek() 方法在 Collection 类中是获取队首的元素( 但不移除 ),而在 Stream 中,也获取了从 Up Stream 中元素,但是也额外在这个元素上用 action() 方法做了一些操作,
例如,最常用的操作就是打打 Log。
Stream<Person> peek = Stream.of(user1, user2, user3)
.peek(System.out::println);从 Stream 的 peek() 方法返回值看,peek() 方法是一个过渡操作符,并且没有改变 Stream 的泛型,因此很适合来 Debug。
另外,peek() 也可以用于并行 Stream,和 forEach() 一样,action 操作的时间和线程都是不由自己的。并且如果想访问共享状态,需要自己加同步代码。
limit
Stream<T> limit(long maxSize);limit() 方法从返回值看,这是一个过渡操作符,并且限制 Up Stream 发送元素的个数不大于 maxSize。
例如,用上篇文章中用到的 Stream 的创建方法 generate() 来生成无限元素的 Stream,然后用 limit() 限制 Up Stream 的发送元素的个数
long count = Stream.generate(() -> new Random().nextBoolean())
.limit(5)
.peek(System.out::println)
.count();可以从 Log 中看到打印的元素的值,并且最终也可以从 count() 方法的返回值中确定最终 Stream 中元素的个数。
如果 limit() 在顺序 Stream 上工作,非常容易。
如果在一个并行且有序的流上操作,并且随着 Stream 的体积越来越大,开销就比较大了,这是因为 limit() 并不是返回任意的 n 个元素,而是前 n 个元素,这 n 个元素就是并行有序流的前 n 个元素。
所以,如果在并行 Stream 上,为了提高 limit() 性能,如果可以,就用 unordered() 移除 Stream 的顺序,否则就用 sequential() 把并行 Stream 转换为顺序 Stream。
skip
Stream<T> skip(long n);skip() 方法,很简单,跳过前 n 个元素,这个方法也是一个过渡方法。
skip() 与 limit() 一样,在遇到并行且有序的 Stream 的时候,是有开销的,Stream 越大开销越大。
toArray
Object[] toArray();
<A> A[] toArray(IntFunction<A[]> generator);这2个函数都是把 Stream 转换为数组 。Java 中泛型是基于对泛型的擦除,所以转换为 Object[] 是完全可以的。
而第二个函数是用 IntFunction 函数接口,把 Stream 转换为特定类型的数组,也就是说返回的数组的大小与 Stream 中元素个数是一样的。
Person[] persons = Stream.of(user1, user2, user3)
.toArray(new IntFunction<Person[]>() {
@Override
public Person[] apply(int i) {
return new Person[i];
}
});IntFunction 函数接口返回了一个大小为 i 的 Person 数组,这个 i 表示的是 Stream 中元素的个数。
现在用 Lambda 表达式以及方法引用来重构下代码
Person[] persons = Stream.of(user1, user2, user3)
.toArray(Person[]::new);match
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate);这三个方法都是对 Stream 中的元素执行判断,返回 Boolean 值,但是这三个方法对于 Empty Stream 是由区别的。
anyMatch() :如果 Stream 是空 (empty) 的,返回 false,并且 predicate 不会执行。
allMatch(), noneMatch:如果 Stream 是空 (empty) 的,返回 true,并且 predicate 不会执行。
boolean b = Stream.empty().noneMatch(o -> false); // truefind
Optional<T> findFirst();
Optional<T> findAny();findFirst() 获取 Steam 中第一个元素,如果 Stream 是无序的,这第一个元素就不确定。
findAny() 就更随意,获取任意一个元素。
Stream.of(user1, user2, user3)
.findFirst()
.ifPresent(System.out::println); // user1min, max
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);根据 Comparator 提供的标准,来返回 Stream 中的最大值和最小值。
Optional<Person> maxPerson = Stream.of(user1, user2, user3).max(Comparator.comparing(Person::getAge));在 Stream 的 sorted() 方法中已经提到过 Comparator 和 Optional 在 Java 8 中的作用和用法。
count
long count(); 返回 Stream 中元素的个数。
reduce
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);先抛开这些方法,看看 reduction 模式,假如现在要对几个 int 值求和,可以设计如下方法
private int sum(List<Integer> integers) {
int result = 0;
for (Integer integer : integers) {
result = result + integer;
}
return result;
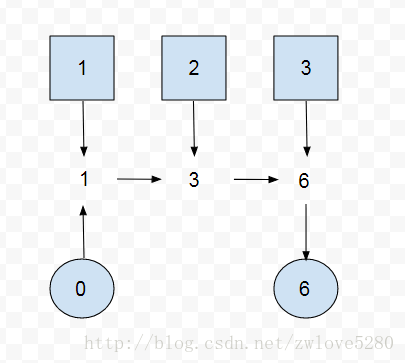
}原理就是给定一个初始结果,然后累计求和,那么可以把这个代码模式化
T result = identity;
for (T element : this stream)
result = accumulator.apply(result, element)
return result;这个模式就是 reduction 模式,也就是对应 reduce 方法中的第一个方法
T reduce(T identity, BinaryOperator<T> accumulator);用一个图表示就是
Reduction 模式也可以不要初始值,那么就对应 reduce 方法的第二个方法
Optional<T> reduce(BinaryOperator<T> accumulator);注意,如果没有给初始值,返回值是 Optional ,因为可能为 null。 而给定了初始值的,就已经确定返回值不为 null,所以不用返回 Optional.
现在把 sum() 方法用 reduce 方法重构
Optional<Integer> sum = Stream.of(user1, user2, user3)
.map(Person::getAge)
.reduce((age1, age2) -> age1 + age2);ok, 现在看看三个参数的 reduce() 方法
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);这个 combiner 参数是特意为并行 Stream 准备的,如果不是并行 Stream,第三个参数无效,例如
Integer sum = Stream.of(1, 2, 3)
.reduce(100,
(result, integer) -> {
System.out.println("in accumulator, result = "
+ result + ", integer = " + integer);
return result + integer;
},
(result1, result2) -> {
System.out.println("in combiner, result1 = "
+ result1 + ", result2 = " + result2);
return result1 + result2;
});
System.out.println(sum);Stream.of(1,2,3) 是顺序执行的 Stream,虽然是为了求 1+2+3 的和,但是我这里为了更好的看出执行过程,把初始值设置为 100,这就等于是 100 + 1 + 2 + 3 = 106。 执行这个程序后会有如下 Log
System.out: in accumulator, result = 100, integer = 1
System.out: in accumulator, result = 101, integer = 2
System.out: in accumulator, result = 103, integer = 3
System.out: 106Log 中 result 代表累加的结果,初始的时候,result 等于设置的初始值 100, 然后累加第一个元素 1, result 就变为 101, 之后累加第二个元素 2, result 变为 103,最后累加第三个元素 3, result 的值其实已经变为 106, 也就是最终的返回值。
从 Log 中注意到一个问题,第二个 Lambda 表达式并没有执行,那么现在把 Stream 改为并行流,再看看
Integer sum = Stream.of(1, 2, 3)
.parallel() // 改为并行流
.reduce(100,
(result, integer) -> {
System.out.println("in accumulator, result = "
+ result + ", integer = " + integer);
return result + integer;
},
(result1, result2) -> {
System.out.println("in combiner, result1 = "
+ result1 + ", result2 = " + result2);
return result1 + result2;
});
System.out.println(sum);运行后 Log 如下
System.out: in accumulator, result = 100, integer = 2
System.out: in accumulator, result = 100, integer = 3
System.out: in accumulator, result = 100, integer = 1
System.out: in combiner, result1 = 102, result2 = 103
System.out: in combiner, result1 = 101, result2 = 205
System.out: 306首先可以看到第二个 Lambda 表达式在并行的 Stream 中执行了,但是最终结果为 306, 这个结果和之前顺序执行的 Stream 的结果差距太大了? 问题出在哪里呢? 为了探究问题的根源,首先需要知道执行的过程。
首先看 Log 的前三行,这是在 accumulator (第一个 Lambda 表达) 中执行的,result 始终为 100,也就是一直是初始值( 并行执行关键点 )。经过前三个 Log 后,其实生成了 102, 103, 101, 注意并不是 101,102,103, 这显然是并行执行导致的。
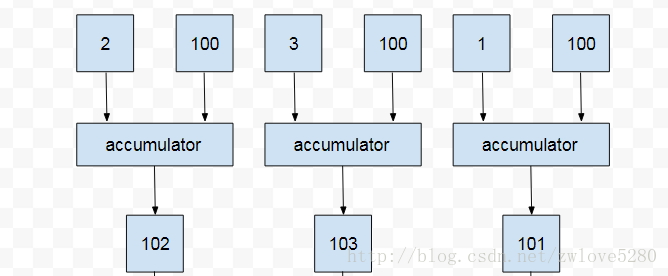
第四行和第五行的 Log 在 combiner(第二个 Lambda 表达式) 中是如何执行的呢? 现在已经有了 102,103,101 的并行执行结果,
第四行 Log 是把 102 和 103 求和,得出 205, 然后在第五行,用 103 再加上计算出的 205,也就是最终结果 306.
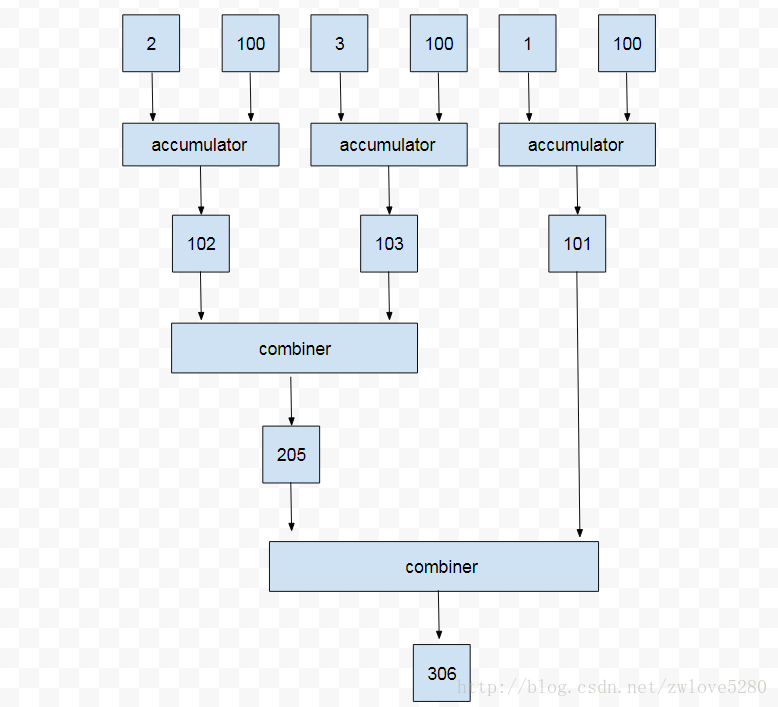
那么,并行 Stream 和 顺序 Stream 的差异结果原因就在于初始值,这里设置为了 100,如果设置为 0,那么结果就是相同的。
也就是说只要初始值并不影响最终结果,那么并行 Stream 和 顺序 Stream 执行结果是相同的,只是效率不同而已。这个结论同样适用于一个参数和两个参数的 reduce() 方法。
官方给出这个初始值 identity 应该满足的条件为
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)collect
<R, A> R collect(Collector<? super T, A, R> collector);
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);有时候希望把 Stream 转换为集合(Collection), 例如 List,Set,或者转换为 Map,或者分组等等,Java 8 把这些操作的模式抽象出来,封装到收集器(Collector)中。
一个参数的 collect() 方法就是提供一个 Collector 对象, 而三个参数的 collect() 方法就是提供一个简易实现版的 Collector.
转换成集合
先看看第一个方法的用途
<R, A> R collect(Collector<? super T, A, R> collector);这个方法是提供一个 Collector 接口对象,通常并不会直接创建匿名内部类对象,而是用 Collectors 的静态方法来创建。
public static <T>
Collector<T, ?, List<T>> toList() {
// ...
}
public static <T>
Collector<T, ?, Set<T>> toSet() {
// ...
}
public static <T, C extends Collection<T>>
Collector<T, ?, C> toCollection(Supplier<C> collectionFactory) {
// ...
}例如, 把 Stream 转换为 List
List<Integer> list = Stream.of(1, 2, 3).collect(Collectors.toList());转换为 Set
Set<Integer> set = Stream.of(1, 2, 3).collect(Collectors.toSet());或者转换为集合(Collection)的具体子类,例如转换为一个 Queue
LinkedList<Integer> queue = Stream.of(1, 2, 3).collect(Collectors.toCollection(LinkedList::new));转化为 Map
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
// ...
}
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction) {
// ...
}
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
// ...
}
例如,我想把 Stream 转换为一个 name, age 映射关系的 map
Map<String, Integer> nameAges = Stream.of(user1, user2, user3)
.collect(Collectors.toMap(Person::getName, Person::getAge));Map 的 key 值是不能重复的,而如果上面例子中,Person 的 name 有重复的,就会报异常
java.lang.IllegalStateException: Duplicate key那么,toMap() 的第三个参数 mergeFunction 就是对同一个key值的多个value进行处理
Map<String, String> map = Stream.of(user1, user2, user3)
.collect(Collectors.toMap(Person::getName,
Person::getPhoneNumber,
(number1, number2) -> number1 + "," + number2));相同的 name,对应多个电话号码,多个电话号码之间用逗号隔开。
在前面说到,可以用 Collectors.toCollection() 把 Stream 转换为任意的集合子类,例如 HashSet, LinkedList。那么 toMap 也可以做到,这就是第四个参数的作用,用来自己提供一个 Map 的具体子类。
HashMap<String, String> treeMap = Stream.of(user1, user2, user3)
.collect(Collectors.toMap(Person::getName,
Person::getPhoneNumber,
(number1, number2) -> number1 + "," + number2,
HashMap::new));为了方便快速查询,转换为 HashMap。
然而,Collectors.tomap() 返回的 Collector 对象,不是并发的。 对于并行流(parallel stream), 函数 combiner 需要把 key 值从一个 map 合并到另外一个 map,这个过程开销比较大。因此,如果不需要以流的顺序 (encounter order)来把元素插入到 map 中,可以使用 Collectors.toConcurrentMap() 来提升性能。
Collectors.toConcurrentMap() 的参数与 Collectors.toMap() 一样, 只是toConcurrentMap() 返回的是一个并发的 Collector 对象。
Collectors 还有一个名字与 map 有关的方法,叫做 mapping
public static <T, U, A, R>
Collector<T, ?, R> mapping(Function<? super T, ? extends U> mapper,
Collector<? super U, A, R> downstream) {
// ...
}但是这个 mapping() 方法,真正的用法是把一个 Collector 转化为另外一个 Collector(第二个参数 downstream).
List<String> list = Stream.of(user1, user2, user3)
.collect(Collectors.mapping(Person::getName, Collectors.toList()));这里返回的是 name 的 list
再举个例子
long count = Stream.of(user1, user2, user3)
.collect(Collectors.mapping(Person::getName, Collectors.counting()));这里返回了 name 的数量。
从实际的效果看,这个方法可以用 map-collect 组合代替,例如
List<String> names = Stream.of(user1, user2, user3)
.map(Person::getName)
.collect(Collectors.toList());那么这个岂不是重复了? 虽然功能是重复了,但是这个 mapping() 返回的 Collector 是用于组合其他 Collector,在后面例子中会看到。
转换成一个值
Collectors 还有和 Steram 一样求单一值的方法,例如, 最大/小值(maxBy()/minBy()), 计数(counting()),
求和(summingInt()/summingLong()/summingDouble()), 求平均数(averagingInt()/averagingLong()/averagingDouble)
Optional<Person> min = Stream.of(user1, user2).collect(Collectors.minBy(Comparator.comparing(Person::getAge)));
Double average = Stream.of(user1, user2).collect(Collectors.averagingInt(Person::getAge));数据分块
Collectors 的 partitioningBy() 可以将 Stream 分块
public static <T, K> Collector<T, ?, Map<K, List<T>>>
groupingBy(Function<? super T, ? extends K> classifier) {
// ...
}
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream) {
// ...
}例如,使用一个参数的 partitioningBy() 方法
Map<Boolean, List<Person>> map = Stream.of(user1, user2, user3)
.collect(Collectors.partitioningBy(person -> person.getAge() > 20));可以看到,返回值类型是 Map,其中 key 的类型为 Boolean, value 类型为 List。
也就是说,如果 Person 的 Age 大于/小于 20 岁,key 就为 true/false,然后把这个 Person 加入到 value(类型为List) 中。
然而,有时候这个数据分块太僵硬了,我需要把 List 转化为名字的集合,那么可以使用两个参数的 groupingBy() 方法,第二个参数会再创建一个 Collector,并对 List 的 Stream 做 collect() 操作
Map<Boolean, Set<String>> map = Stream.of(user1, user2, user3)
.collect(Collectors.partitioningBy(person -> person.getAge() > 20,
Collectors.mapping(Person::getName, Collectors.toSet())));现在返回的 Map 中的 value 是 Set,名字的集合,因此并没有重复的名字。
前面说过 Collectors.mapping() 是用来组合其他的 Collector 的,这里就可以看到它的强大之处。如果我们换做其他方式来实现这个组合 Collector 效果,是不是有点难?
数据分组
public static <T, K> Collector<T, ?, Map<K, List<T>>>
groupingBy(Function<? super T, ? extends K> classifier) {
// ...
}
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream) {
// ...
}
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream) {
//...
}
数据分块是以符合某个标准(Boolean值)来分块,而数据分组是以某个参照对象来分组,可以用 Collectors 的 groupingBy() 方法
Map<Integer, List<Person>> group = Stream.of(user1, user2)
.collect(Collectors.groupingBy(Person::getAge));例子中,以年龄来分组,可以注意到返回值为 Map,key 为 Integer 类型,也就是 Person 的 Age 类型,value 为 List 类型,也就是年龄相同的 Person 的集合。
与 partitioningBy() 类似,groupingBy() 的第二个参数也是一个 Collector,用法也是一样的,转换 Map 的 Value 的类型
Map<Integer, Long> ageCountParis = Stream.of(user1, user2, user3)
.collect(Collectors.groupingBy(Person::getAge, Collectors.counting()));这次,利用第二个参数把 Map 的 Value 类型从 List 转换为 Long,这个返回结果代表年龄和人数的映射关系。
无论是一个参数的还是两个参数的 groupingBy() 返回的都是 Map 接口 , 如果我返回 Map 接口的具体实现类呢, 例如 HashMap, 那就用三个参数的 groupingBy() 方法的第二个参数来创建一个 HashMap
HashMap<Integer, Set<Person>> collect = Stream.of(user1, user2, user3)
.collect(Collectors.groupingBy(Person::getAge, HashMap::new, Collectors.toSet()));字符串链接
public static Collector<CharSequence, ?, String> joining() {
// ...
}
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter) {
// ...
}
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {
// ...
} 这三个方法非常简单,从参数名字就可以猜出是什么意思了
String str1 = Stream.of("a", "b", "c", "d").collect(Collectors.joining()); // abcd
String str2 = Stream.of("a", "b", "c", "d").collect(Collectors.joining(",")); // a,b,c,d
String str3 = Stream.of("a", "b", "c", "d").collect(Collectors.joining(",")); // [a,b,c,d]reducing
public static <T> Collector<T, ?, T>
reducing(T identity, BinaryOperator<T> op) {}
public static <T> Collector<T, ?, Optional<T>>
reducing(BinaryOperator<T> op) {}
public static <T, U>
Collector<T, ?, U> reducing(U identity,
Function<? super T, ? extends U> mapper,
BinaryOperator<U> op) {} Colletors 的一个和两个参数的 reducing() 与 Stream 的 reduce() 方法一样,那么看下三个参数的方法。
三个参数的 reducing() 的第二个参数 mapper 的作用是在操作之前对元素进行转换
Integer sumOfAge = Stream.of(user1, user2, user3)
.collect(Collectors.reducing(0, Person::getAge, Integer::sum));例子中,用 Person::getAge 对元素 person 进行了转换,最后求出三个 Person 的年龄的总和。然而这个却可以用 Stream 的 map-reduce 方法取代。
Collectors.reducing() 和 Collectors.mapping() 方法一样,是用来组合其他 Collector 的,尤其是在组合 Collectors.groupingBy() 和 Collectors.partitioningBy()
Map<Person.Sex, Integer> collect = Stream.of(user1, user2, user3)
.collect(Collectors.groupingBy(Person::getSex,
Collectors.reducing(0, Person::getAge, Integer::sum)));这里用 Collectors.reducing() 组合了 Collectors.groupingBy() ,最后结果显示了男性和女性的年龄和。
自定义 Collector
Stream 的三个参数的 Collect() 方法就是使用自定义的 Collector
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);我并不是打算去深究自定义 Collector 实现,因为有些细节我也没搞清楚,不过在这里通过 Collect() 方法来看看简易版的 Collector 的实现。
从 collect() 方法的返回值的 R 类型, 第一个参数 supplier 是提供一个容器(container)来保存结果 R 的对象的,例如
Supplier supplier = new Supplier<ArrayList>() {
@Override
public ArrayList get() {
return new ArrayList();
}
};第二个参数 accumulator,是把 Stream 的每一个元素添加到 supplier 创建出来的容器中,例如
BiConsumer accumulator = new BiConsumer<ArrayList, Person>() {
@Override
public void accept(ArrayList arrayList, Person person) {
arrayList.add(person);
}
};第三个参数 combiner 与 Stream 的 reduce() 方法一样,是用于并行流的,用于合并并行执行的结果
BiConsumer combiner = new BiConsumer<ArrayList, ArrayList>() {
@Override
public void accept(ArrayList arrayList, ArrayList arrayList2) {
arrayList.add(arrayList2);
}
};那么现在就可以自己来写一个 Collectors.toList() 方法
ArrayList<Person> persons = Stream.of(user1, user2, user3)
.collect(ArrayList::new, ArrayList::add, ArrayList::addAll);可以在 combiner 中加上 Log 来验证第三个参数只有在并行流中有效,跟我前面讲 Stream 的 reduce() 方法一样。
