存储过程
- 一组可编程的函数,是为了完成特定功能的SQL语句集
- 存储过程就是具有名字的一段代码,用来完成一个特定的功能
- 创建的存储过程保存在数据库的数据字典中
1 为什么要使用存储过程
- 将重复性很高的一些操作,封装到一个存储过程中,简化了对这些SQL的调用
- 批量处理
- 统一接口,确保数据的安全
- 相对于oracle数据库来说,mysql的存储过程相对功能较弱,使用较少
2 存储过程的创建和调用
- delimiter $$
设置当遇到$$时才执行语句
delimiter $$
select * from emp$$
(1) 它与存储过程语法无关
(2) delimiter语句将标准分隔符 ——分号(;)更改为:%%
(3) 因为我们想将存储过程作为整体传递给服务器,而不是让mysql工具一次解释每个语句
创建存储过程
delimiter $$ -- 定义分隔符
create procedure show_emp() -- 创建存储过程
begin
select * from emp;
end$$ -- 结束
delimiter ; -- 再定义分隔符
调用存储过程(创建了就会自动存储在数据字典中,用的时候再调用)
call show_emp();
3 查看存储过程
- 查看所有存储过程
show procedure status;
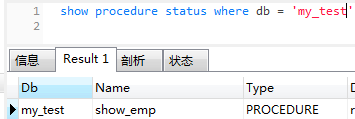
- 查看指定数据库中的存储过程
show procedure status where db = 'my_test';
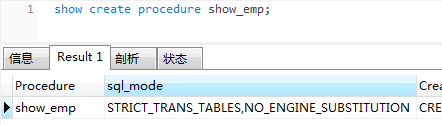
- 查看指定存储过程源代码
show create procedure show_emp;
4 删除指定存储过程
drop procedure show_emp;
5 存储过程变量
- 在存储过程中声明一个变量
declare 变量名 数据类型(大小) default 默认值;
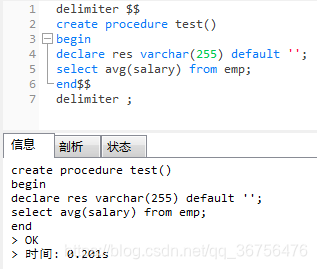
delimiter $$
create procedure test()
begin
-- 声明变量
declare res varchar(255) default '';
select avg(salary) from emp;
end$$
delimiter ;
-- 声明一个名为total_sale的变量,数据类型为int,默认值为0
declare total_sale int default 0;
-- 声明共享数据类类型的两个或多个变量
declare x,y int default 0;
- 分配变量值
直接修改变量值
set x = 3;
set y = 4;
-- select into将查询结果赋值给变量
declare avgRes double default 0;
select avg(salary) into avgRes from emp;
- 变量的范围
存储过程中声明的变量,当达到存储过程的end语句时,将超出范围,在代码块中无法访问
6 存储过程参数
定义参数 create produce name(模式{in|out|inout} 参数名称 数据类型(大小))
- 【in】 输入参数
根据传入的名称,获取对应的信息
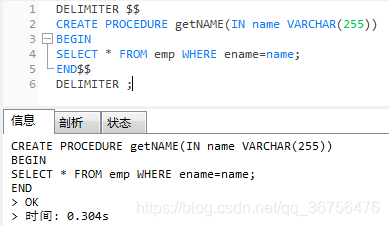
delimiter $$
create procedure getName(in name varchar(255))
begin
select * from emp where ename = name;
end$$
delimiter ;
-- 调用
call getName('zx');
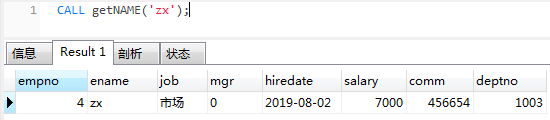
- 【out】输出数据
给我一个名称,可以把他的薪资给你
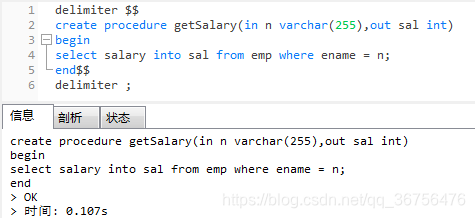
delimiter $$
create procedure getSalary(in n varchar(255),out sal int)
begin
select salary into sal from emp where ename = n;
end$$
delimiter ;
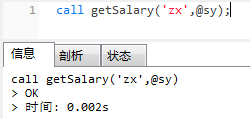
-- 在存储过程以外定义一个变量sy接收查询出来的工资值
call getSalary('zx',@sy);
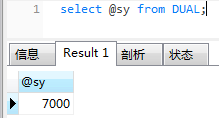
-- 查看取出的值
select @sy from DUAL;
等同于 select @sy;
-- 这里DUAL 是一张虚拟表
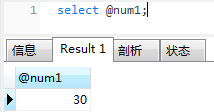
- 【inout】 输入、运算、再输出
传入一个指定值,运算后再输出这个值
-- 编辑运算
delimiter $$
create procedure test(inout num int,in inc int)
begin
set num = num + inc;
end$$
delimiter ;
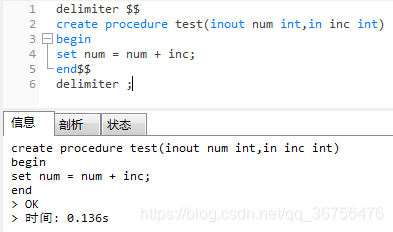
-- 定义num1的值
set @num1 = 20;
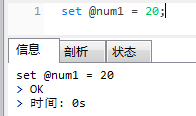
-- 执行运算
call test(@num1,10);
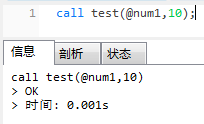
-- 查看运算结果
select @num1;
7 存储过程语句
- if语句
-- 语法
if expression then
statements;
else
else-statements; --[可以没有else]
end if;
- case语句
-- 语法
case case_expression
when when_expression_1 then commands
when when_expression_2 then commands
...
else commands
end case;
- 循环
(1)while
while expression do
statements
end while
(2)repeat
repeat
statements;
until expression
end repeat
自定义函数
- 随机生成一个指定个数的字符串
语法:
create function 函数名(参数名 参数类型) return 返回值类型(大小)
delimiter $$
-- 创建一个自定义函数
create function rand_str(n int) returns varchar(255)
begin
-- 声明一个字符串默认值为52个字母
declare str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
-- 声明一个变量来记录当前是第几个字符
declare i int default 0;
-- 声明一个变量来记录生成的结果
declare res_str varchar(255) default '';
while i < n do
-- 当目前的字符数小于要求字符数时,执行while内操作
-- 随机生成1到52之间的数:【1+rand()*52 】,取整:【floor(1+rand()*52)】
-- 截取字符串:【 substr(str,floor(1+rand()*52,1)】
-- 拼接字符串
set res_str = concat(res_str,substr(str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return res_str;
end$$
delimiter ;
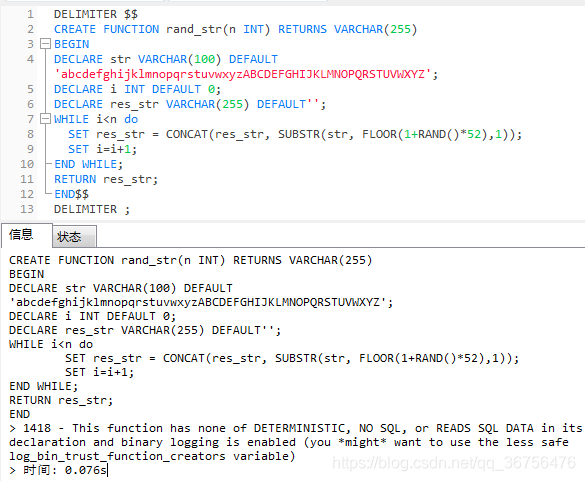
执行后发现有错误,原因是我们开启了bin-log,在function里面,只有 DETERMINISTIC, NO SQL 和 READS SQL DATA 被支持。如果我们开启了 bin-log, 我们就必须为我们的function指定一个参数。
在这里,只需要执行一条语句
set global log_bin_trust_function_creators=1;
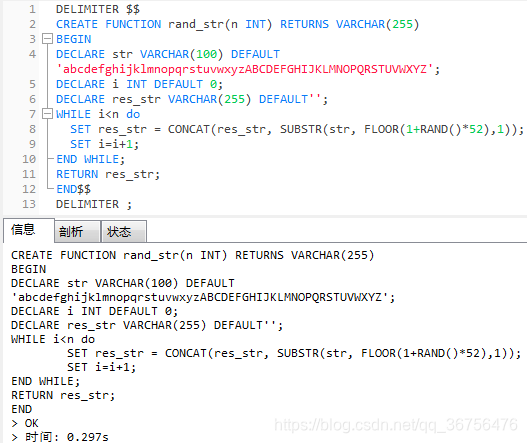
再执行新建函数语句,函数创建成功。
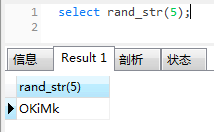
-- 执行函数,指定长度
select rand_str(5);
- 建立一个拥有海量数据的表
-- 建表
create table new_emp(id int, name varchar(50),age int);
-- 插入海量数据
delimiter $$
create procedure insert_emp(in startNum int, in max_num int)
begin
-- 声明一个变量记录当前是第几条数据
declare i int default 0;
-- 默认情况下创建一条数据就自动提交sql,但是每创建一个数据就提交一次太费时,autocommit设置成0不自动提交,等创建完成全部数据再提交。
set autocommit = 0;
repeat
set i = i + 1;
-- 插入数据
insert into new_emp values(startNum+i,rand_str(5),floor(10+rand()*30));
until i = max_num
end repeat;
commit; --整体提交所有sql,提高效率
end$$
delimiter ;
-- 执行插入数据,从100开始创建10000000条数据
call insert_emp10(100,10000000);
创建10000000数据太费时,所以这里测试了从100开始创建200条。
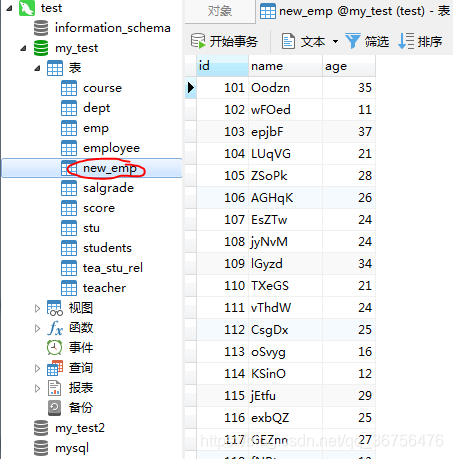
打开新建的表,查看批量插入的数据。
索引
索引用于快速找出在某个列中有一特定值的行;
不宜用索引时,mysql必须从第一条几率开始读完整个表,直到找出相关的行;
使用索引节约时间,但是占空间,降低更新速度。
1 索引的分类
- 单值索引:一个索引只包含单个列,一个表可以有多个单列索引
- 唯一索引:索引列的值必须唯一,但允许有空值
- 复合索引:一个索引包含多个列 index multildx(id,name,age)
- 全文索引:只有在MyISAM引擎上才能使用,只能在char,varchar,text类型字段上使用全文索引
- 空间索引:空间索引是对空间数据类型的字段建立的索引
2 索引操作
- 创建索引
create index 索引名称 on table(column[,column]…);
create index salary_index on emp(salary);
-
删除索引
drop index 索引名称 on 表名 -
查看索引
show index from 表名; -
自动创建索引
在表上定义了主键时,会自动创建一个对应的唯一索引
在表上顶一个一个外键时,会自动创建一个普通索引
3 explain
用来查看索引是否正在被使用,并且输出其使用的索引的信息
select * from emp where salary = 2000;
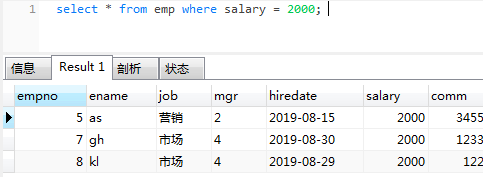
-- 只需在原语句前加explain
explain select * from emp where salary = 2000;
看到刚才创建的索引
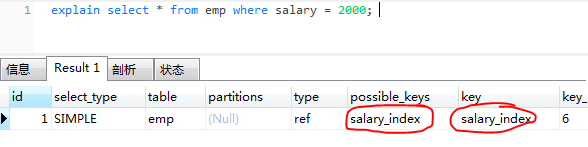

- id:
select识别符,这是select的查询序列号,也就是一条语句中,该select是第几次出现,在本次语句中,select就只有一个 ,所以是1 - select_type:
所使用的select查询类型,simple表示为简单的select,用于进行不需要Union操作或不含子查询的简单select查询 - table:
数据表的名字,他们按被读取的先后顺序排列 - type:
指定数据表和其他数据表之间的关联关系,该表中所有符合检索值的记录都会被取出来和从上一个表中取出来的记录作联合 - key:
实际选用的索引 - possible_keys:
显示可能应用在这张表中的索引 - key_len:
显示了mysql使用索引的长度(也就是使用的索引的个数),当key字段的值为null时,索引的长度就是null。 - ref:关键字
- rows:行数
- extra:附加的
4 添加索引
在图形界面navicat中添加索引:选中表–设计表–索引
5 索引结构
先对数据进行排序
- btree索引:
b+树索引,平衡多叉树,从根节点到每个叶子节点的高度差不超过1,且同层级的节点间有指针相互链接 - hash索引:
检索效率高,但是使用少由于只支持内存引擎
6 需要创建索引的情况
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合建立索引,因为每次更新都要更新索引
- where条件里用不到的字段不创建索引
- 查询中排序的字段,排序的字段若通过索引访问将大大提高排序速度
- 查询中统计或者分组字段
7 不需要创建索引
- 表记录太少
- 经常增删改的表
- 如果某个数据列包含许多重复的内容,建立索引就没有效果
