1. 图像分类数据和label分别是什么 图像分类存在的问题与挑战
图像分类的数据是一张图片上的像素点。灰度图像只有一个通道,而彩色图像有RGB三个通道。
对于计算机来说,它不能辨别出这张照片上的物体。所以,我们需要向这个图片赋予标签以让计算机识别。
问题与挑战:
a. 即使是同一个物体,拍摄的角度不同,照片背后蕴含的数据也是不同的。
b. 不同的光线、背景以及被遮挡等问题也会阻碍计算机正确识别物体。
2. 使用python加载一张彩色图片,观察像素值
from PIL import Image
########获取图片指定像素点的像素
def getPngPix(pngPath = "aa.png",pixelX = 1,pixelY = 1):
img_src = Image.open(pngPath)
img_src = img_src.convert('RGBA')
str_strlist = img_src.load()
data = str_strlist[pixelX,pixelY]
img_src.close()
return data
print(getPngPix())
3. L1范数,L2范数数学表达式 这两种度量分别适用于什么情况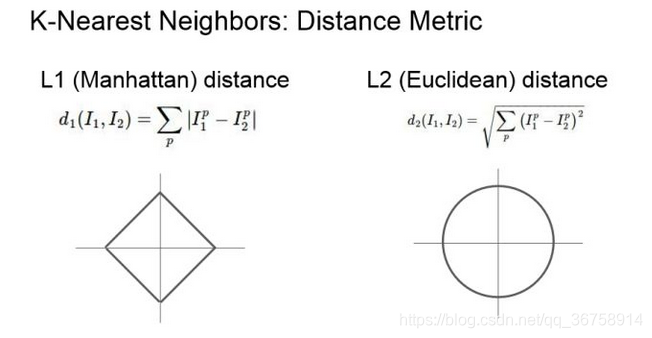
L1范数是指向量中各个元素绝对值之和。
L2范数是指向量各元素的平方和然后求平方根。
L1 是倾向于产生稀疏解,而 L2 倾向于减小参数,尽管都能简化模型,但是一般来说 L2 模型的抗过拟合的能力更好一点。并且进一步说,L1 是假定参数符合拉普拉斯分布,L2 是假定参数符合高斯分布。
4. 描述近邻算法KNN算法的复杂度 为什么很少使用在图像中以及它存在的问题
复杂度分析:
训练复杂度:
算法只是将训练数据及标签预先保存,并不涉及某些计算,复杂度为
。
测试复杂度:对于某个样本
,需要与标签数据逐一进行对比,计算量与数据大小有关,复杂度为
。
存在的问题:
a. 计算量大;
b. 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
c. 需要大量的内存。
5. 了解cifar10数据集
是由50000个训练样本和10000个测试样本组成的含有十个类别的数据集。
6. 超参数怎么选择合适(即数据集如何划分)
实际数据采集后,为了验证模型的准确性,我们要人为拆分数据集和测试集。
实际使用中,当算法在训练集表现得很完美时,应用到测试集后,往往就会发现表现得不尽如人意。因此,我们还要划分出验证集,通过训练集的训练,以及验证集验证模型的优良程度,最后在测试集作预测是比较好的选择。
这里又要导入一个交叉验证的概念,因为作为验证集后,我们就有部分数据损失没有用上,不免的有点浪费。交叉验证就不再是固定划分一块验证集了。不过训练量对比起之前的做法提高了数倍,因此交叉验证比较适用于小数据集使用。
