Github项目地址
https://github.com/kkxkkx/Sudoku_self
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 100 |
| · Design Spec | · 生成设计文档 | 120 | 160 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 60 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 120 | 60 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | 240 | 500 |
| · Code Review | · 代码复审 | 30 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 500 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 90 |
| 合计 | 1080 | 1830 |
需求分析
需求
运行一个命令行程序,程序能:
1. 生成不重复的数独终局至文件。
2. 读取文件内的数独问题,求解并将结果输出到文件。
数据建模
将数独分成9个宫进行求解,ER表示如下,因为数独左上角第一块确定,所以将其看作数独的属性。

功能建模
数据源:用户
数据终点:文件
主要数据流:生成指令、求解指令、数独(待求解),以及终局
主要支持文件:待求解数独文件
主要处理过程:生成终局、求解数独
0层图

对系统进行求精,划分系统的子系统。

行为建模

解题思路
在最开始拿到题目的时候,想起上学期算法课程学过的回溯算法,决定用会回溯算法进行实现,所以翻看了算法设计的课本和ppt,对回溯算法重新进行了学习。在生成n个不同局面和求解给定数独的思路大致一致,但有在细节处的处理有些不同。首先是生成n个不同的局面,按行进行循环,有一个二维数组保存每个位置的可能数字,从可能数字中随机选一个放在该位置,若该位置找不到可能的位置,则回到上一个,修改上一个位置的解。不断进行回溯,直到所有的位置都合法。若是对给定局面进行求解,则将空白位置用数组记录下来,只对空白位置进行回溯即可。
但在该回溯算法中,搜索时盲目的,效率较低,最差的实现对每个空方格试探所有可能的数字,有大量的时间浪费。并且如果需要生成多个终局时,每一个终局都是通过回溯实现,且生成不同的终局由Random()进行数字选择实现,但实际上Random生成伪随机数,在一定时间会生成相同随机数,无法保证在生成终局数目足够大时,不会产生两个相同的终局。
因为算法效率有很大的改进空间,以及无法保证在n足够大时,所有终局都相异,所以在对代码重构的过程中,引入了排列组合的算法,对原有进行优化。将数独分成9个3X3的小方块,每个小方块是一个宫。
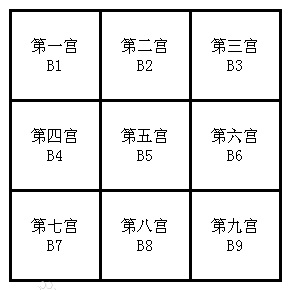
参考维基百科提供的一个生成终局思路,由第一宫生成其余八个宫。对第一宫中的块进行排列组合即可,因为生成终局时,要求左上角的第一个数为:(学号后两位相加)%9+1,(1+3)%9+1=5,所以左上角为5,且不允许改变。即在第一宫内只有八个块可以移动,有8!=40320种情况,并且在每一宫内(除了第一宫)进行列列变换有3!×3!×3!×3!=1296,第二宫和第三宫可以交换,第四宫和第七宫可以交换有2!×2!=4,总共可以生成209,018,880个终局(大于1,000,000),此方案可行。
对于各种全排列,使用递归的方式实现。
设计实验过程
类图

共有三个类,Main用于判断输入是否合法、将终局写入文件、判断输入命令是否合法,Generate类用于生成终局,Solve类用于求解数独。
测试
使用Junit5对三个类分别进行单元测试
MainTest用于测试输入是否合法,以及是否可以顺利写入文件,
GenerateTest测试其中的函数是否正常,并进行了重复性检测,检测器生成的1000个终局中是否有相同的情况。
SolveTest对Solve中部分主要函数进行了检测,并对求解结果进行了有效性检测,判断是否是否求出了正确的数独解。

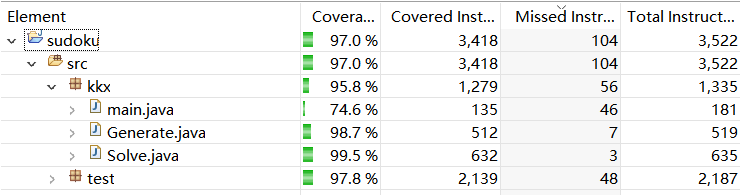
单元测试覆盖率
代码质量分析
用SonarLint插件对每个java文件进行代码质量优化
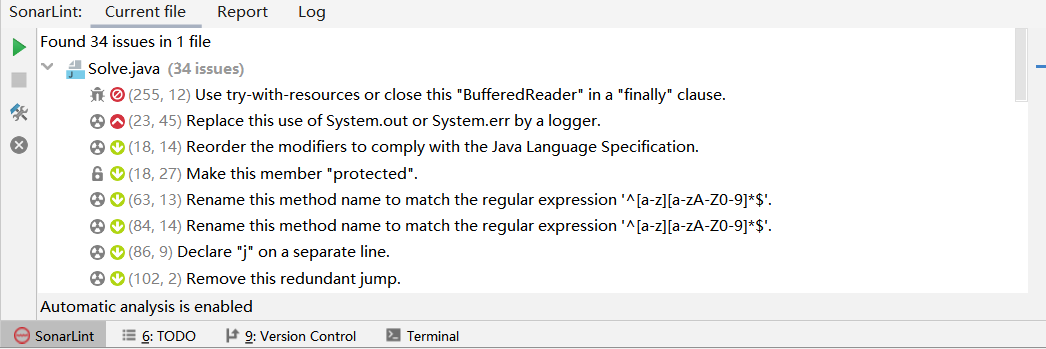
分析过后,除了Main类中因为需要打印命令错误提示,仍存在一些warning,其余文件中的warning全部消除。

性能改进
用Intellij中插件JProfiler进行程序性能分析
最初的程序每生成一个终局,直接写入文件,且进行回溯时,多次进行值的交换。为了保证随机性,每一次将所有可能值先放入链表,然后将随机选取一个放入该空位。在求解数独时,先读取一个数独,求解后写入文件,再继续读取下一个数据。这种算法会频繁创建很多对象,且读写会花费大量的时间。


改进后,时间上有了非常大的提升,且在回溯,用一个27位数组Criterion,前九位表示每一行可能解,中间九位表示每一列可能解,最后九位表示每一个宫的可能解,且每一个数可以表示成一个九位的二进制,从右到左依次表示1-9,若Criterion[0]=000_000_001,则表示第一行只有1没有用过,该位置的可行解只有1。选择一个数时只需将该数与对应的下标的Criterion进行与运算,即可将该数标记为使用,这样减少了反复复制的时间。且改进后不再随机选取可行解,按顺序进行选择。
并且改进后每生成一个终局,先放在一个char数组中,生成所有的终局,统一写入文件;在求解数独时,一次读取出所有的待求解数独,每个分别求解,再统一写入。