下载安装
配置环境变量
/etc/profile
这里 的安装的路径要写自己的
export ZK_HOME=/usr/local/zookeeper-3.4.7/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin
更新配置
source /etc/profile
随便的进入一个目录,看是否可以补全zkS。。。。.sh
进入zookeeper的安装目录找到conf目录下的
创建zoo.cfg 加入如下的内容! 这里的目录我们要手动得创建,要不然会报错!
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=5
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=2
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/hadoop/zookeeperdata
# the port at which the clients will connect
clientPort=2181
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
使用ssh的认证和scp的远程的分发功能
scp -r /usr/local/(zookeeper)(zookeeper的安装目录) hadoop02:/usr/local/
scp -r /usr/local/(zookeeper)(zookeeper的安装目录) hadoop03:/usr/local/
在每台的zookeeper的临时存放的目录下的创建myid
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
根据上面的配置id
在hadoop01:中 :echo 1 >> /data/hadoop/zookeeperdata/myid
在hadoop02: 中:echo 2 >> /data/hadoop/zookeeperdata/myid
在hadoop03: 中:echo 3 >> /data/hadoop/zookeeperdata/myid
启动zookeeper的命令
zkServer.sh start
查看zookeeper的各个节点的状态
zkServer.sh status
jps
成功的结果:
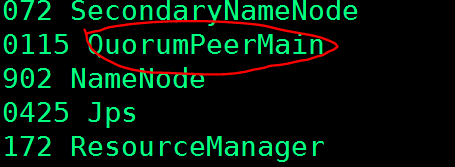
可以使用运程登入功能:
zk.Cli.sh 名字(不加的话是登入当前的窗口)

使用quit退出!
