YOLO V3 给出了官方修改xml标注的官方说明,把/home/hzc/Pictures/VOCdevkit/VOC2012/Annotations中标准的xml格式文件修改成.txt 格式文件保存在labels文件夹下,读取速度更快,更简洁
标注修改前:
标注修改后:产生了新的labels文件夹
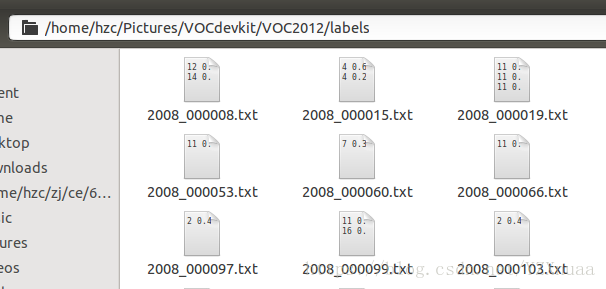
txt内容:11代表狗狗的种类,四个数字代表中心的xy坐标和打框的大小

yolov3结果:好像少了一只狗。。。不要在意这些细节

VOC_Label.py修改文件,注意要修改路径,否则报错。
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join # sets = [('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')] sets = [('2012', 'train'), ] classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] def convert(size, box): # pic_size, get the ratio of the pic dw = 1./size[0] dh = 1./size[1] x = (box[0] + box[1])/2.0 y = (box[2] + box[3])/2.0 w = box[1] - box[0] h = box[3] - box[2] # 归一化 x = x*dw w = w*dw y = y*dh h = h*dh return (x, y, w, h) def convert_annotation(year, image_id): in_file = open('/home/hzc/Pictures/VOCdevkit/VOC%s/Annotations/%s.xml' % (year, image_id)) out_file = open('VOCdevkit/VOC%s/labels/%s.txt' % (year, image_id), 'w') print('VOCdevkit/VOC%s/labels/%s.txt' % (year, image_id)) tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) # 过滤出所有object属性 for obj in root.iter('object'): # test: obj is a string? print(obj) difficult = obj.find('difficult').text cls = obj.find('name').text # 不属于voc类别的不考虑 if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') wd = getcwd() for year, image_set in sets: if not os.path.exists('VOCdevkit/VOC%s/labels/' % (year)): os.makedirs('/home/hzc/Pictures/VOCdevkit/VOC%s/labels/' % (year)) image_ids = open('/home/hzc/Pictures/VOCdevkit/VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split() # write the info into a new text list_file = open('%s_%s.txt' % (year, image_set), 'w') print(list_file) for image_id in image_ids: list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' % (wd, year, image_id)) print('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' % (wd, year, image_id)) convert_annotation(year, image_id) list_file.close()