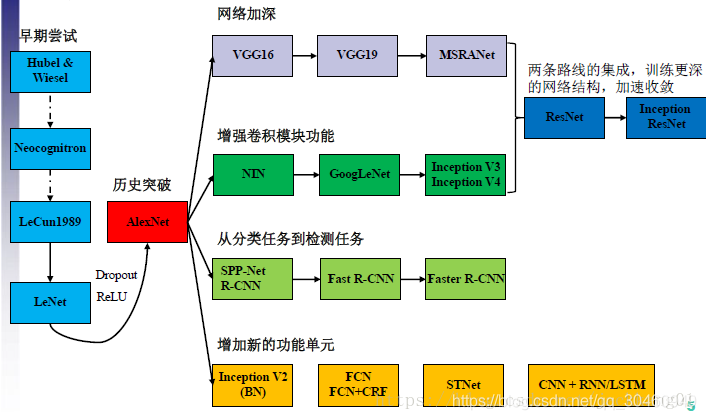
深度学习发展史

典型结构
CNN常见的结构有:
1)LeNet ,最早用于数字识别
广为流传LeNet诞生于1998年,网络结构比较完整,包括卷积层、pooling层、全连接层,这些都是现代CNN网络的基本组件。被认为是CNN的开端。
2)AlexNet ,2012年的视觉大赛冠军
2012年Geoffrey和他学生Alex在ImageNet的竞赛中,刷新了image classification的记录,一举奠定了deep learning 在计算机视觉中的地位。这次竞赛中Alex所用的结构就被称为作为AlexNet。
对比LeNet,AlexNet加入了 (1)非线性激活函数:ReLU;(2)防止过拟合的方法:Dropout,Data augmentation。同时,使用多个GPU,LRN归一化层。其主要的优势有:网络扩大(5个卷积层+3个全连接层+1个softmax层);解决过拟合问题(dropout,data augmentation,LRN);多GPU加速计算。
3)ZF Net,2013年的视觉大赛冠军
4)GoogLeNet 四代(Inception v1、v2、v3、v4),2014年
提出的Inception结构是主要的创新点,这是(Network In Network)的结构,即原来的结点也是一个网络。其使用使得之后整个网络结构的宽度和深度都可扩大,能够带来2-3倍的性能提升。网络结构如下:真的是得深者,得天下哈哈。
5)VGG Net,2014年
VGG-Net来自 Andrew Zisserman 教授的组 (Oxford),在2014年的 ILSVRC localization and classification 两个问题上分别取得了第一名和第二名,其不同于AlexNet的地方是:VGG-Net使用更多的层,通常有16-19层,而AlexNet只有8层。同时,VGG-Net的所有 convolutional layer 使用同样大小的 convolutional filter,大小为 3 x 3。
6)ResNet 两代(ResNet v1和ResNet v2),2015年,152层。
ResNet提出了一种减轻网络训练负担的残差学习框架,这种网络比以前使用过的网络本质上层次更深。其明确地将这层作为输入层相关的学习残差函数,而不是学习未知的函数。在ImageNet数据集用152 层(据说层数已经超过1000==)——比VGG网络深8倍的深度来评估残差网络,但它仍具有较低的复杂度。在2015年大规模视觉识别挑战赛分类任务中赢得了第一。
7)DenseNet
8)ResNeXt
10)MobileNet
发展的速度
imageNet图像识别是竞赛从2010和2011年使用浅层的识别方法(就是手动提取特征, 设计识别器)错误率有25.8%到28.2%。到了2012年,出现了AlexNet模型,首次使用8层的神经网络进行识别,错误率降到了16.4%。一直到最近何凯明发明的ResNet已经达到了152层的神经网络,其识别错误率降到了3.57%,这个识错误率已经比人眼还低。
从上面的数据中可以看出从8层到19层的翻倍增长用了两年,从19层到152层的增长用了2年。如果保持这种指数级的爆炸性增长,是十分可怕的。
心得
1)LeNet:元老级框架,结构简单,却开创了卷积神经网络的新纪元,具有重要的学习价值。
2) AlexNet:打开了深度学习的大门,深度学习成为学术界的新宠。主要意义在于验证了神经网络的有效性,为后续的发展提供了参考。
3)ZF-Net:这个在Alex上改进较少,主要贡献是2点:
a)由AlexNet的双GPU改为单GPU上训练;
b)对神经网络的每一层都进行了可视化,这是最主要的贡献。
4)VGG-Net:在AlexNet的基础上,提出了更深的网络,分别为VGG-16和VGG-19,参数是AlexNet的三倍,为后面的框架提供了方向:加深网络的深度。
5)GoogLeNet:有四个版本,主要是在网络宽度上进行了改进,不像VGG-Net只是单纯增加深度,在同一层中使用了多个不同尺寸的卷积,以获得不同的视野,最后级联(直接叠加通道数量),这就是Inception module从v2开始,进一步简化把Inception module中的n×n模块分解为1×n和n×1的组合,减少了参数数量,v3进一步把最开始的7×7卷积和其他非3×3进行分解,v4引入了ResNet残差的思想。
6)ResNet:首次提出了残差的思想(跨层连接,即),解决了网络过深而导致的梯度消失的问题,为更深的网络提供了有力的方向。注意:
a)此处的跨层连接的计算方式和GoogLeNet中的级联不同,这里是每个通道进行相加操作,如果的通道数和的通道数不同,则对用1×1的卷积操作,使得维度一样;
b)有有两个版本v1和v2,v2只是引入了BN(banch normalization),并讨论的BN放置位置的问题,其他思想一样。
7)DenseNet:比ResNet来的更加彻底,即当前的每一层都和前面的每一层连接。这里有两点值得注意:
a)为了解决每个输入的尺寸不一样的问题,因此提出了Dense block,即在这个模块中才进行每一层的连接,这样便于控制输入尺寸的大小,Dense block模块之间就可以放心的使用池化操作了;
b)此处的连接的计算方式为级联(直接叠加通道数量),和GoogLeNet一样,和ResNet不同。
8)ResNeXt:在ResNet的基础上,借鉴GoogLeNet的思想,增加了网络的宽度,同时,为了简化设计的复杂度,不像Inception module里面采用了不同尺寸的卷积,这里使用相同的的卷积,并用了32个,最后每个通道相加,和Inception module的级联不同。
9)DPN:一种双通道网络,结合了ResNet和DenseNet的优点,具有一定的参考价值。
推荐看的论文和书籍
1.Hinton等三个大神写的关于AI的论文<<Deep learning>>
2.瑞士的大牛,Yoshua Bengio写的<<Learning Deep Architectures for AI>>
3.去年出版的《Deep learning》的一本书,github上搜索得到
模型研究
早起模型介绍
基于CNN的分类模型:AlexNet, VGG-Net, ZF-Net,GooLeNet
做分割的模型: FCN, Deeplab, DeconvNet, CRFRNN
做目标检测: R-CNN, Fast R-CNN, Faster R-CNN
最新模型介绍
图像分割: ENet,
目标检测和识别: MobileNet, ShuffleNet
图像分割和解析: PSPNet, RefineNet,DenseNet: 目的在于在网络中不同层的feature map进行全连接。
检测,分割都涉及: Mask R-CNN
参考:
https://blog.csdn.net/jackkang01/article/details/81064114 经典网络架构
https://blog.csdn.net/chenyuping333/article/details/82526440
https://blog.csdn.net/jackkang01/article/details/81064114//code and paper
https://blog.csdn.net/qq_41994006/article/details/80959561
