kubernetes核心组件之etcd详解
一 、etcd组件
etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现。etcd是由CoreOS开发并维护的,灵感来自于 ZooKeeper 和 Doozer,它使用Go语言编写,并通过Raft一致性算法处理日志复制以保证强一致性。Raft是一个来自Stanford的新的一致性算法,适用于分布式系统的日志复制,Raft通过选举的方式来实现一致性,在Raft中,任何一个节点都可能成为Leader。Google的容器集群管理系统Kubernetes、开源PaaS平台Cloud Foundry和CoreOS的Fleet都广泛使用了etcd。etcd的特性如下:
- 简单: curl可访问的用户的API(HTTP+JSON)
- 安全: 可选的SSL客户端证书认证
- 快速: 单实例每秒 1000 次写操作
- 可靠: 使用Raft保证一致性
ETCD概念词汇表:
| 概念 | 解释 |
|---|---|
| Raft | etcd所采用的保证分布式系统强一致性的算法。 |
| Node | 一个Raft状态机实例。 |
| Member | 一个etcd实例。它管理着一个Node,并且可以为客户端请求提供服务。 |
| Cluster | 由多个Member构成可以协同工作的etcd集群。 |
| Peer | 对同一个etcd集群中另外一个Member的称呼。 |
| Client | 向etcd集群发送HTTP请求的客户端。 |
| WAL | 预写式日志,etcd用于持久化存储的日志格式。 |
| snapshot | etcd防止WAL文件过多而设置的快照,存储etcd数据状态。 |
| Proxy | etcd的一种模式,为etcd集群提供反向代理服务。 |
| Leader | Raft算法中通过竞选而产生的处理所有数据提交的节点。 |
| Follower | 竞选失败的节点作为Raft中的从属节点,为算法提供强一致性保证。 |
| Candidate | 当Follower超过一定时间接收不到Leader的心跳时转变为Candidate开始Leader竞选。 |
| Term | 某个节点成为Leader到下一次竞选开始的时间周期,称为一个Term。 |
| Index | 数据项编号。Raft中通过Term和Index来定位数据。 |
1、etcd架构设计
etcd主要分为四个部分:
- HTTP Server: 用于处理用户发送的API请求以及其他etcd节点的同步与心跳信息请求
- Store: 用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是 etcd 对用户提供的大多数 API 功能的具体实现。
- Raft: Raft 强一致性算法的具体实现,是 etcd 的核心。
- WAL:Write Ahead Log(预写式日志/日志先行),是 etcd 的数据存储方式,也是一种实现事务日志的标准方法。etcd通过 WAL 进行持久化存储,所有的数据提交前都会事先记录日志。Snapshot 是为了防止数据过多而进行的状态快照;Entry 表示存储的具体日志内容。
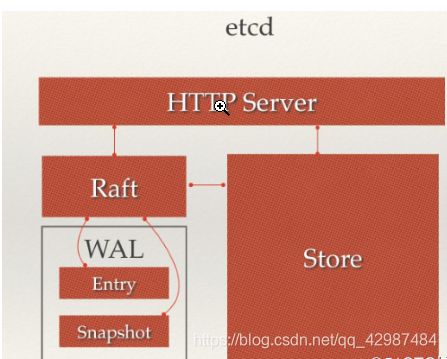
- 流程分析:通常,一个用户的请求发送过来,会经由HTTP Server转发给Store进行具体的事务处理,如果涉及到节点的修改,则交给Raft模块进行状态的变更、日志的记录,然后再同步给别的etcd节点以确认数据提交,最后进行数据的提交,再次同步。
1.1 工作原理
etcd使用Raft协议来维护集群内各个节点状态的一致性。简单说,ETCD集群是一个分布式系统,由多个节点相互通信构成整体对外服务,每个节点都存储了完整的数据,并且通过Raft协议保证每个节点维护的数据是一致的。
- Raft算法
Raft 是一种为了管理复制日志的一致性算法。它提供了和 Paxos 算法相同的功能和性能,但是它的算法结构和 Paxos 不同,使得 Raft 算法更加容易理解并且更容易构建实际的系统。一致性算法允许一组机器像一个整体一样工作,即使其中一些机器出现故障也能够继续工作下去。正因为如此,一致性算法在构建可信赖的大规模软件系统中扮演着重要的角色。Raft算法分为三部分,分别是Leader选举、日志复制和安全性。
- Leader选举:包括
Raft 状态机和Raft算法中的Term(任期)两部分。
A) Raft 状态机
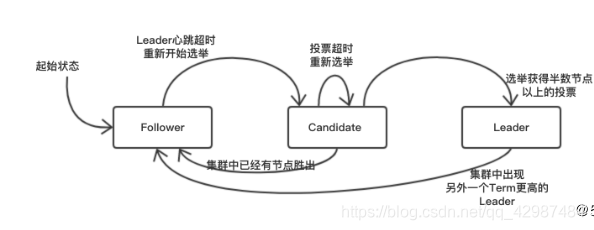
Raft集群中的每个节点都处于一种基于角色的状态机中。具体来说,Raft定义了节点的三种角色: Follower、Candidate和Leader。
1、Leader(领导者): Leader节点在集群中有且仅能有一个,它负责向所有的Follower节点同步日志数据。
2、Follower(跟随者): Follower节点从Leader节点获取日志,提供数据查询功能,并将所有修改请求转发给Leader节点。(注意:由于proxy模式的本职就是启一个HTTP代理服务器,所以Etcd的代理节点(proxy)即作为Proxy角色的节点不会参与Leader的选举,只是将所有接收到的用户查询和修改请求转发到任意一个Follower或者Leader节点上。)
3、Candidate(候选者): 当集群中的Leader节点不存在或者失联之后,其他Follower节点转换为Candidate,然后开始新的Leader节点选举。
这三种角色状态之间的转换,如下图:
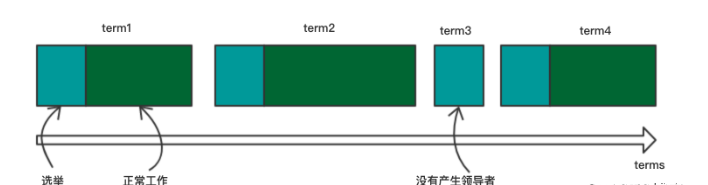
B)Raft算法中的Term(任期)
Raft会把时间分割成任意长度的任期,并且任期用连续的整数来标记。每一段任期都是从一次选举开始,一个或者多个候选人尝试成为领导者。如果一个候选人赢得选举,然后他就会在接下来的任期中充当Leader的职责。在某些情况下,一次选举会造成选票瓜分,这样,这一个任期将没有Leader。如果没有Leader,那么新的一轮选举就马上开始,也就是新的任期就会开始。Raft保证了在一个Term任期内,有且只有一个Leader。
- 日志复制:是指主节点将每次操作形成日志条目,并持久化到本地磁盘,然后通过网络IO发送给其他节点。
一旦一个领导人被选举出来,他就开始为客户端提供服务。客户端的每一个请求都包含一条被复制状态机执行的指令。领导人把这条指令作为一条新的日志条目附加到日志中去,然后并行的发起附加条目 RPCs 给其他的服务器,让他们复制这条日志条目。
Raft 算法保证所有已提交的日志条目都是持久化的并且最终会被所有可用的状态机执行。当主节点收到包括自己在内超过半数节点成功返回,那么认为该日志是可提交的(committed),并将日志输入到状态机,将结果返回给客户端。
在正常的操作中,领导人和跟随者的日志保持一致性,所以附加日志 RPC 的一致性检查从来不会失败。然而,领导人崩溃的情况会使得日志处于不一致的状态(老的领导人可能还没有完全复制所有的日志条目)。这种不一致问题会在一系列的领导人和跟随者崩溃的情况下加剧。跟随者的日志可能和新的领导人不同的方式。跟随者可能会丢失一些在新的领导人中有的日志条目,他也可能拥有一些领导人没有的日志条目,或者两者都发生。丢失或者多出日志条目可能会持续多个任期。这就引出了另一个部分,就是安全性。 - 安全性:选主以及日志复制并不能保证节点间数据一致。试想,当一个某个节点挂掉了,一段时间后再次重启,并当选为主节点。而在其挂掉这段时间内,集群若有超过半数节点存活,集群会正常工作,那么会有日志提交。这些提交的日志无法传递给挂掉的节点。当挂掉的节点再次当选主节点,它将缺失部分已提交的日志。在这样场景下,按Raft协议,它将自己日志复制给其他节点,会将集群已经提交的日志给覆盖掉。这显然是错误的。
其他协议解决这个问题的办法是,新当选的主节点会询问其他节点,和自己数据对比,确定出集群已提交数据,然后将缺失的数据同步过来。这个方案有明显缺陷,增加了集群恢复服务的时间(集群在选举阶段不可服务),并且增加了协议的复杂度。Raft解决的办法是,在选主逻辑中,对能够成为主的节点加以限制,确保选出的节点已定包含了集群已经提交的所有日志。如果新选出的主节点已经包含了集群所有提交的日志,那就不需要从和其他节点比对数据了。简化了流程,缩短了集群恢复服务的时间。
2、etcd应用场景
etcd应用场景很多,主要的有以下六种:服务发现、消息发布与订阅(配置中心)、负载均衡(集群管理)、分布式锁、分布式队列、集群监控与LEADER竞选。
2.1 服务发现
服务发现(Service Discovery)要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。
从本质上说,服务发现就是想要了解集群中是否有进程在监听udp或tcp端口,并且通过名字就可以进行查找和连接。要解决服务发现的问题,需要有下面三大支柱,缺一不可。
- 一个强一致性、高可用的服务存储目录。基于Raft算法的etcd天生就是这样一个强一致性高可用的服务存储目录。
- 一种注册服务和监控服务健康状态的机制。用户可以在etcd中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。
- 一种查找和连接服务的机制。通过在etcd指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个proxy模式的etcd,这样就可以确保能访问etcd集群的服务都能互相连接。
2.2 消息发布与订阅(配置中心)
在分布式系统中,最为适用的组件间通信方式是消息发布与订阅机制。
具体而言,即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦相关主题有消息发布,就会实时通知订阅者。
通过这种方式可以实现分布式系统配置的集中式管理与实时动态更新。
2.3 负载均衡(集群管理)
利用etcd维护一个负载均衡节点表。etcd可以监控一个集群中多个节点的状态,当有一个请求发过来后,可以轮询式地把请求转发给存活着的多个节点。
类似KafkaMQ,通过Zookeeper来维护生产者和消费者的负载均衡。同样也可以用etcd来做Zookeeper的工作。
2.4 分布式锁
因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。
锁服务有以下两种使用方式:
- 保持独占,即所有试图获取锁的用户最终只有一个可以得到。etcd为此提供了一套实现分布式锁原子操作CAS(CompareAndSwap)的API。通过设置prevExist值,可以保证在多个节点同时创建某个目录时,只有一个成功,而该用户即可认为是获得了锁。
- 控制时序,即所有试图获取锁的用户都会进入等待队列,获得锁的顺序是全局唯一的,同时决定了队列执行顺序。etcd为此也提供了一套API(自动创建有序键),对一个目录建值时指定为POST动作,这样etcd会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用API按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
2.5 分布式队列
在保证队列达到某个条件时再统一按顺序执行。这种方法的实现可以在/queue这个目录中另外建立一个/queue/condition节点。
- condition可以表示队列大小。比如一个大的任务需要很多小任务就绪的情况下才能执行,每次有一个小任务就绪,就给这个condition数字加1,直到达到大任务规定的数字,再开始执行队列里的一系列小任务,最终执行大任务。
- condition可以表示某个任务在不在队列。这个任务可以是所有排序任务的首个执行程序,也可以是拓扑结构中没有依赖的点。通常,必须执行这些任务后才能执行队列中的其他任务。
- condition还可以表示其它的一类开始执行任务的通知。可以由控制程序指定,当condition出现变化时,开始执行队列任务。
2.6 集群监控与LEADER竞选
通过etcd来进行监控实现起来非常简单并且实时性强,用到了以下两点特性。
- Watcher机制,当某个节点消失或有变动时,Watcher会第一时间发现并告知用户。
- 节点可以设置TTL key,比如每隔30s向etcd发送一次心跳使代表该节点仍然存活,否则说明节点消失。
这样就可以第一时间检测到各节点的健康状态,以完成集群的监控要求。
3、etcd启动参数详解
- 2379和2380为etcd在IANA 的注册端口,以前为私有端口4001和7001。
3.1 member flags
| 参数 | 使用说明 |
|---|---|
| --name 'default’ | 本member的名字 |
| --data-dir '${name}.etcd’ | 指定节点的数据存储目录,这些数据包括节点ID,集群ID,集群初始化配置,Snapshot文件,若未指定-wal-dir,还会存储WAL文件;如果不指定会用缺省目录。 |
| --listen-peer-urls http://0.0.0.0:2380 | 本member侧使用,用于监听其他member发送信息的地址。ip为全0代表监听本member侧所有接口 |
| --listen-client-urls http://0.0.0.0:2379 | 本member侧使用,用于监听etcd客户发送信息的地址。ip为全0代表监听本member侧所有接口 |
| --wal-dir ‘path’ | 到专用wal目录的路径 |
| --snapshot-count ‘100000’ | number of committed transactions to trigger a snapshot to disk |
| --heartbeat-interval ‘100’ | 检测间隔的时间(毫秒) |
| --election-timeout ‘1000’ | 超时时间(毫秒) |
| --initial-election-tick-advance ‘true’ | 是否提前初始化选举时钟启动,以便更快的选举 |
| --max-snapshots ‘5’ | 要保留的最大快照文件数(0是无限的) |
| --max-wals ‘5’ | 要保留的最大wal文件数(0是无限的) |
| --cors ‘’ | comma-separated whitelist of origins for CORS (cross-origin resource sharing) |
| --quota-backend-bytes ‘0’ | 当后端大小超过给定限额时发出警报(0默认为低空间限额) |
| --max-txn-ops ‘128’ | 事务中允许的最大操作数 |
| --max-request-bytes ‘1572864’ | 服务器将接受的最大客户端请求大小(以字节为单位) |
| --grpc-keepalive-min-time ‘5s’ | 客户端在ping服务器之前应该等待的最小持续时间间隔 |
| --grpc-keepalive-interval ‘2h’ | 检查连接是否激活的服务器到客户机ping的频率持续时间(0表示禁用) |
| --grpc-keepalive-timeout ‘20s’ | 关闭无响应连接之前的额外等待时间(0表示禁用) |
3.2 clustering flags
| 参数 | 使用说明 |
|---|---|
| --initial-advertise-peer-urls 'http://localhost:2380’ | 其他member使用,其他member通过该地址与本member交互信息。一定要保证从其他member能可访问该地址。静态配置方式下,该参数的value一定要同时在–initial-cluster参数中存在。 memberID的生成受–initial-cluster-token和–initial-advertise-peer-urls影响。 |
| --initial-cluster 'etcd01=http://localhost01:2380, etcd02=http://localhost02:2380, etcd03=http://localhost03:2380’ |
本member侧使用。描述集群中所有节点的信息,本member根据此信息去联系其他member。 memberID的生成受–initial-cluster-token和–initial-advertise-peer-urls影响。 |
| --initial-cluster-state 'new’ | 用于指示本次是否为新建集群。有两个取值new和existing。如果填为existing,则该member启动时会尝试与其他member交互。集群初次建立时,要填为new,经尝试最后一个节点填existing也正常,其他节点不能填为existing。集群运行过程中,一个member故障后恢复时填为existing,经尝试填为new也正常。 |
| --initial-cluster-token 'etcd-cluster’ | 引导期间etcd集群的初始集群令牌。 在运行多个集群时,指定此参数可以防止意外的跨集群交互。 |
| --advertise-client-urls 'http://localhost:2379’ | etcd客户使用,客户通过该地址与本member交互信息。一定要保证从客户侧能可访问该地址 |
| --discovery ’ ’ | 用于引导集群的发现URL,指定第三方etcd上key地址,要建立的集群各member都会向其注册自己的地址 |
| --enable-v2 ‘true’ | 接受etcd V2客户端请求 |
| --discovery-fallback ‘proxy’ | 当发现服务失败时的预期行为(“exit”或“proxy”)。“proxy”只支持v2 API |
| --discovery-proxy ’ ’ | 用于传输到发现服务的HTTP代理 |
| --discovery-srv ’ ’ | 用于引导集群的dns srv域 |
| --strict-reconfig-check ‘true’ | 拒绝可能导致仲裁丢失的重新配置请求 |
| --auto-compaction-retention ‘0’ | auto compaction retention length. 0 means disable auto compaction |
| --auto-compaction-mode ‘periodic’ | interpret ‘auto-compaction-retention’ one of: periodic丨revision. ‘periodic’ for duration based retention, defaulting to hours if no time unit is provided (e.g. ‘5m’). ‘revision’ for revision number based retention. |
3.3 proxy flags
- 注意:“proxy” supports v2 API only.
| 参数 | 使用说明 |
|---|---|
| --proxy ‘off’ | proxy mode setting (‘off’, ‘readonly’ or ‘on’). |
| --proxy-failure-wait 5000 | time (in milliseconds) an endpoint will be held in a failed state |
| --proxy-refresh-interval 30000 | time (in milliseconds) of the endpoints refresh interval |
| --proxy-dial-timeout 1000 | time (in milliseconds) for a dial to timeout |
| --proxy-write-timeout 5000 | time (in milliseconds) for a write to timeout. |
| --proxy-read-timeout 0 | time (in milliseconds) for a read to timeout. |
3.4 security flags
| 参数 | 使用说明 |
|---|---|
| --ca-file ’ ’ [DEPRECATED] | 客户端服务器TLS CA文件的路径。“-ca-file ca.crt”可以替换为“-trusted-ca-file ca.crt -client-cert-auth”,etcd将执行相同的操作。 |
| --cert-file ’ ’ | 客户端服务器TLS证书文件的路径 |
| --key-file ‘’ | 客户端服务器TLS密钥文件的路径 |
| --client-cert-auth ‘false’ | 启用客户证书认证 |
| --client-crl-file ’ ’ | 客户端证书撤销列表文件的路径 |
| --trusted-ca-file ’ ’ | 客户端服务器TLS信任CA证书文件的路径 |
| --auto-tls ‘false’ | 客户端TLS使用生成的证书 |
| --peer-ca-file ’ ’ [DEPRECATED] | path to the peer server TLS CA file. ‘-peer-ca-file ca.crt’ could be replaced by ‘-peer-trusted-ca-file ca.crt -peer-client-cert-auth’ and etcd will perform the same. |
| --peer-cert-file ’ ’ | path to the peer server TLS cert file. |
| --peer-key-file ’ ’ | path to the peer server TLS key file. |
| --peer-client-cert-auth ‘false’ | enable peer client cert authentication. |
| --peer-trusted-ca-file ’ ’ | path to the peer server TLS trusted CA file. |
| --peer-auto-tls ‘false’ | peer TLS using self-generated certificates if --peer-key-file and --peer-cert-file are not provided. |
| --peer-crl-file ’ ’ | path to the peer certificate revocation list file. |
3.5 logging flags
| 参数 | 使用说明 |
|---|---|
| --debug ‘false’ | enable debug-level logging for etcd. |
| --log-package-levels ’ ’ | 为每个etcd包指定一个特定的日志级别(例如:‘etcdmain=CRITICAL,etcdserver=DEBUG’)。 |
| --log-output ‘default’ | 指定“stdout”或“stderr”以跳过日志记录,即使在systemd下运行时也是如此。 |
3.6 unsafe flags
- 在使用不安全标志时请小心,因为它会破坏保证根据协商一致协议。
| 参数 | 使用说明 |
|---|---|
| --force-new-cluster ‘false’ | 强制创建一个新的单成员集群。 |
3.7 auth flags
| 参数 | 使用说明 |
|---|---|
| --auth-token ‘simple’ | 指定v3认证令牌类型及其选项(‘simple’或’jwt’). |
3.8 profiling flags
| 参数 | 使用说明 |
|---|---|
| --enable-pprof ‘false’ | Enable runtime profiling data via HTTP server. Address is at client URL + “/debug/pprof/” |
| --metrics ‘basic’ | Set level of detail for exported metrics, specify ‘extensive’ to include histogram metrics. |
| --listen-metrics-urls ’ ’ | List of URLs to listen on for metrics. |
3.9 experimental flags
| 参数 | 使用说明 |
|---|---|
| --experimental-initial-corrupt-check ‘false’ | enable to check data corruption before serving any client/peer traffic. |
| --experimental-corrupt-check-time ‘0s’ | duration of time between cluster corruption check passes. |
| --experimental-enable-v2v3 ’ ’ | serve v2 requests through the v3 backend under a given prefix. |
4、etcd常用v3命令与参数
etcd最新的API版本是v3,与v2相比,v3更高效更清晰。k8s默认使用的etcd V3版本API,ectdctl默认使用V2版本API。要使用v3,设置环境变量export ETCDCTL_API=3临时更改为V3或者vim /etc/profile后在里面添加export ETCDCTL_API=3,然后执行source /etc/profile则永久更改为V3。
- 使用v3或v2命令也可在命令前带上ETCDCTL_API=3或 ETCDCTL_API=2
- 加密的方式:ETCDCTL_API=3 etcdctl \
--endpoints=https://172.xxx.xx.xx:2379 \
--cacert=/etc/kubernetes/cert/ca.pem \
--cert=/etc/etcd/cert/etcd.pem \
--key=/etc/etcd/cert/etcd-key.pem
version
4.1 etcd V3命令
| 命令 | 用法 | 说明 | 可选参数 |
|---|---|---|---|
get |
USAGE: etcdctl get [options] <key> [range_end] |
获取一个或一个范围内的键<key>和键值<value> | OPTIONS: --consistency=“l” 线性化(l)或串行化(s) --from-key[=false] 利用byte(字节)进行比较的方式获取大于或等于给定键的键--keys-only[=false] 只获取键,不获取键值--limit=0 显示结果的最大数量--order="" 结果排序,可设置为ASCEND或 DESCEND (默认为ASCEND )--prefix[=false] 获取前缀匹配到的键--print-value-only[=false] 当使用“simple”输出格式时,只写值 --rev=0 指明kv的修订版本 --sort-by="" 按目标排序,可设置的值有CREATE, KEY, MODIFY, VALUE, VERSION |
put |
USAGE: etcdctl put [options] <key> <value> |
设置键<key>和键值<value> | OPTIONS: --ignore-lease[=false] 使用当前租约更新key,key不存在时报错 --ignore-value[=false] 使用key当前的value更新key,key不存在时报错 --lease="0" 请将lease ID(十六进制)附加到key从而指定租约,租约过期key自动删除--prev-kv[=false] 返回修改前的键值对 |
del |
USAGE: etcdctl del [options] <key> [range_end] |
删除键[key]和键值[value] | OPTIONS:--from-key[=false] 利用byte(字节)进行比较的方式删除大于或等于给定键的键--prefix[=false] 删除前缀匹配到的键--prev-kv[=false] 返回已删除的键值对 |
| txn | USAGE:etcdctl txn [options] | Txn处理一个事务中的所有请求 | OPTIONS: -i, --interactive[=false] 在交互模式下输入事务 |
| compaction | USAGE: etcdctl compaction [options] <revision> |
压缩etcd中的事件历史记录 | OPTIONS: --physical[=false] “true”用于等待压缩从物理上删除所有旧修订; |
| alarm disarm | USAGE:etcdctl alarm disarm | 解除所有警报 | - |
| alarm list | USAGE:etcdctl alarm list | 列出所有警报 | - |
| defrag | USAGE:etcdctl defrag | 使用给定端点对etcd成员的存储进行碎片整理 | OPTIONS: --data-dir="" 可选的。如果存在,对etcd不使用的数据目录进行碎片整理。 |
endpoint health |
USAGE:etcdctl endpoint health | 检查--endpoints标志中指定的端点的健康状况 |
- |
endpoint status |
USAGE:etcdctl endpoint status | 打印出--endpoints标志中指定的端点的状态 |
- |
endpoint hashkv |
USAGE:etcdctl endpoint hashkv | 在–endpoints中为每个端点打印KV历史记录 | OPTIONS: --rev=0 最大散列修订(默认:所有修订) |
move-leader |
USAGE: etcdctl move-leader <transferee-member-id> |
将领导转移到另一个etcd集群成员 | - |
watch |
USAGE: etcdctl watch [options] <key or prefix> [range_end] [ --] [exec-command arg1 arg2 …] |
在键或前缀上观察事件流,当监视到时可以执行相应命令 | OPTIONS: -i, --interactive[=false] 进入交互模式 --prefix[=false] 如果设置了前缀,则监视这个前缀--prev-kv[=false] 获取事件发生之前的键值对 --rev=0 开始监视这个修订 |
version |
USAGE:etcdctl version | 输出版本号 | - |
| lease grant | USAGE:etcdctl lease grant <ttl> | 创造租约,可以为key设置超时时间后自动删除key | - |
| lease revoke | USAGE:etcdctl lease revoke <leaseID> | 撤销租约 ,并删除所有关联的key | - |
| lease timetolive | USAGE: etcdctl lease timetolive <leaseID> [options] |
获取租赁信息 | OPTIONS: --keys[=false] 获取附在租约上的键 |
| lease list | USAGE:etcdctl lease list | 列出所有有效租约 | - |
| lease keep-alive | USAGE: etcdctl lease keep-alive [options] <leaseID> |
让租约保持活力(续订) | OPTIONS: --once[=false] 将keep-alive时间重置为其原始值并立即退出 |
member add |
USAGE: etcdctl member add <memberName> [options] |
添加一个成员到集群 | OPTIONS: --peer-urls="" |
member remove |
USAGE: etcdctl member remove <memberID> [options] |
从集群中删除一个成员 | - |
member update |
USAGE: etcdctl member update <memberID> [options] |
在集群中更新一个成员 | OPTIONS: --peer-urls="" |
member list |
USAGE:etcdctl member list | 显示集群内所有成员 | - |
| snapshot save | USAGE: etcdctl snapshot save <filename> |
将etcd节点后端快照存储到给定文件 | - |
| snapshot restore | USAGE: etcdctl snapshot restore <filename> [options] |
将etcd成员快照还原到etcd目录 | OPTIONS: --data-dir="" 数据目录的路径 --initial-advertise-peer-urls=“http://localhost:2380” 此成员要向集群的其余部分发布的对等url列表 --initial-cluster=“default=http://localhost:2380” 用于恢复引导的初始集群配置 --initial-cluster-token=“etcd-cluster” 恢复引导期间etcd集群的初始集群令牌 --name=“default” 此成员的可读名称 --skip-hash-check[=false] 忽略快照完整性散列值(如果从数据目录复制的请求) --wal-dir="" WAL目录的路径(如果没有指定,则使用–data-dir ) |
| snapshot status | USAGE: etcdctl snapshot status <filename> |
获取给定文件的后端快照状态 | - |
| make-mirror | USAGE: etcdctl make-mirror [options] <destination> |
在目标etcd集群中创建镜像 | OPTIONS: --dest-cacert="" 使用此CA包验证启用了TLS的安全服务器的证书 --dest-cert="" 使用此TLS证书文件为目标集群标识安全客户端 --dest-insecure-transport[=true] 为客户端连接禁用传输安全性 --dest-key="" 使用此TLS密钥文件识别安全客户端 --dest-prefix="" 将一个前缀映射到目标集群中的另一个前缀 --no-dest-prefix[=false] 将key-values映射到目标集群的root --prefix="" 到镜像的键值前缀 |
| migrate | USAGE:etcdctl migrate | 将v2存储中的密钥迁移到mvcc存储 | OPTIONS: --data-dir="" 数据目录的路径 --no-ttl[=false] 不转换TTL keys --transformer="" 用户提供的转换器程序的路径 --wal-dir="" 到WAL目录的路径 |
| lock | USAGE: etcdctl lock <lockname> [exec-command arg1 arg2 …] |
获取一个命名锁 | OPTIONS: --ttl=10 会话超时 |
| elect | USAGE: etcdctl elect <election-name> [proposal] |
观察并参与领导人选举 | OPTIONS: -l, --listen[=false] 观察模式 |
auth enable |
USAGE:etcdctl auth enable | 启用身份认证 | - |
auth disable |
USAGE:etcdctl auth disable | 禁用身份认证 | - |
user add |
USAGE: etcdctl user add <user name or user:password> [options] |
添加一个新用户 | OPTIONS: --interactive[=true] 从stdin读取密码,而不是交互式终端 |
user delete |
USAGE: etcdctl user delete <user name> |
删除一个用户 | - |
user get |
USAGE: etcdctl user get <user name> [options] |
获取用户的详细信息 | OPTIONS: --detail[=false] 显示授予用户的角色权限 |
user list |
USAGE:etcdctl user list | 显示所有用户 | - |
user passwd |
USAGE: etcdctl user passwd <user name> [options] |
更改用户密码 | OPTIONS: --interactive[=true] 如果是true则从stdin读取密码,而不是交互式终端 |
user grant-role |
USAGE: etcdctl user grant-role <user name> <role name> |
授予用户角色 | - |
user revoke-role |
USAGE: etcdctl user revoke-role <user name> <role name> |
撤消用户的角色 | - |
role add |
USAGE:etcdctl role add <role name> | 添加新角色 | - |
role delete |
USAGE:etcdctl role delete <role name> | 删除一个角色 | - |
role get |
USAGE:etcdctl role get <role name> | 获取角色的详细信息 | - |
role list |
USAGE:etcdctl role list | 显示所有角色 | - |
| role grant-permission | USAGE: etcdctl role grant-permission [options] <role name> <permission type> <key> [endkey] |
授予钥密给角色 | OPTIONS: --from-key[=false] 利用byte(字节)进行比较的方式授予大于或等于给定键的键的权限 --prefix[=false] 授予前缀匹配到的键的权限 |
| role revoke-permission | USAGE: etcdctl role revoke-permission <role name> <key> [endkey] |
从角色中撤消密钥 | OPTIONS: --from-key[=false] 利用byte(字节)进行比较的方式撤销大于或等于给定键的键的权限 --prefix[=false] 撤销前缀匹配到的键的权限 |
| check perf | USAGE:etcdctl check perf [options] | 检查etcd集群的性能 | OPTIONS: --load=“s” 性能检查的工作负载模型。可接受的工作负载:s(小)、m(中)、l(大)、xl(xLarge) --prefix="/etcdctl-check-perf/" 写入性能检查键的前缀。 |
| help | USAGE:etcdctl help [command] | 帮助信息 | - |
4.2 etcd V3命令全局参数
| 全局参数 | 说明 |
|---|---|
| --cacert="" | 使用CA包验证启用了tls的安全服务器的证书 |
| --cert="" | 使用此TLS证书文件识别安全客户端 |
| --command-timeout=5s | 短时间运行命令超时(不包括拨号超时) |
| --debug[=false] | 启用客户端调试日志记录 |
| --dial-timeout=2s | 客户端连接的拨号超时 |
| -d, --discovery-srv="" | 要查询描述集群端点的SRV记录的域名 |
| --endpoints=[127.0.0.1:2379] | gRPC端点 |
| --hex[=false] | 将字节字符串打印为十六进制编码的字符串 |
| --insecure-discovery[=true] | 接受描述集群端点的不安全SRV记录 |
| --insecure-skip-tls-verify[=false] | 跳过服务器证书验证 |
| --insecure-transport[=true] | 为客户端连接禁用传输安全性 |
| --keepalive-time=2s | 保持客户端连接的存活时间 |
| --keepalive-timeout=6s | 保持客户端连接的超时 |
| --key="" | 使用此TLS密钥文件识别安全客户端 |
| --user="" | 用于身份验证的用户名[:password](如果没有提供密码,则提示) |
| -w, --write-out=“simple” | 设置输出格式 (fields, json, protobuf, simple, table) |
二、etcd组件部署
本次搭建的基础环境:操作系统centos7(已安装docker)
1、采用镜像的方式部署etcd
首先在服务器上先下载最新的etcd镜像,可在docker Hub官网上搜索etcd,寻找最新的etcd镜像下载。
本次使用的镜像是quay.io/coreos/etcd;
可在操作系统上执行docker pull quay.io/coreos/etcd来下载镜像,如下图所示:
1.1 将服务器添加进集群(etcd)的两种方式
- 接下来我采用了如下两种方式来创建集群:
- 将三个服务器挨个添加进集群
- 将三个服务器统一添加进集群
1.1.1 将服务器挨个添加进集群(etcd)
1.在服务器A(172.27.0.42)上运行一个ETCD实例,取名为etcd01,注意其状态为new,“-initial-cluster”中只有自己的IP:
docker run -d -p 2379:2379 -p 2380:2380 --name etcd01 quay.io/coreos/etcd:latest etcd --name etcd01 --advertise-client-urls http://172.27.0.42:2379 --listen-client-urls http://0.0.0.0:2379 --initial-advertise-peer-urls http://172.27.0.42:2380 --listen-peer-urls http://0.0.0.0:2380 --initial-cluster-token etcd-cluster --initial-cluster etcd01=http://172.27.0.42:2380 --initial-cluster-state new

2.在服务器A的ETCD服务上,通过调用API添加一个新的节点B(172.27.0.16):
curl http://127.0.0.1:2379/v2/members -XPOST -H “Content-Type: application/json” -d ‘{“peerURLs”: [“http://172.27.0.16:2380”]}’

3.在服务器B(172.27.0.16)上运行一个ETCD实例,取名为etcd02,注意其状态为existing,“-initial-cluster”中有前一个IP及自己的IP:
docker run -d -p 2379:2379 -p 2380:2380 --name etcd02 quay.io/coreos/etcd:latest etcd --name etcd02 --advertise-client-urls http://172.27.0.16:2379 --listen-client-urls http://0.0.0.0:2379 --initial-advertise-peer-urls http://172.27.0.16:2380 --listen-peer-urls http://0.0.0.0:2380 --initial-cluster-token etcd-cluster --initial-cluster etcd01=http://172.27.0.42:2380,etcd02=http://172.27.0.16:2380 --initial-cluster-state existing

4.在服务器A的ETCD服务上,通过调用API添加一个新的节点C(172.27.0.39):
curl http://127.0.0.1:2379/v2/members -XPOST -H “Content-Type: application/json” -d ‘{“peerURLs”: [“http://172.27.0.39:2380”]}’

5.在服务器C(172.27.0.39)上运行一个ETCD实例,取名为etcd03,注意其状态为existing,“-initial-cluster”中有前一个IP及自己的IP:
docker run -d -p 2379:2379 -p 2380:2380 --name etcd03 quay.io/coreos/etcd:latest etcd --name etcd03 --advertise-client-urls http://172.27.0.39:2379 --listen-client-urls http://0.0.0.0:2379 --initial-advertise-peer-urls http://172.27.0.39:2380 --listen-peer-urls http://0.0.0.0:2380 --initial-cluster-token etcd-cluster --initial-cluster etcd01=http://172.27.0.42:2380,etcd02=http://172.27.0.16:2380,etcd03=http://172.27.0.39:2380 --initial-cluster-state existing

1.1.2 将服务器统一添加进集群(etcd)
- 注意:“-initial-cluster”中包含所有节点的IP,状态均为new;
A(172.27.0.42)上执行:
docker run -d -p 2379:2379 -p 2380:2380 --name etcd01 quay.io/coreos/etcd:latest etcd --name etcd01 --advertise-client-urls http://172.27.0.42:2379 --listen-client-urls http://0.0.0.0:2379 --initial-advertise-peer-urls http://172.27.0.42:2380 --listen-peer-urls http://0.0.0.0:2380 --initial-cluster-token etcd-cluster --initial-cluster etcd01=http://172.27.0.42:2380,etcd02=http://172.27.0.16:2380,etcd03=http://172.27.0.39:2380 --initial-cluster-state new
B(172.27.0.16)上执行:
docker run -d -p 2379:2379 -p 2380:2380 --name etcd02 quay.io/coreos/etcd:latest etcd --name etcd02 --advertise-client-urls http://172.27.0.16:2379 --listen-client-urls http://0.0.0.0:2379 --initial-advertise-peer-urls http://172.27.0.16:2380 --listen-peer-urls http://0.0.0.0:2380 --initial-cluster-token etcd-cluster --initial-cluster etcd01=http://172.27.0.42:2380,etcd02=http://172.27.0.16:2380,etcd03=http://172.27.0.39:2380 --initial-cluster-state new
C(172.27.0.39)上执行:
docker run -d -p 2379:2379 -p 2380:2380 --name etcd03 quay.io/coreos/etcd:latest etcd --name etcd03 --advertise-client-urls http://172.27.0.39:2379 --listen-client-urls http://0.0.0.0:2379 --initial-advertise-peer-urls http://172.27.0.39:2380 --listen-peer-urls http://0.0.0.0:2380 --initial-cluster-token etcd-cluster --initial-cluster etcd01=http://172.27.0.42:2380,etcd02=http://172.27.0.16:2380,etcd03=http://172.27.0.39:2380 --initial-cluster-state new
1.1.3 etcd验证
两种方法部署的etcd可通过以下方式进行验证是否成功:
1.验证集群members,在集群中的每台机器上查看members,得出的结果应该是相同的;
curl -L http://127.0.0.1:2379/v2/members

2.可在任一服务器上进入etcd容器执行命令etcdctl member list或etcdctl cluster-health验证;

3.某台机器上添加数据,其他机器上查看数据,得出的结果应该是相同的,例如:
A上执行:curl -L http://127.0.0.1:2379/v2/keys/message -XPUT -d value=“Hello World”

B、C上执行:curl -L http://127.0.0.1:2379/v2/keys/message

2、采用本地方式部署etcd
环境:
| 服务器名称 | 服务器ip |
|---|---|
| etcd01 | 172.27.18.9 |
| etcd02 | 172.27.17.220 |
| etcd03 | 172.27.16.105 |
安装方式:
- 通过下载etcd安装包安装,可执行wget https://github.com/etcd-io/etcd/releases/download/v3.3.13/etcd-v3.3.13-linux-amd64.tar.gz
- linux系统一般都有自带etcd安装包,可直接使用yum安装,如yum install etcd -y
目前我这里采用的是直接通过yum install etcd -y 安装, yum安装的etcd默认的配置文件为/etc/etcd/etcd.conf,文件如下:
[root@VM_18_9_centos /]# cat /etc/etcd/etcd.conf
#[Member]
#ETCD_CORS=""
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
#ETCD_WAL_DIR=""
#ETCD_LISTEN_PEER_URLS="http://localhost:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379"
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
ETCD_NAME="default"
#ETCD_SNAPSHOT_COUNT="100000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
#ETCD_QUOTA_BACKEND_BYTES="0"
#ETCD_MAX_REQUEST_BYTES="1572864"
#ETCD_GRPC_KEEPALIVE_MIN_TIME="5s"
#ETCD_GRPC_KEEPALIVE_INTERVAL="2h0m0s"
#ETCD_GRPC_KEEPALIVE_TIMEOUT="20s"
#
#[Clustering]
#ETCD_INITIAL_ADVERTISE_PEER_URLS="http://localhost:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379"
#ETCD_DISCOVERY=""
#ETCD_DISCOVERY_FALLBACK="proxy"
#ETCD_DISCOVERY_PROXY=""
#ETCD_DISCOVERY_SRV=""
#ETCD_INITIAL_CLUSTER="default=http://localhost:2380"
#ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
#ETCD_INITIAL_CLUSTER_STATE="new"
#ETCD_STRICT_RECONFIG_CHECK="true"
#ETCD_ENABLE_V2="true"
#
#[Proxy]
#ETCD_PROXY="off"
#ETCD_PROXY_FAILURE_WAIT="5000"
#ETCD_PROXY_REFRESH_INTERVAL="30000"
#ETCD_PROXY_DIAL_TIMEOUT="1000"
#ETCD_PROXY_WRITE_TIMEOUT="5000"
#ETCD_PROXY_READ_TIMEOUT="0"
#
#[Security]
#ETCD_CERT_FILE=""
#ETCD_KEY_FILE=""
#ETCD_CLIENT_CERT_AUTH="false"
#ETCD_TRUSTED_CA_FILE=""
#ETCD_AUTO_TLS="false"
#ETCD_PEER_CERT_FILE=""
#ETCD_PEER_KEY_FILE=""
#ETCD_PEER_CLIENT_CERT_AUTH="false"
#ETCD_PEER_TRUSTED_CA_FILE=""
#ETCD_PEER_AUTO_TLS="false"
#
#[Logging]
#ETCD_DEBUG="false"
#ETCD_LOG_PACKAGE_LEVELS=""
#ETCD_LOG_OUTPUT="default"
#
#[Unsafe]
#ETCD_FORCE_NEW_CLUSTER="false"
#
#[Version]
#ETCD_VERSION="false"
#ETCD_AUTO_COMPACTION_RETENTION="0"
#
#[Profiling]
#ETCD_ENABLE_PPROF="false"
#ETCD_METRICS="basic"
#
#[Auth]
#ETCD_AUTH_TOKEN="simple"
[root@VM_18_9_centos /]#
在etcd01(172.27.18.9)修改etcd.conf启动参数,执行vim /etc/etcd/etcd.conf来修改,修改内容如下:
ETCD_DATA_DIR="/data/etcd.etcd" # 存放etcd数据的路径,注意使用新目录时需要先创建该目录
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" # 监听的用于客户端通信的url,同样可以监听多个。
ETCD_NAME="etcd01" # etcd集群中的节点名,这里可以随意,可区分且不重复就行
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" # 监听的用于节点之间通信的url,可监听多个,集群内部将通过这些url进行数据交互(如选举,数据同步等)
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://172.27.18.9:2380" # 建议用于节点之间通信的url,节点间将以该值进行通信。
ETCD_ADVERTISE_CLIENT_URLS="http://172.27.18.9:2379" # 建议使用的客户端通信url,该值用于etcd代理或etcd成员与etcd节点通信。
ETCD_INITIAL_CLUSTER="etcd01=http://172.27.18.9:2380,etcd02=http://172.27.17.220:2380,etcd03=http://172.27.16.105:2380" # 也就是集群中所有的initial-advertise-peer-urls 的合集
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" # 节点的token值,设置该值后集群将生成唯一id,并为每个节点也生成唯一id,当使用相同配置文件再启动一个集群时,只要该token值不一样,etcd集群就不会相互影响。
ETCD_INITIAL_CLUSTER_STATE="new" # 新建集群的标志,初始化状态使用 new,建立之后改此值为 existing
修改完etcd.conf文件后还需要修改/usr/lib/systemd/system/etcd.service服务文件的ExecStart部分,与etcd.conf修改的相对应,修改内容如下所示:
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
EnvironmentFile=-/etc/etcd/etcd.conf
ExecStart=/bin/bash -c "GOMAXPROCS=$(nproc) /usr/bin/etcd \
--name=${ETCD_NAME} \
--listen-client-urls=${ETCD_LISTEN_CLIENT_URLS} \
--listen-peer-urls=${ETCD_LISTEN_PEER_URLS} \
--advertise-client-urls=${ETCD_ADVERTISE_CLIENT_URLS} \
--initial-advertise-peer-urls=${ETCD_INITIAL_ADVERTISE_PEER_URLS} \
--initial-cluster=${ETCD_INITIAL_CLUSTER} \
--initial-cluster-token=${ETCD_INITIAL_CLUSTER_TOKEN} \
--initial-cluster-state=new"
User=etcd
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
然后执行systemctl start etcd.service启动服务,然后执行etcdctl member listf返回类似如下信息则配置成功;

etcd02、etcd03服务器部署同etcd01一致,只需要把ETCD_NAME、ETCD_ADVERTISE_CLIENT_URLS和ETCD_INITIAL_ADVERTISE_PEER_URLS换成etcd02或etcd03的配置即可;
- 注意:如执行etcdctl member listf报错如下,则是因为ETCD_LISTEN_CLIENT_URLS没有配置http://127.0.0.1:2379与本机自己进行通信导致的,配上后重启etcd服务即可。

本文仅是个人学习时的整理收藏,以便回顾所用,内容均来源其它处。
[参考文档]https://www.cnblogs.com/datacoding/p/7473953.html
[参考文档]https://blog.csdn.net/yasonan/article/details/54945066
[参考文档]https://www.kubernetes.org.cn/tags/etcd
