1算法原理
OCR 的基本原理可分为:图像预处理、图像分割、字符识别和识别结果处理四个部分(如下图)。

1.1 图像预处理
对包含文字的图像进行处理以便后续进行特征提取、学习。这个过程的主要目的是减少图像中的无用信息,以便方便后面的处理。在这个步骤通常有:灰度化、降噪、二值化、字符切分以及归一化等子步骤。经过二值化后,图像只剩下 黑和白两种颜色。降噪在这个阶段非常重要,降噪算法的好坏对特征提取的影响 很大。字符切分则是将图像中的文字分割成单个文字——识别的时候是一个字一 个字识别的。如果文字行有倾斜的话往往还要进行倾斜校正。归一化则是将单个的文字图像规整到同样的尺寸,在同一个规格下,才能应用统一的算法。
1.2 图像分割
图像预处理之后,进行图像分割,常用的方法有阈值分割或边缘分割等方法。
·阈值分割:灰度阈值分割法是一种最常用的并行区域技术,它是图像分割中应用数量最多的一类。阈值分割方法实际上是输入图像 f 到输出图像 g 的如下变换:
其中, T 为 阈 值 ,对 于 物 体 的 元素G(i,j)=1 ,对 于 背 景 的 图 像 元 素 G(i,j)=0 。 由此可见,阈值分割算法的关键是确定阈值,如果能确定一个合适的阈值就可准 确地将图像分割开来。阈值确定后,将阈值与像素点的灰度值逐个进行比较,而 且像素分割可对各像素并行地进行,分割的结果直接给出图像区域。阈值分割的 优点是计算简单、运算效率较高、速度快。
·边缘分割:图像分割的一种重要途径是通过边缘检测,即检测灰度级或者结构具有突变的地方。这种不连续性称为边缘。不同的图像灰度不同,边界处一般有明显的边缘,利用此特征可以分割图像。 图像中边缘处像素的灰度值不连续,这种不连续性可通过求导数来检测到。 对于阶跃状边缘,其位置对应一阶导数的极值点,对应二阶导数的过零点。因此 常用微分算子进行边缘检测,常用的一阶微分算子有 Roberts 算子、Prewitt 算 子和 Sobel 算子,二阶微分算子有 Laplace 算子和 Kirsh 算子等。利用Laplace算子锐化结果如下:
 其中T表示阈值常数。
其中T表示阈值常数。
在实际中各种微分算子常用小区域模板来表示,微分运算是利用模板和图像 卷积来实现。这些算子对噪声敏感,只适合于噪声较小不太复杂的图像。由于边 缘和噪声都是灰度不连续点,在频域均为高频分量,直接采用微分运算难以克服 噪声的影响。因此用微分算子检测边缘前要对图像进行平滑滤波。LoG 算子和 Canny 算子是具有平滑功能的二阶和一阶微分算子,边缘检测效果较好。其中 loG 算子是采用 Laplacian 算子求高斯函数的二阶导数,Canny 算子是高斯函数的一 阶导数,它在噪声抑制和边缘检测之间取得了较好的平衡。
1.3 特征提取和降维
特征是用来识别文字的关键信息,每个不同的文字都能通过特征来和其他文字进行区分。对于数字和英文字母来说,数据集比较小,数字有 10 个,英文字母有 52 个。对于汉字来说,特征提取比较困难,因为首先汉字是大字符集,国标中光是最常用的第一级汉字就有 3755 个;第二个汉字结构复杂,形近字多。 在确定了使用何种特征后,还有可能要进行特征降维,这种情况就是如果特征的维数太高,分类器的效率会受到很大的影响,为了提高识别速率,往往就要进行降维。 一种较通用的特征提取方法是 HOG。HOG 是方向梯度直方图,这里分解为方向梯度与直方图。具体做法是首先用[-1,0,1]梯度算子对原图像做卷积运算,得到 x 方向的梯度分量 gradscalx,然后用[1,0,-1]T 梯度算子对原图像做卷积运算,得到 y 方向的梯度分量 gradscaly。然后再用以下公式计算该像素点的梯度大小和方向:
 Gx(x,y)、Gx(x,y)、H(x,y)分别表示输入图像像素点 ( x,y) 处的水平方向梯度、垂直方向梯度和像素值。像素点( x,y ) 处的梯度幅值和梯度方向分别为:
Gx(x,y)、Gx(x,y)、H(x,y)分别表示输入图像像素点 ( x,y) 处的水平方向梯度、垂直方向梯度和像素值。像素点( x,y ) 处的梯度幅值和梯度方向分别为:  下一步是为局部图像区域提供一个编码,可以将图像分成若干个“单元格 cell”。我们采用 n 个扇形的直方图来统计这单元格的梯度信息,也就是将 cell 的梯度方向 360 度分成 n 个方向块,如下图:
下一步是为局部图像区域提供一个编码,可以将图像分成若干个“单元格 cell”。我们采用 n 个扇形的直方图来统计这单元格的梯度信息,也就是将 cell 的梯度方向 360 度分成 n 个方向块,如下图:
 这样,对 cell 内每个像素用梯度方向在直方图中进行加权投影(映射到固 定的角度范围),梯度大小就是投影的权值。然后把细胞单元组合成大的块 (block),块内归一化梯度直方图。我们将归一化之后的块描述符(向量)称 之为 HOG 描述符,即这个 cell 对应的 n 维特征向量。 最后一步就是将检测窗口中所有重叠的块进行 HOG 特征的收集,并将它们 结合成最终的特征向量供分类使用。
这样,对 cell 内每个像素用梯度方向在直方图中进行加权投影(映射到固 定的角度范围),梯度大小就是投影的权值。然后把细胞单元组合成大的块 (block),块内归一化梯度直方图。我们将归一化之后的块描述符(向量)称 之为 HOG 描述符,即这个 cell 对应的 n 维特征向量。 最后一步就是将检测窗口中所有重叠的块进行 HOG 特征的收集,并将它们 结合成最终的特征向量供分类使用。
1.4 分类器设计
分类器是用来进行识别的,对于上一步,对一个文字图像,提取出特征值,传输给分类器,分类器就对其进行分类,输出这个特征该识别成哪个文字。一种简单的分类器器是模板匹配方法,它使用图像的相似度来进行文字识别,两图像的相似程度可以用以下方程表示:
其中A,B为图像矩阵。选取相关度最大的max{ri}作为最终输出结果。
得到结果后,我们有时需要对对识别结果处理,又称后处理。首先,分类器的分类有时候不一定是完全正确的,比如汉字中由于形近字的存在,很容易将一个字识别成其形近字。后处理中可以去解决这个问题,比如通过语言模型来进行校正——如果分类器将“在哪里”识别成“存哪里”,通过语言模型会发现“存哪里”是错误的,然后进行校正。第二个,OCR的识别图像往往是有大量文字的,而且这些文字存在排版、字体大小等复杂情况,后处理中可以尝试去对识别结果进行格式化。
2 算法步骤
| 步骤 | 实现功能 |
|---|---|
| 0 | 输入灰度或彩色图像 |
| 1 | 计算自适应阈值 |
| 2 | 获得二进制图像 |
| 3 | 进行连接成分分析 |
| 4 | 查找文字行和单词 |
| 5 | 识别字符轮廓 |
| 6 | 处理字体识别结果 |
| 7 | 输出识别的文本 |
3 python tesseract库原理
4算法代码
4.1 识别英文
# 导入PIL,pytesseract库
from PIL import Image
from pytesseract import image_to_string
# 读取待识别的图片
image = Image.open("5.jpg");
# 将图片识别为英文文字
text = image_to_string(image)
# 输出识别的文字
print(text)
4.2 中文段落识别
# 导入PIL,pytesseract库
from PIL import Image
from pytesseract import image_to_string
# 读取待识别的图片
image = Image.open("5.jpg");
# 将图片识别为英文文字
text = image_to_string(image)
# 输出识别的文字
print(text)
5 识别结果展示
5.1 英文识别
待识别英文图片

识别结果

5.2 中文识别
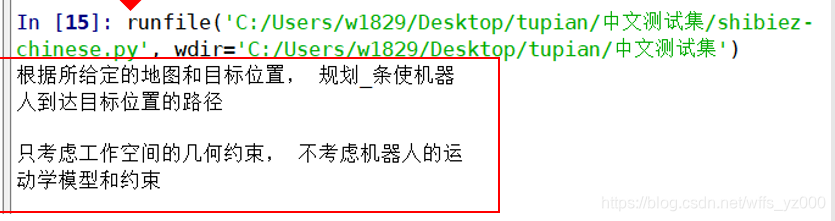
(1)待识别图片

识别结果
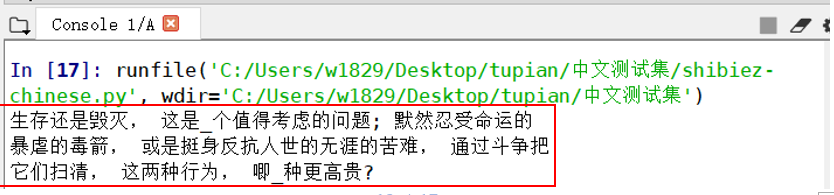
(2)待识别图片2

识别结果
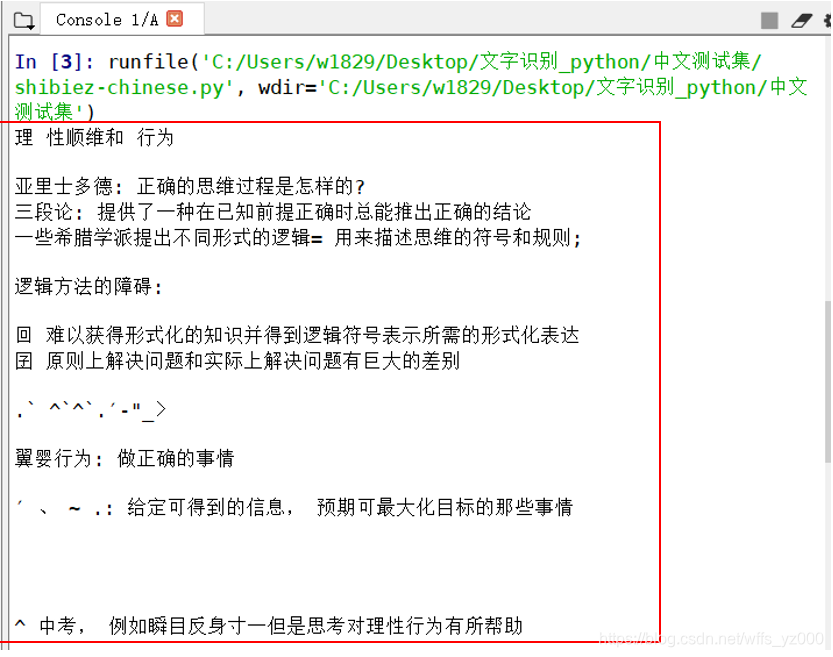
(3)这个库很强大,甚至可以识别带色彩背景的图片

识别结果
如果这篇文章对您有用别忘了点赞哦!
