环境
Python 3.6.6
MacOS 10.14.6
pip 19.0.1
mac版的tesseract 4.1.0
pip的tesseract 0.3.0
安装
1.安装python的OCR库
pip install pytesseract
2.在MacOS的终端上安装tesseract,命令:
brew install tesseract
3.下载OCR语言模型
比如:中文是chi_sim.traineddata 文件,下载后,复制到该目录下
/usr/local/Cellar/tesseract/4.1.0/share/tessdata/

4.查看该tesseract所下载后支持的所有的可用语言
tesseract --list-langs

使用
from PIL import Image
import pytesseract
resDict = pytesseract.image_to_boxes(Image.open('images/example3.png'), lang='chi_sim')
print(resDict)
识别结果是:
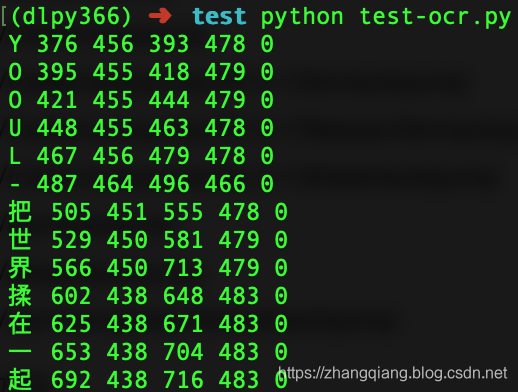
原图片是:

另一个测试案例
原图

代码不变,修改图片名,结果是:
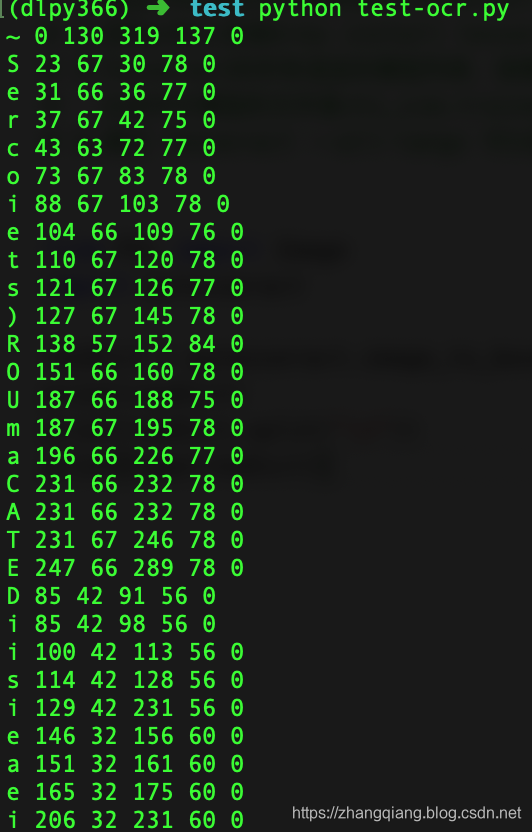
错的离谱!!
在来一个实例
原图片:

代码:
from PIL import Image
import pytesseract
resDict = pytesseract.image_to_boxes(Image.open('images/example4.png'), lang="eng")
arrLetters = resDict.split("\n")
sentence = ""
for letters in arrLetters:
sentence += letters.split(" ")[0]
print(sentence)
识别结果是

识别的精准度还不错,但是我们在拼接句子的时候,不知道在哪里空格,每个单词与单词之间是有间距的,这个就难以控制
