Apache Flume
关于Flume
Hadoop的宗旨是处理大型数据集。通常,我们假设这些数据已经存储在HDFS中,但是如果数据不再HDFS怎么办?
设计Flume的宗旨是向Hadoop批量导入基于事件的海量数据。
Flueme通常用来向Hadoop导入日志文件。
1.安装Flume
①首先下载并解压Apache Flume
http://flume.apache.org/download.html
这里我下载的是( apache-flume-1.9.0-bin.tar.gz)
②为了方便起见我们把flume添加到path,如下图所示(12行和13行内容),我们可以在~/.bash_profile文件中进行配置。
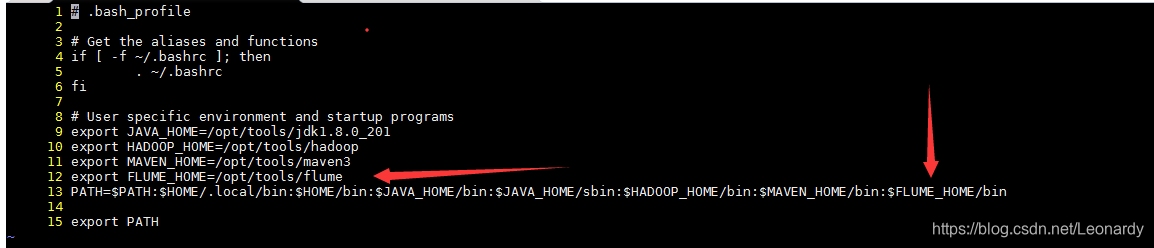
配置之后为了能够立即生效,我们还如要让系统重读配置文件。
source ~/.bash_profile
然后,可以用Flume-ng命令启动Flume代理。(指定help参数来查看帮助信息)
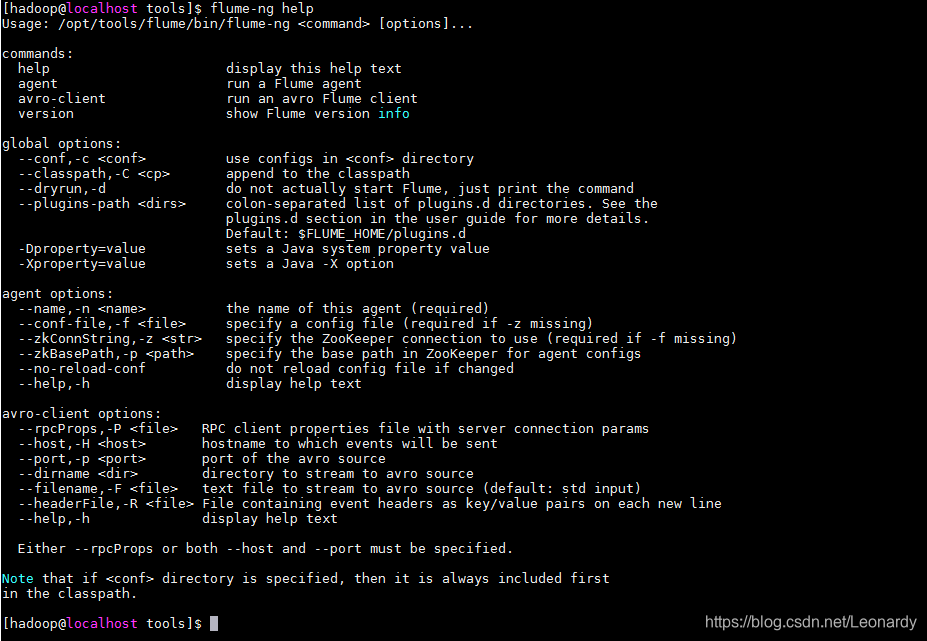
2.Flume样例
①创建一个文件夹,用flume来监视,如果文件夹内有新文件被添加,那么flume会把它的每一行内容输出到控制台。
mkdir /tmp/spooldir
②我们还需要一个flume的配置文件。这里我把它命名为`spool-to-logger.properties,文件内容如下:
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
agent1.sources.source1.channels=channel1
agent1.sinks.sink1.channel=channel1
// type=spooldir用来监视缓冲目录中的新增文件。
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/tmp/spooldir
// type=logger用于将事件记录输出到控制台。
agent1.sinks.sink1.type=logger
agent1.channels.channel1.type=file
③配置好以上内容后,我们用命令来启动flume代理。
flume-ng agent \
--conf-file flume/conf/spool-to-logger.properties <--之前的配置文件
--name agent1 <--配置文件中的代理名
--conf $FLUME_HOME/conf <--flume的通用配置(环境变量等)
-Dflume.root.logger=INFO,console
④在①创建的文件夹中添加一个文件
(※注:Spooling directory source不允许修改文件,因此,为了防止source读取的文件内容不完全,我们先把内容写到隐藏文件中,待内容录入完毕之后再修改为普通文件。)
echo "Hello Flume" > /tmp/spooldir/.loggerTest.txt
mv /tmp/spooldir/.loggerTest.txt /tmp/spooldir/loggerTest.txt
如下,待flume将该文件导入HDFS后,会将该文件重命名为*.COMPLETED,表示flume已经完成文件处理,并且对它不会再做任何操作。

3.事务和可靠性
Flume使用两个独立的事务,分别负责从source到channel以及从channel到sink的事件传递。
①source-channel事务:
在前面的例子中,事务spool directory source为文件的每一行创建一个事件。一旦事务中的所有事件都传到channel且提交成功,那么source就将该文件标记为完成。
②channel-sink事务:
同①的处理类似,如果由于某种原因导致事件无法记录,那么事件将会回滚,而所有的事件仍将留在channel中,等待重新传递。
上面的例子使用的是channel.type是file,这种类型的channel具有永久性:只要事件被成功写入channel,即使代理重新启动,事件也不会丢失。于此相对的还有memory channel,顾名思义,是讲事件缓存到内存中,但是如果代理重启,则事件将会丢失。具体使用哪种channel取决于应用,memory channel的好处在于,比file channel具有更高的吞吐量。
file channel的source产生的每个事件都会到达sink(至少一次)。不论是source还是sink都有可能产生重复,例如,即使代理重启之前有一部分或全部事件已经被提交到channel,但是在代理重启之后,spooling directory source还是会为所有未完成的文件重新创建事件。同理,代理重新启动后,logger sink也会重新记录那些已经记录但未提交的事件。
采用at-least-once方式时,重复的事件可以在后续的操作来移除。通常,这需要以特定于应用程序的重复数据删除作业写在MapReduce或者Hive中。
※注:这里说一下针对at-least-once机制,遇到的坑。
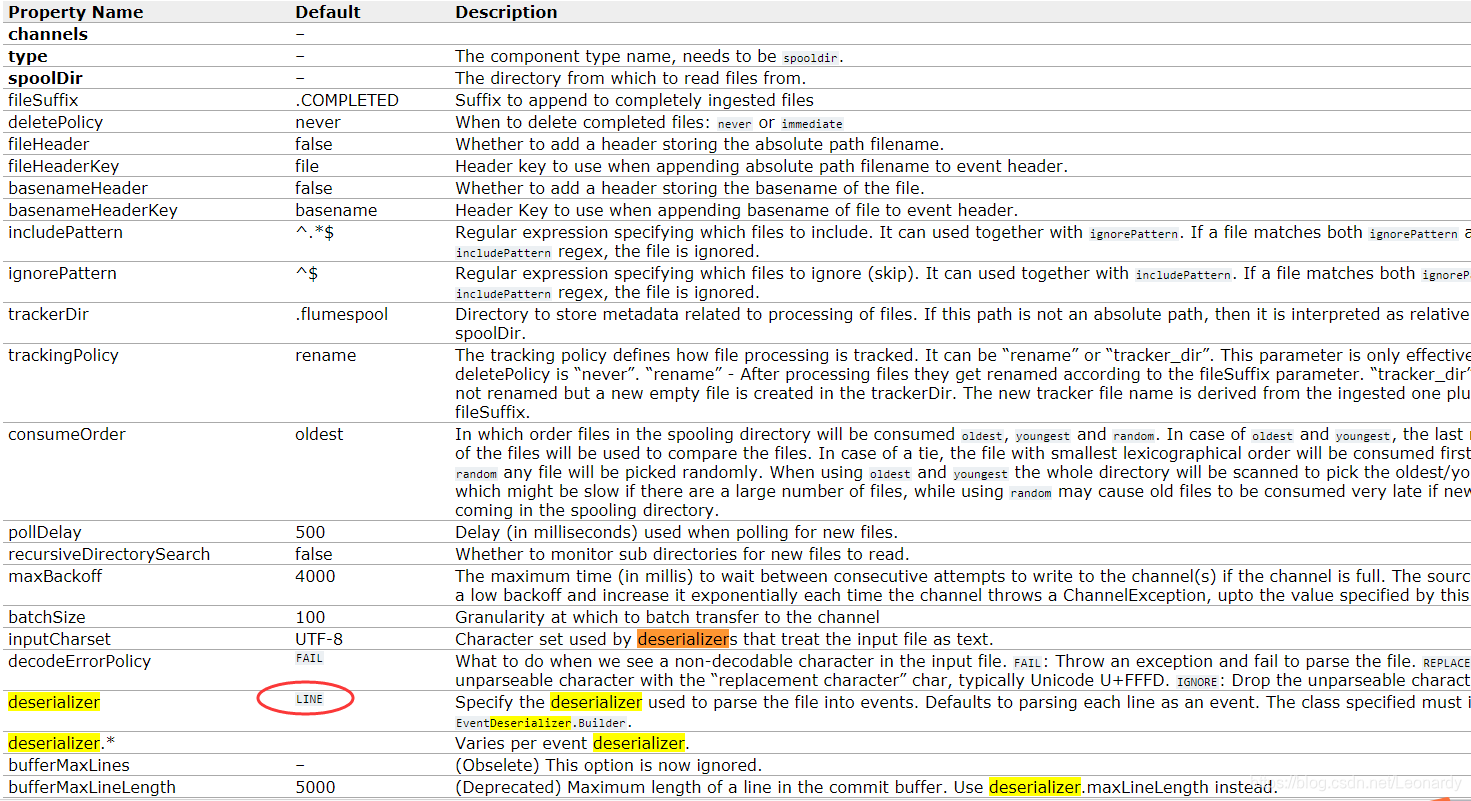
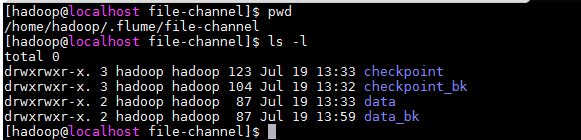
默认情况下,deserializer是 LINE ,也就是逐行生成事件,之前写demo的时候,本想测试一下压缩率,于是用用dd命令创建了一个大小约为 300M的文件(文件内容都是“0”),然后启动完Flume代理就去干活了,结果1个多小时回来一看,sink的输出文件夹内N个小文件,而还在不停的跑,瞬间我就方了,下意识就Ctrl+c了,但是随之而来的问题是,虽然把导出到hdfs的文件都删除了,flume的.properties配置文件也改成了memory channel,甚至重写了不同名称的配置文件,可由于file channel的at-least-once机制,事件已经被写到本地磁盘了,所以只要一启动Flume代理,就会重新执行没成功提交的事件,额,这可如何是好。经过一番资料搜索之后,发现,file channel的事件会存放到本地磁盘的如下位置:

最后,尝试了将~/.flume/file-channel/下的checkpoint文件夹及data文件夹中的内容清空(保险起见,先备份后再清空),再次启动Flume代理,发现之前的事件被清除了。
为了提高效率,Flume在有可能的情况下尽量以事务为单位来批量处理事件,这种方式有尤其利于提高file channel的性能,以为每次事务只需要写一次磁盘和调用一次fsync。
批量的大小取决于组件的类型,并且在大多数情况下是可配的。例如,spooling directory source以100行文本作为一个批次来读取。(可通过BatchSize属性来修改)
4.HDFS sink
Flume关注的重点是向Hadoop数据存储器传递海量数据,下面来演示如何配置Flume代理向HDFS传递sink事件。
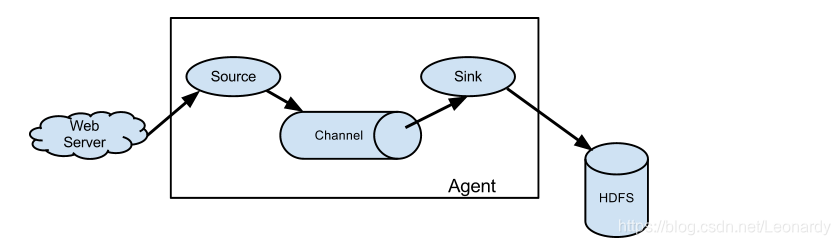
①新建并配置spool-to-hdfs.properties配置文件:
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
agent1.sources.source1.channels=channel1
agent1.sinks.sink1.channel=channel1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/tmp/spooldir
// type为hdfs,意味着sink将会向hdfs导出数据。
agent1.sinks.sink1.type=hdfs
// 导出的文件路径(这里是hdfs的路径,并非根路径,用hdfs dfs -ls /tmp/flume方可查看到)
agent1.sinks.sink1.hdfs.path=/tmp/flume
// 文件的前缀
agent1.sinks.sink1.hdfs.filePrefix=events
// 文件的后缀
agent1.sinks.sink1.hdfs.fileSuffix=.log
// 正在使用中的文件的前缀
agent1.sinks.sink1.hdfs.inUsePrefix=_
// 文件类型
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.channels.channel1.type=file
这里变化的只有sink的信息。也就是说source跟刚才一样,只是输出的地点由console换成了hdfs。
执行下面的命令来启动flume代理。
flume-ng agent \
> --conf-file flume/conf/spool-to-hdfs.properties \
> --conf $FLUME_HOME/conf \
> --name agent1 \
> -Dflume.root.logger=INFO,console
※注:这里需要开启Hdfs守护进程,否则会报错。
source到channel处理完成后source文件被标记为COMPLETED

sink导出的文件会按照.properties文件中设置的前缀后缀等名称来生成对应的文件。

导出到HDFS的文件内容如下

4-1.分区和拦截器
大型数据集经常被组织为分区,这样做的好处是,如果查询只涉及到数据的某个子集,查询过程就可以被限制在特定的分区范围内。Flume事件的数据通常按时间来分区,因此,我们可以定期运行某个进程来对已完成的分区进行数据处理。(比如,前面提到的at-least-once,很可能会导致重复数据,那么就可以在分区内将重复的数据删除。)
对上面的例子稍作修改,便可以达到分区的效果。
①分区信息:
agent1.sinks.sink1.path=/tmp/flume/year=%Y/month=%m/day=%d
这里还需要注意,想要达到分区的效果,还需要配合拦截器:

一个Flume事件被写入哪个分区是由事件的header中的timestamp决定的。默认情况下,header中是没有timestamp的,所以需要通过拦截器来添加。
②Flume拦截器: 一种能够对事件流中的事件进行修改和删除的组件,被附加到source上,在事件传递到channel之前对事件进行处理。
....
agent1.sources.source1.interceptors=interceptor1
agent1.sources.source1.interceptors.interceptor1.type=timestamp
....
※注:这里有个坑,书中内容可能已经落后于新版的Flume,在向hdfs导出使用时间分区时,需要显示的配置hdfs.useLocalTimeStamp=true/false,否则会报错:
(Caused by: java.lang.NullPointerException: Expected timestamp in the Flume event headers, but it was null)

由于拦截器上的时间戳是事件创建时的时间,因此,可能与写入的时间存在明显的差异,尤其是当出现代理停止的情况,这时候可以将hdfs.useTimeStamp设置为true,这时将使用HDFS sink的Flume代理所产生的时间戳。
4-2.文件格式
HDFS sink使用的文件格式由hdfs.fileType以及其他一些属性组合控制,默认为SequenceFile。
①SequenceFile: 由键值对组成,key:LongWritable型,它包含的是时间戳。value:BytesWritable型包含的是时间的body。
通过修改hdfs.writeFormat可以改变value的类型。如,修改为hdfs.writeFormat=Text,则value为Text型。
②Avro文件: hdfs.fileType=DataStream,就像纯文本一样。具体配置如下:
这次我们重新创建一个spool-to-avro.properties配置文件。
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
agent1.sources.source1.channels=channel1
agent1.sinks.sink1.channel=channel1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/tmp/spooldir
// 如上面所说,默认值为LINE,这里目标文件是avro文件,所以需指定为AVRO,否则会报错。
agent1.sources.source1.deserializer=AVRO
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=/tmp/flume
agent1.sinks.sink1.hdfs.filePrefix=events
agent1.sinks.sink1.hdfs.fileSuffix=.avro
agent1.sinks.sink1.hdfs.inUsePrefix=_
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.serializer=avro_event
agent1.sinks.sink1.serializer.compressionCodec=snappy
// memory channel不将事件写入本地磁盘
agent1.channels.channel1.type=memory
