Apache Avro
关于Avro
Apache Avro是一个独立于编程语言的数据化序列系统。该项目由Hadoop之父Doug Cutting创建,旨在解决Hadoop中Writable类型的不足:缺乏语言的可移植性。
1.Avro的特点
- 独立于编程语言。
- 丰富的数据结构类型。
- 快速的可压缩的二进制数据形式。(对MapReduce的输入格式至关重要。)
- Avro可用于RPC。
2.Avro数据类型和Schema
2-1.基本数据类型
| 类型 | 描述 | schema示例 |
|---|---|---|
| null | 空值 | “null” |
| boolean | 二进制值 | “boolean” |
| int | 32位有符号整数 | “int” |
| long | 64位有符号整数 | “long” |
| float | 单精度(32位)IEEE 754浮点数 | “float” |
| double | 双精度(32位)IEEE 754浮点数 | “double” |
| bytes | 8位无符号字节序列 | “bytes” |
| string | Unicode字符序列 | “string” |
2-2.Avro复杂数据类型
| 类型 | 描述 | schema实例 |
|---|---|---|
| array | 已排序的对象集合。 | { “type”: “array”, “items”: “long” } |
| map | 未排序的键值对。key必须是string | |
| record | 一个任意类型的命名字段集合 | { “type”: “record”, “name”:“WeatherRecord”, “doc”: “A weather reading.”, “fields”: [ { “name”:“year”, “type”:“int” }, { “name”:“temperature”, “type”: “int” }, { “name”:“stationId”, “type”: “string” ] } |
| ENUM | 枚举(一组命名值的集合) | { “type”: “enum”, “name”:“Cutlery”, “doc”: “An eating utensil.”, “symbols”: [“KNIFE”, “FORK”,“SPOON”] } |
| fixed | 一组固定数量的8位无符号字节 | { “type”: “fixed”, “name”:“Md5Hash”, “size”: 16 } |
| union | schema的并集(并集可以用JSON数组表示) | [ “null”, “string”, { “type”: “map”, “values”: “string” } ] |
2-3.Avro数据的读/写
2-3-1.基于schema的Avro数据读/写
首先我们需要创建一个以.avsc后缀结尾的schema文件,这里我们命名为StringPair.avsc。
{
"namespace":"schemas",
"name":"StringPair",
"type":"record",
"doc":"This is a String Pair.",
"fields":[
{"name":"left", "type":"string"},
{"name":"right", "type":"string"}
]
}
namespace:可以理解为,文件创建后所在的文件夹名。
name:为文件名称,即类名称,(所以要按照java类的命名规范来命名)。
type:为Avro数据类型。
doc:为文档描述。
fields:为属性信息。
下面就是具体的demo代码:
package avro;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.Schema.Parser;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumReader;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.io.Decoder;
import org.apache.avro.io.DecoderFactory;
import org.apache.avro.io.Encoder;
import org.apache.avro.io.EncoderFactory;
public class AvroDemo {
private ByteArrayOutputStream out = new ByteArrayOutputStream();
private Parser parser = new Schema.Parser();
public static void main(String[] args) throws IOException {
AvroDemo demo = new AvroDemo();
demo.writeAvroData();
demo.readAvroData();
}
public void writeAvroData() throws IOException {
Parser parser = new Schema.Parser();
Schema schema = parser.parse(getClass().getResourceAsStream("/StringPair.avsc"));
GenericRecord datum = new GenericData.Record(schema);
datum.put("left", "L");
datum.put("right", "R");
DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
writer.write(datum, encoder);
encoder.flush();
out.close();
}
public void readAvroData() throws IOException {
Schema schema = parser.parse(getClass().getResourceAsStream("/StringPair.avsc"));
ByteArrayInputStream input = new ByteArrayInputStream(out.toByteArray());
GenericDatumReader<GenericRecord> reader = new GenericDatumReader<GenericRecord>(schema);
Decoder decoder = DecoderFactory.get().binaryDecoder(input, null);
GenericRecord result = reader.read(null, decoder);
input.close();
System.out.println(result.get("left"));
System.out.println(result.get("right"));
}
}
2-3-2.基于schema生成的Avro文件,进行的数据读/写
我们可以通过schema生成StringPair类,有几种方法可以实现,这里以Maven为例。
首先,要通过配置pom.xml文件,得到我们需要的jar(Maven会根据配置信息自动下载所需要的jar文件,具体信息如下)。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>learn.hadoop.eco</groupId>
<artifactId>HadoopEcoTest</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.9.0</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
</execution>
</executions>
<configuration>
<!-- 此处的${project.basedir}为项目路径,之后的路径为你自己的目录结构,具体看下面图片-->
<sourceDirectory>${project.basedir}/src/main/resources</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java</outputDirectory>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>

※注这里配置完成之后会报错,把光标移动到报错的行,按下Ctrl+F1(即可提示快速解决方案↓),任意选一个解决方案,这里我选的第一个解决方案。
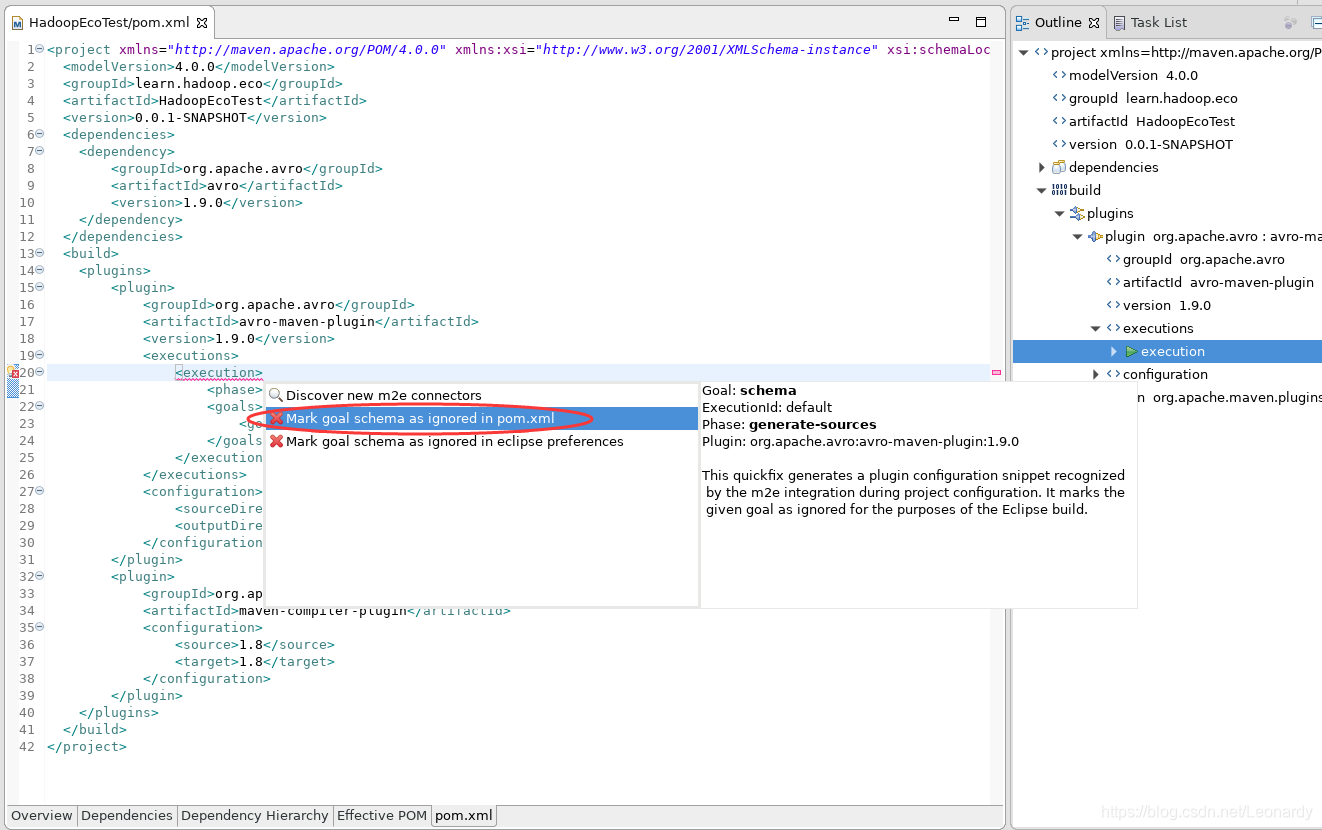
选择解决方案后,pom.xml文件中会自动添加下列内容,文件不再报错,但是如果项目依然报错,解决方法:项目右键→Maven→Upadte Project ...
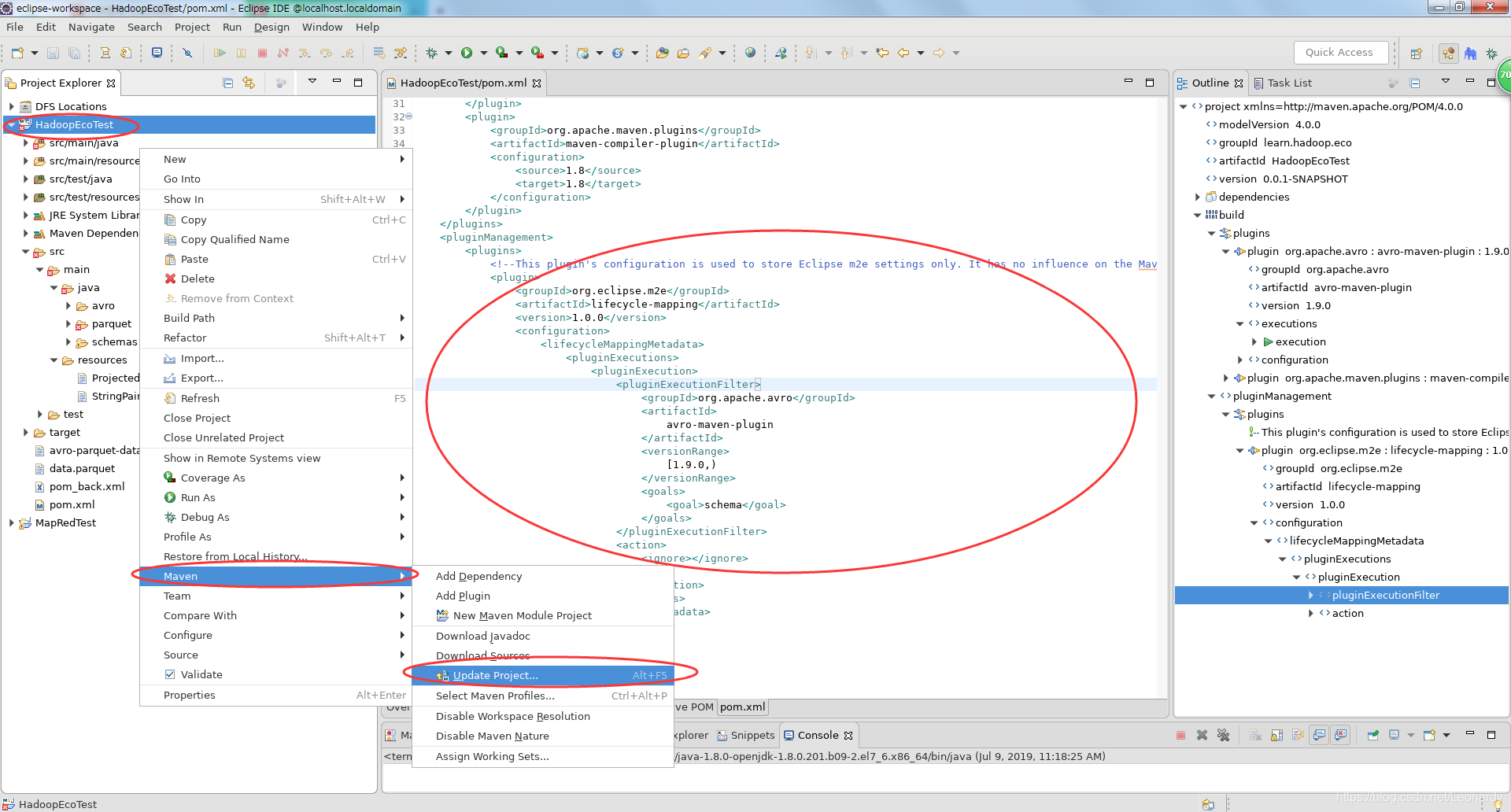
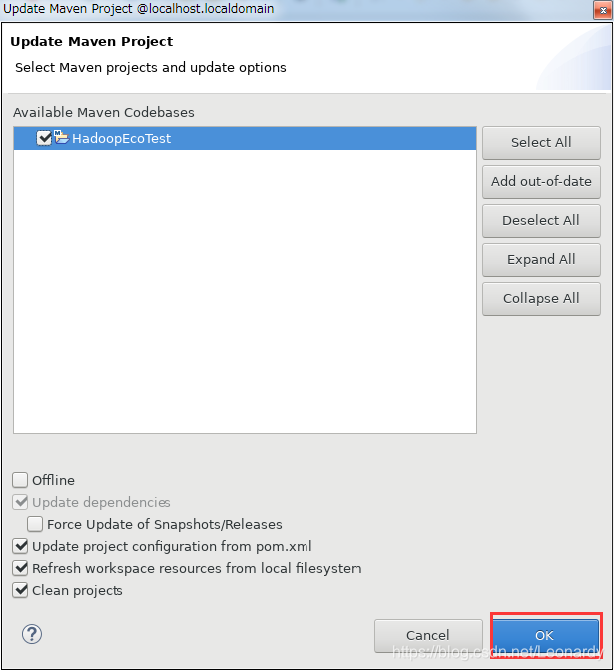
如下状态,点击ok即可。
接下来运行Maven Build生成类文件(Goals为Compile),点击Run,待运行结束后,文件被生成。
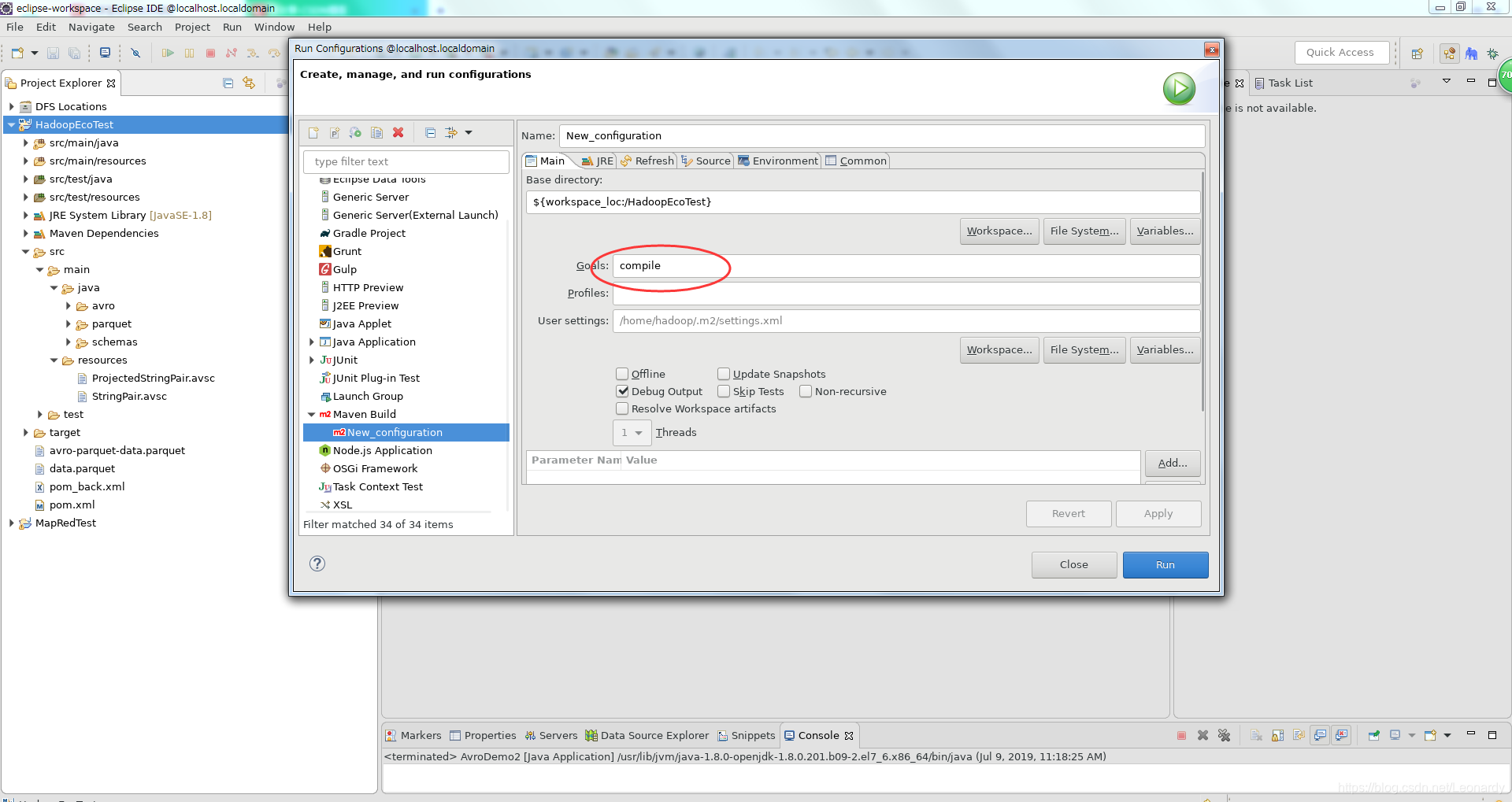
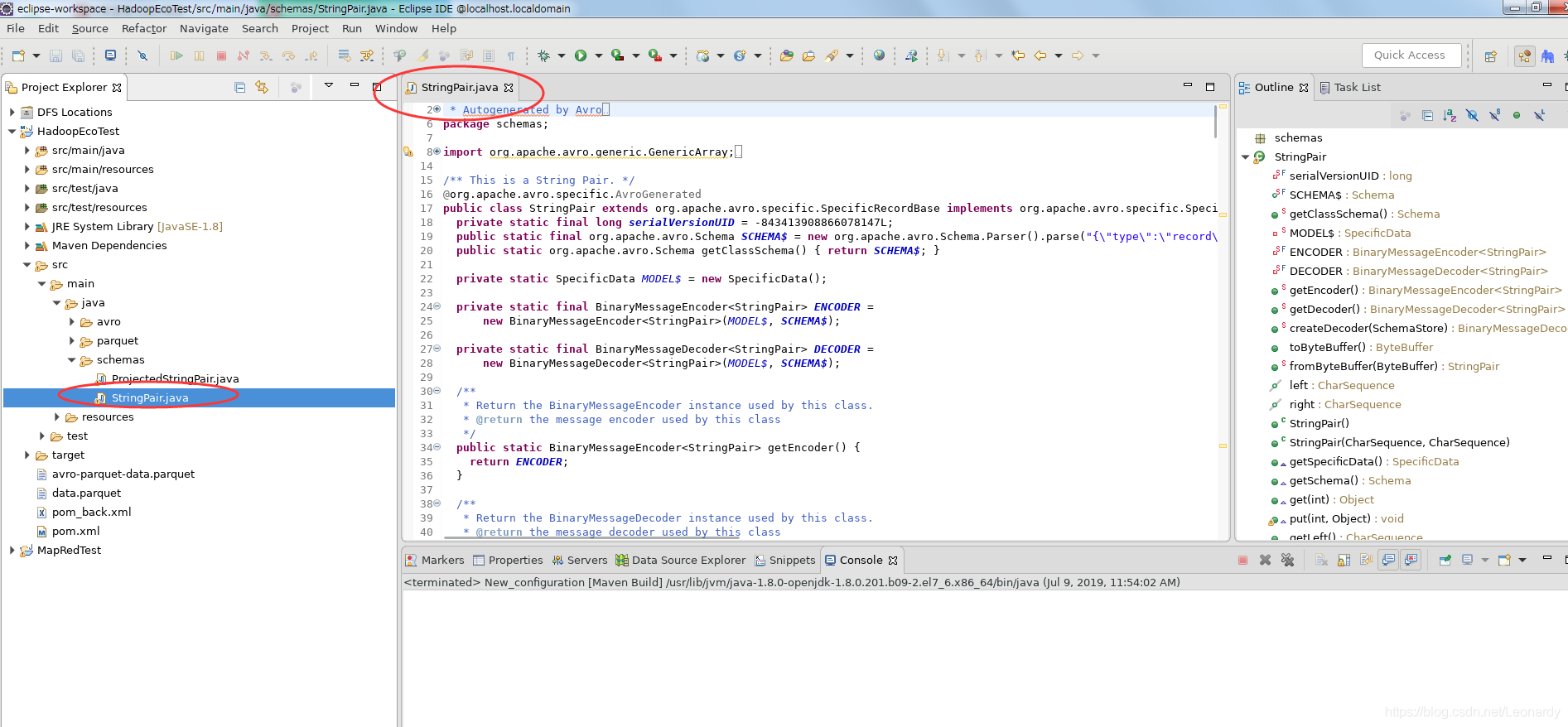
接下来我们将上面的Demo稍作改动,来实现用schema生成的类进行Avro数据的读/写。
package avro;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import org.apache.avro.io.Decoder;
import org.apache.avro.io.DecoderFactory;
import org.apache.avro.io.Encoder;
import org.apache.avro.io.EncoderFactory;
import org.apache.avro.specific.SpecificDatumReader;
import org.apache.avro.specific.SpecificDatumWriter;
import schemas.StringPair;
public class AvroDemo2 {
private ByteArrayOutputStream out = new ByteArrayOutputStream();
public static void main(String[] args) throws IOException {
AvroDemo2 demo = new AvroDemo2();
demo.writeAvroData();
demo.readAvroData();
}
public void writeAvroData() throws IOException {
StringPair datum = new StringPair();
datum.setLeft("Left");
datum.setRight("Right");
SpecificDatumWriter<StringPair> writer = new SpecificDatumWriter<StringPair>(StringPair.class);
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
writer.write(datum, encoder);
encoder.flush();
out.close();
}
public void readAvroData() throws IOException {
ByteArrayInputStream input = new ByteArrayInputStream(out.toByteArray());
SpecificDatumReader<StringPair> reader = new SpecificDatumReader<StringPair>(StringPair.class);
Decoder decoder = DecoderFactory.get().binaryDecoder(input, null);
StringPair result = reader.read(null, decoder);
System.out.println(result.getLeft());
System.out.println(result.getRight());
input.close();
}
}
3.Avro数据文件
Avro的数据文件主要用于存储Avro对象序列。这与Hadoop的SequenceFile非常相似,他们之间的最大区别在于,Avro数据文件主要是面向跨语言使用而设计的,因此,我们可以用一种语言写入文件,并用另外一种语言来读取文件。(我们这里以Python为例)
3-1.Python写入 & Java读取
首先,我们需要安装Python,可以自行yum或者直接下载解压版,然后要为Python安装avro执行如下命令即可:
easy_install avro
接下来,我们来写一个python脚本,来创建avro数据文件。
import string
import sys
from avro import schema
from avro import io
from avro import datafile
if __name__ == '__main__':
if len(sys.argv) != 2:
sys.exit('Usage: %s <data_file>' % sys.argv[0])
avro_file = sys.argv[1]
#注意,avro是以二进制存储文件的
writer = open(avro_file, 'wb')
datum_writer = io.DatumWriter()
schema_object = schema.parse(' \
{ "type": "record", \
"name": "StringPair", \
"doc": "a pair of strings.", \
"fields": [ \
{"name": "left", "type": "string"}, \
{"name": "right", "type": "string"} \
] \
}')
dfw = datafile.DataFileWriter(writer, datum_writer, schema_object)
for line in sys.stdin.readlines():
(left, right) = string.split(line.strip(), ',')
dfw.append({'left':left, 'right':right});
dfw.close()
上面的脚本执行后,可以在控制台输出left和right的值,用逗号分隔,退出时按Ctrl+D键。
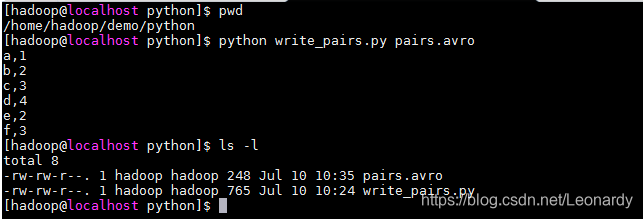
接下来我们在java端写一个demo,来读出上面用python脚本生成的avro数据文件。
package avro;
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.specific.SpecificDatumReader;
import schemas.StringPair;
public class AvroDemo3 {
public static void main(String[] args) throws IOException {
AvroDemo3 demo = new AvroDemo3();
demo.readAvroFile();
}
public void readAvroFile() throws IOException {
File file = new File("/home/hadoop/demo/python/pairs.avro");
SpecificDatumReader<StringPair> reader = new SpecificDatumReader<StringPair>(StringPair.class);
DataFileReader<StringPair> file_reader = new DataFileReader<StringPair>(file, reader);
StringPair result = null;
while(file_reader.hasNext()) {
result = file_reader.next(result);
System.out.println("left : " + result.getLeft() + ", right : " + result.getRight());
}
file_reader.close();
}
}
输出结果如下:

3-2.Java写入 & Python读取
这次呢,我们来写一个和上面过程相反的例子,这次我们通过java代码生成文件,再通过python来读取文件内容。
package avro;
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
import schemas.StringPair;
public class AvroDemo4 {
public static void main(String[] args) throws IOException {
AvroDemo4 demo = new AvroDemo4();
demo.writeAvroFile();
}
public void writeAvroFile() throws IOException {
File file = new File("/home/hadoop/demo/java/pairs_java.avro");
DatumWriter<StringPair> writer = new SpecificDatumWriter<StringPair>(StringPair.class);
DataFileWriter<StringPair> file_writer = new DataFileWriter<StringPair>(writer);
StringPair datum = new StringPair();;
file_writer.create(datum.getSchema(), file);
for(int i =1; i < 10; i++) {
datum.setLeft("left" + i);
datum.setRight("right" + i);
file_writer.append(datum);
}
file_writer.flush();
file_writer.close();
}
}
文件已经生成,接下来我们写一个python脚本来读取刚才用java程序生成的avro数据文件。
import sys
from avro import schema
from avro import io
from avro import datafile
from json import dumps
if __name__ == '__main__':
if len(sys.argv) != 2:
sys.exit('Usage: %s <data_file>' % sys.argv[0])
avro_file = sys.argv[1]
reader = open(avro_file, 'rb')
schema_object = schema.parse(' \
{ "type": "record", \
"name": "StringPair", \
"doc": "a pair of strings.", \
"fields": [ \
{"name": "left", "type": "string"}, \
{"name": "right", "type": "string"} \
] \
}')
datum_reader = io.DatumReader(schema_object)
dwr = datafile.DataFileReader(reader, datum_reader)
for line in dwr:
print dumps(line)
dwr.close()
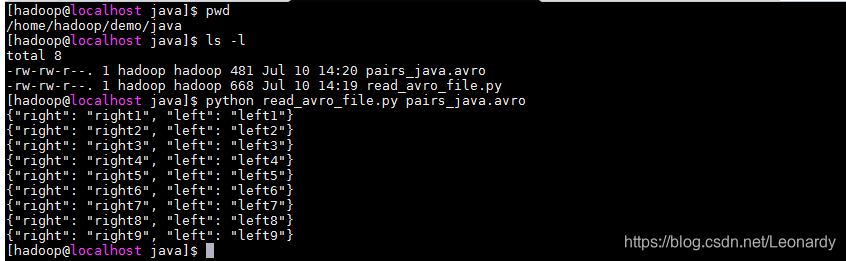
4.Schema解析
Avro的Schema解析非常灵活,读和写可以用不同的schema。
4-1.reader比write所使用的schema的字段多。
reader比writer所使用的schema字段数多
在刚才的StringPair.avsc的基础上,我们再创建一个新的schema文件,这次多添加 一个字段。
{
"namespace":"schemas",
"name":"StringPairAdd",
"type":"record",
"doc":"This is another String Pair.",
"fields":[
{"name":"left", "type":"string"},
{"name":"right", "type":"string"},
{"name":"middle", "type":"string", "default":"This is middle"}
]
}
在之前的AvroDemo类的基础上,我们稍作修改,来看一下效果。
package avro;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.Schema.Parser;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumReader;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.io.Decoder;
import org.apache.avro.io.DecoderFactory;
import org.apache.avro.io.Encoder;
import org.apache.avro.io.EncoderFactory;
public class AvroDemo5 {
private ByteArrayOutputStream out = new ByteArrayOutputStream();
private Parser parser = new Schema.Parser();
public static void main(String[] args) throws IOException {
AvroDemo5 demo = new AvroDemo5();
demo.writeAvroData();
demo.readAvroData();
}
public void writeAvroData() throws IOException {
Parser parser = new Schema.Parser();
Schema schema = parser.parse(getClass().getResourceAsStream("/StringPair.avsc"));
GenericRecord datum = new GenericData.Record(schema);
datum.put("left", "L");
datum.put("right", "R");
DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
writer.write(datum, encoder);
encoder.flush();
out.close();
}
public void readAvroData() throws IOException {
Schema schema_write = parser.parse(getClass().getResourceAsStream("/StringPair.avsc"));
Schema schema_read = parser.parse(getClass().getResourceAsStream("/StringPairAdded.avsc"));
ByteArrayInputStream input = new ByteArrayInputStream(out.toByteArray());
GenericDatumReader<GenericRecord> reader = new GenericDatumReader<GenericRecord>(schema_write, schema_read);
Decoder decoder = DecoderFactory.get().binaryDecoder(input, null);
GenericRecord result = reader.read(null, decoder);
System.out.println(result.get("left"));
System.out.println(result.get("right"));
System.out.println(result.get("middle"));
input.close();
}
}
得到输出结果如下:

※注:这里读取时用的schema比写入时新,所以读取时的schema(StringPairAdded.avsc)中新添加的字段一定要配置default属性,否则会报错。
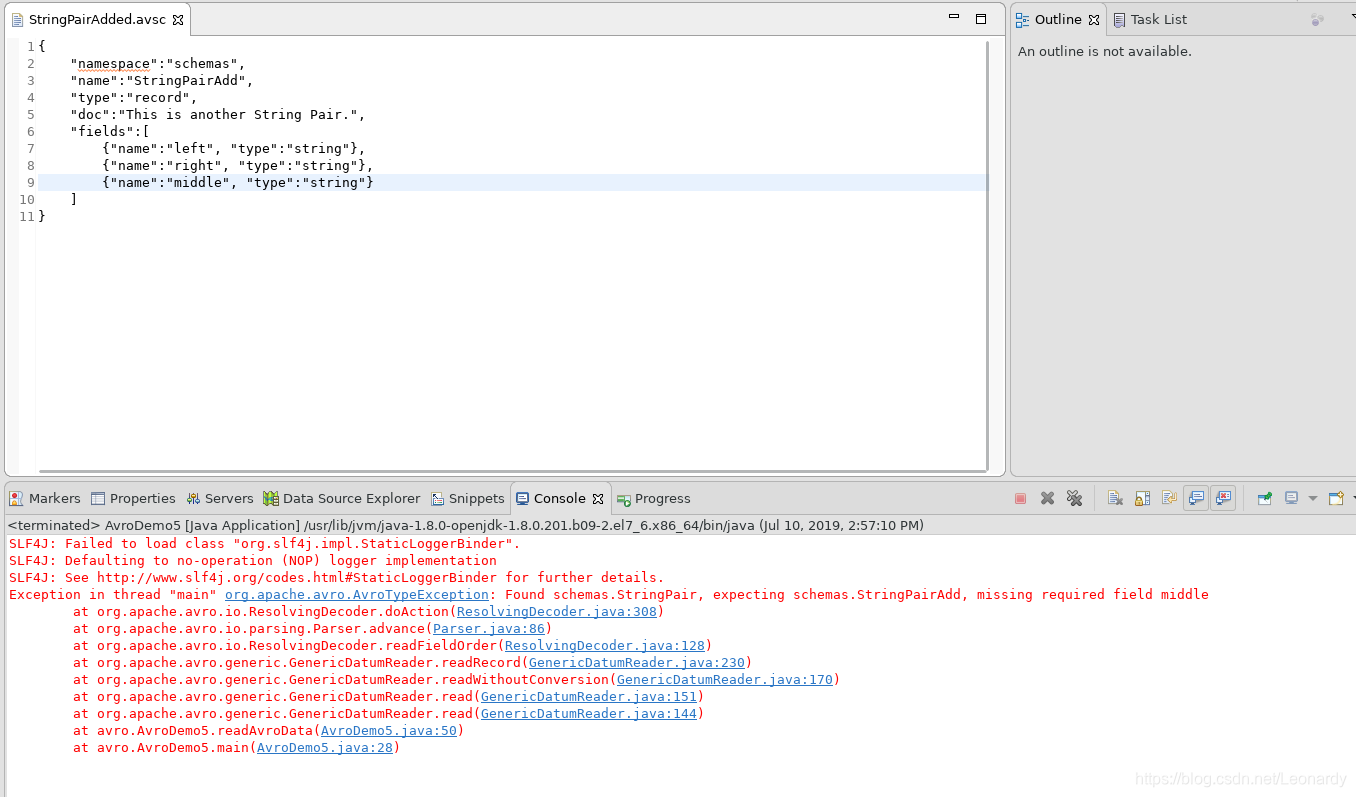
4-2.reader比writer所使用的schema字段数少。
这种情况常被称作投影
我们再创建一个schema,这次在StringPari.avsc的基础上我们去掉一个字段。
{
"namespace":"schemas",
"name":"ProjectedStringPair",
"type":"record",
"doc":"This is a Project String Pair.",
"fields":[
{"name":"right", "type":"string"}
]
}
接下来是Java代码。
package avro;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.Schema.Parser;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumReader;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.io.Decoder;
import org.apache.avro.io.DecoderFactory;
import org.apache.avro.io.Encoder;
import org.apache.avro.io.EncoderFactory;
public class AvroDemo6 {
private ByteArrayOutputStream out = new ByteArrayOutputStream();
private Parser parser = new Schema.Parser();
public static void main(String[] args) throws IOException {
AvroDemo6 demo = new AvroDemo6();
demo.writeAvroData();
demo.readAvroData();
}
public void writeAvroData() throws IOException {
Parser parser = new Schema.Parser();
Schema schema = parser.parse(getClass().getResourceAsStream("/StringPair.avsc"));
GenericRecord datum = new GenericData.Record(schema);
datum.put("left", "L");
datum.put("right", "R");
DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
writer.write(datum, encoder);
encoder.flush();
out.close();
}
public void readAvroData() throws IOException {
Schema schema_write = parser.parse(getClass().getResourceAsStream("/StringPair.avsc"));
Schema schema_read = parser.parse(getClass().getResourceAsStream("/ProjectedStringPair.avsc"));
ByteArrayInputStream input = new ByteArrayInputStream(out.toByteArray());
GenericDatumReader<GenericRecord> reader = new GenericDatumReader<GenericRecord>(schema_write, schema_read);
Decoder decoder = DecoderFactory.get().binaryDecoder(input, null);
GenericRecord result = reader.read(null, decoder);
System.out.println(result.get("left"));
System.out.println(result.get("right"));
System.out.println(result.getSchema());
input.close();
}
}
执行结果如下:
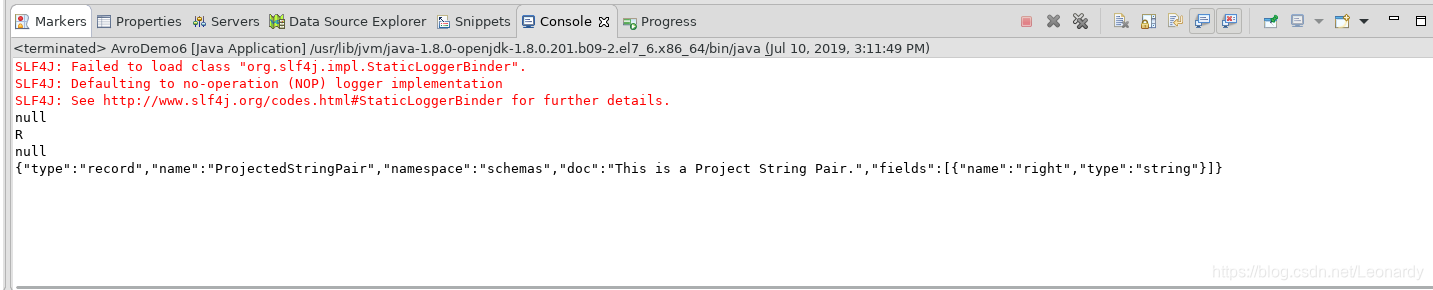
可以看到,left值为null,schema的信息中也没有left字段。
5.其他
除了上述的内容之外,Avro还支持别名,排序,MapReduce等等功能,这里值做简单介绍,不再一一例举。
5-1.别名
Avro可以允许读操作时,与写入操作时不同的字段名称来读取同一列的内容。
※注:为读操作指定别名后,就无法在读取时使用写操作时的列名称。(如下,读取时只能用first和second字段,而不再用left和right)
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings with aliased field names.",
"fields": [
{"name": "first", "type": "string", "aliases": ["left"]},
{"name": "second", "type": "string", "aliases": ["right"]}
]
}
5-2.排序
Avro的排序可通过在schema中为字段指定order属性来控制,它有三个值:
①ascending(默认值):升序
②descending:降序
③ignore:排序的时候忽略此字段
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings, sorted by right field descending.",
"fields": [
{"name": "left", "type": "string", "order": "ignore"},
{"name": "right", "type": "string", "order": "descending"}
]
}
