举例
在日常处理表格的时候,经常会遇到一些要求类似这样的:销售方面,按照A,B产品的销量额做标记;在考核方面,按照某些指标进行最后的评定等等
操作实例
这里就是以上面的表格数据为例,假设进行录取评定,要求选取语文分数大于80,数学和英语分数大于90分且专业课分数不低于120的人,操作过程代码和图形如下:
导入库和创建表格数据:
import pandas as pd
df = pd.DataFrame({
'姓名':['张三','李四','王二','麻子'],
'语文':[78,90,55,67],
'数学':[86,95,45,78],
'英语':[83,93,56,87],
'专业课':[150,180,89,103]
})
df
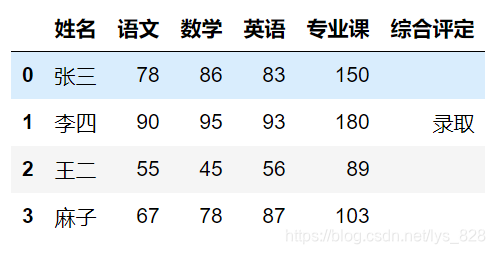
创建“综合评定”数据列,并进行数据筛选:
df['综合评定'] = ''
df['综合评定'][(df['语文']>80) & (df['数学']>90) & (df['英语']>90) & (df['专业课']>120)] = '录取'
df
拓展延伸
运行代码过后可以发现,这种纯有逻辑符号连接的判断,虽然很容易理解,但是不具有泛化能力,且看上去很冗肿。为了方便代码的保存和调用,可以对代买进行优化并封装成函数,示例如下:
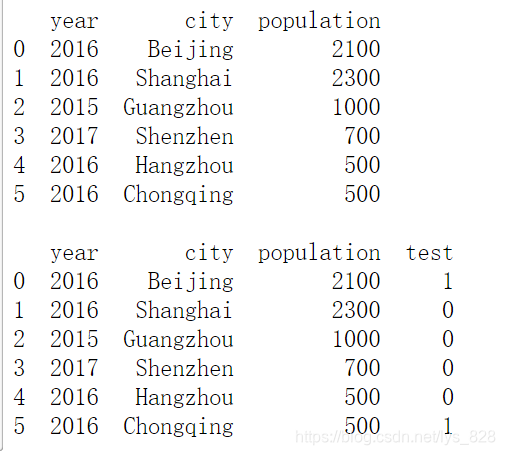
要求:选取2016年,北京和重庆的数据,并做标记,代码如下:
import numpy as np
import pandas as pd
data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'],
'year': [2016,2016,2015,2017,2016, 2016],
'population': [2100, 2300, 1000, 700, 500, 500]}
frame = pd.DataFrame(data, columns = ['year', 'city', 'population'])
def function(a, b):
if ('ing' in a) and (b == 2016):
return 1
else:
return 0
print(frame, '\n')
frame['test'] = frame.apply(lambda x: function(x.city, x.year), axis = 1)
print(frame)
运行结果如下图: