监督学习的任务就是学习一个模型,应用这一模型,对给定的输入预测相应的输出, 这个模型的一般形式为决策函数:
Y = f(X)
或者条件概率分布:
P(Y| X)
监督学习方法又可以分为生成方法(generative approach)和判别方法(discriminative approach) ,所学到的模型分别称为生成模型(generative model)和判别模型(discriminative model)。
生成方法由数据学习联合概率分布 P(X, Y), 然后求出条件概率分布 P( Y | X)作为预测的模型, 即生成模型:
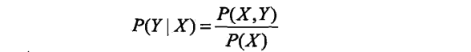
这样的方法之所以称为生成方法,是因为模型表示了给定输入 X 产生输出 Y 的生成关系(P(Y| X)已知), 典型的生成模型有: 朴素贝叶斯法 和隐马尔可夫模型。
判别方法由数据直接学习决策函数 f(X) 或者条件概率分布 P(Y | X ) 作为预测的模型, 即判别模型, 判别方法关系的是对给定的输入 X ,应该预测什么样的输出 Y,典型的判别模型包括: K紧邻法、 感知机、决策树、逻辑斯蒂回归模型、最大熵模型、支持向量机、提升方法和条件随机场等。
在监督学习中, 生成方法和判别方法各有优缺点, 适合于不同条件的学习问题。
生成方法的特点: 生成方法可以还原出联合概率分布 P(X, Y), 而判别方法则不能; 生成方法的学习收敛速度更快, 即当样本容量增加时, 学到的模型可以更快的收敛于真实模型; 当存在隐变量时,仍可以用生成方法学习,此时判别方法就不能用。
判别方法的特点:判别方法直接学习的是条件概率 P(Y | X) 或决策函数 f(X) ,直接面对预测,往往学习的准确率更高 ; 由于直接学习 P( Y| X)或 f(X), 可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
以上需要重点理解。
1.8 分类问题
略
1.9 标注问题
标注(tagging)也是一个监督学习问题, 可以认为标注问题是分类问题的一个推广,标注问题有是
更复杂的结构预测(structure prediction)问题的简单形式, 标注问题的输入是一个观测序列, 输出是一个标记序列或状态序列,标准问题的目标在于学习一个模型, 使它能够对观测序列给出标记序列作为预测。
注意: 可能给的标记个数是有限的, 但其组合所成的标记序列的个数是依序列长度呈指数级增长的。
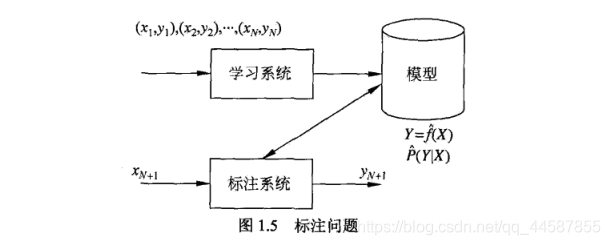
标注问题分为学习 和标注两个过程,首先给定一个训练数据集
T = {(x1, y1), (x2,y2),…(xN,yN)}
这里, xi = (xi(1) , xi(2), …, xi(n)) T, i = 1,2,…, N, 是输入观测序列, yi = (yi(1) , yi(2), …,yi(n)) T 是相应的输出标记序列, n 是序列的长度, 对不同样本可以有不同的值, 学习系统基于训练数据集构建一个模型, 表示为条件概率分布:
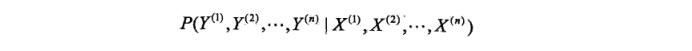
这里, 每一个 X(i) (i = 1, 2, …,n)取值为所有可能的观测, 每一个 Y(i) (i = 1,2…n)取值为所有可能的标记, 一般 n << N ,标注系统按照学习得到的条件概率分布模型, 对新的输入观测序列找到相应的输出标记序列,具体地,对一个观测序列
xN+1 = (xN+1(1), xN+2(2), … xN+i(n)) T ,找到使条件概率 P(yN+1(1), yN+2(2),… , yN+1(n))T | (xN+1(1), xN+2(2), … xN+i(n)) T 最大的标记序列 yN+1 = (yN+1(1), yN+2(2),… , yN+1(n))。
评价标注模型的指标与评价分类模型的指标一样, 常用的有标注准确率、精确率和召回率, 其定义与分类模型相同。
标注常用的统计学习方法有: 隐马尔可夫模型、 条件随机场。
标注问题在信息抽取、自然语言处理等领域被广泛应用,是这些领域的基本问题, 例如, 自然语言处理中的词性标注(part of speech tagging)就是一个典型的标注问题: 给定一个单词序列预测其对应的词性标记序列。
举一个信息抽取的例子, 从英文文章中抽取基本名词短语(base noun phrase)。为此,要对文章进行标注, 英文单词是一个观测, 英文句子是一个预测序列, 标记表示名词短语的“开始” 、“ 结束” 或“其他” (分别以 B 、E、O 表示),标记序列表示英文句子中基本名词短语所在位置, 信息抽取时, 将标记“开始” 到标记“结束” 的单词作为名词短语。
例如,给出以下的观测序列,即英文句子, 标注系统产生相应的标记及序列, 即给出句子中的基本名词短语。
输入 : At Microsoft Research , we have an insatiable curiosity and the desire to create new technology that will help define the computing experience.
输出: At /O Microsoft /B Research /E , we /O have /O an /O insatiable /B curiosity /E and /O the /O desire /BE to**/O** create /O new /B technology /E that /O will /O help /O define /O the /O computing /B experience /E .
1.10 回归问题
等价于函数拟合,回归问题按照输入变量的个数,分为一元回归和多元回归; 按照输入变量和输出变量之间关系的类型即模型的类型,分为线性回归和非线性回归。
回归学习最常用的损失函数是平方损失函数 ,在此情况下 , 回归问题可以由著名的最小二乘法(least squares)求解。
