最近看了一些semantic segmentation的paper,参考网上的教程(https://tuatini.me/practical-image-segmentation-with-unet/),用pytorch实现一个简化的unet练练手。
整个project的文件结构如下:
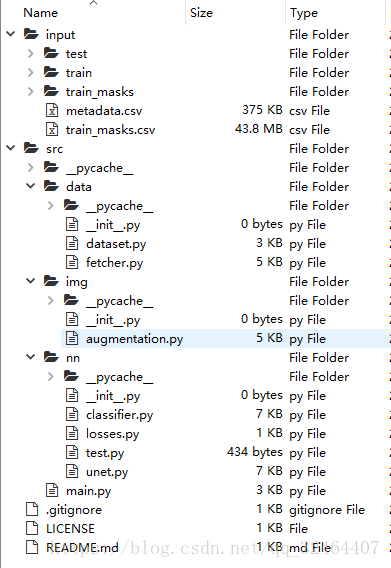
关于数据集:
用的是kaggle carvana-image-masking-challenge 竞赛提供的数据。fetcher.py文件提供了数据下载和读取的方法:
import os
import numpy as np
from PIL import Image
from sklearn.model_selection import train_test_split
from kaggle_data.downloader import KaggleDataDownloader
class DatasetFetcher:
def __init__(self):
"""
A tool used to automatically download, check, split and get
relevant information on the dataset
"""
self.train_data = None
self.test_data = None
self.train_masks_data = None
self.train_files = None
self.test_files = None
self.train_masks_files = None
def download_dataset(self, hq_files=True):
"""
Downloads the dataset and return the input paths
Args:
hq_files (bool): Whether to download the hq files or not
Returns:
list: [train_data, test_data, metadata_csv, train_masks_csv, train_masks_data]
"""
competition_name = "carvana-image-masking-challenge"
script_dir = os.path.dirname(os.path.abspath(__file__))
destination_path = os.path.join(script_dir, '../../input/')
prefix = ""
if hq_files:
prefix = "_hq"
files = ["train" + prefix + ".zip", "test" + prefix + ".zip", "metadata.csv.zip",
"train_masks.csv.zip", "train_masks.zip"]
datasets_path = [destination_path + "train" + prefix, destination_path + "test" + prefix,
destination_path + "metadata.csv", destination_path + "train_masks.csv",
destination_path + "train_masks"]
is_datasets_present = True
# If the folders already exists then the files may already be extracted
# This is a bit hacky but it's sufficient for our needs
for dir_path in datasets_path:
if not os.path.exists(dir_path):
is_datasets_present = False
if not is_datasets_present:
# Put your Kaggle user name and password in a $KAGGLE_USER and $KAGGLE_PASSWD env vars respectively
downloader = KaggleDataDownloader(os.getenv("KAGGLE_USER"), os.getenv("KAGGLE_PASSWD"), competition_name)
for file in files:
output_path = downloader.download_dataset(file, destination_path)
downloader.decompress(output_path, destination_path)
os.remove(output_path)
else:
print("All datasets are present.")
self.train_data = datasets_path[0]
self.test_data = datasets_path[1]
self.train_masks_data = datasets_path[4]
self.train_files = sorted(os.listdir(self.train_data))
self.test_files = sorted(os.listdir(self.test_data))
self.train_masks_files = sorted(os.listdir(self.train_masks_data))
return datasets_path
def get_car_image_files(self, car_image_id, test_file=False, get_mask=False):
if get_mask:
if car_image_id + "_mask.gif" in self.train_masks_files:
return self.train_masks_data + "/" + car_image_id + "_mask.gif"
elif car_image_id + ".png" in self.train_masks_files:
return self.train_masks_data + "/" + car_image_id + ".png"
else:
raise Exception("No mask with this ID found")
elif test_file:
if car_image_id + ".jpg" in self.test_files:
return self.test_data + "/" + car_image_id + ".jpg"
else:
if car_image_id + ".jpg" in self.train_files:
return self.train_data + "/" + car_image_id + ".jpg"
raise Exception("No image with this ID found")
def get_image_matrix(self, image_path):
img = Image.open(image_path)
return np.asarray(img, dtype=np.uint8)
def get_image_size(self, image):
img = Image.open(image)
return img.size
def get_train_files(self, validation_size=0.2, sample_size=None):
"""
Args:
validation_size (float):
Value between 0 and 1
sample_size (float, None):
Value between 0 and 1 or None.
Whether you want to have a sample of your dataset.
Returns:
list :
Returns the dataset in the form:
[train_data, train_masks_data, valid_data, valid_masks_data]
"""
train_ids = list(map(lambda img: img.split(".")[0], self.train_files))
# Each id has 16 images but well...
if sample_size:
rnd = np.random.choice(train_ids, int(len(train_ids) * sample_size))
train_ids = rnd.ravel()
if validation_size:
ids_train_split, ids_valid_split = train_test_split(train_ids, test_size=validation_size)
else:
ids_train_split = train_ids
ids_valid_split = []
train_ret = []
train_masks_ret = []
valid_ret = []
valid_masks_ret = []
for id in ids_train_split:
train_ret.append(self.get_car_image_files(id))
train_masks_ret.append(self.get_car_image_files(id, get_mask=True))
for id in ids_valid_split:
valid_ret.append(self.get_car_image_files(id))
valid_masks_ret.append(self.get_car_image_files(id, get_mask=True))
return [np.array(train_ret).ravel(), np.array(train_masks_ret).ravel(),
np.array(valid_ret).ravel(), np.array(valid_masks_ret).ravel()]
def get_test_files(self, sample_size):
test_files = self.test_files
if sample_size:
rnd = np.random.choice(self.test_files, int(len(self.test_files) * sample_size))
test_files = rnd.ravel()
ret = [None] * len(test_files)
for i, file in enumerate(test_files):
ret[i] = self.test_data + "/" + file
return np.array(ret)
针对这个数据集,需要自己定制对应的pytorch dataset类,实现在dataset.py中:
import torch
import numpy as np
import torch.utils.data as data
from PIL import Image
from torchvision import transforms
def mask_to_tensor(mask, threshold):
"""
Transforms a mask to a tensor
Args:
mask (np.ndarray): A greyscale mask array
threshold: The threshold used to consider the mask present or not
Returns:
tensor: A Pytorch tensor
"""
mask = mask
mask = (mask > threshold).astype(np.float32)
tensor = torch.from_numpy(mask).type(torch.FloatTensor)
return tensor
# Reference: https://github.com/pytorch/vision/blob/master/torchvision/datasets/folder.py#L66
class TrainImageDataset(data.Dataset):
def __init__(self, X_data, y_data=None, img_resize=128,
X_transform=None, y_transform=None, threshold=0.5):
"""
A dataset loader taking images paths as argument and return
as them as tensors from getitem()
Args:
threshold (float): The threshold used to consider the mask present or not
X_data (list): List of paths to the training images
y_data (list, optional): List of paths to the target images
img_resize (tuple): Tuple containing the new size of the images
X_transform (callable, optional): A function/transform that takes in 2 numpy arrays.
Assumes X_data and y_data are not None.
(train_img, mask_img) and returns a transformed version with the same signature
y_transform (callable, optional): A function/transform that takes in 2 numpy arrays.
Assumes X_data and y_data are not None.
(train_img, mask_img) and returns a transformed version with the same signature
"""
self.threshold = threshold
self.X_train = X_data
self.y_train_masks = y_data
self.img_resize = img_resize
self.y_transform = y_transform
self.X_transform = X_transform
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is class_index of the target class.
"""
img = Image.open(self.X_train[index]).convert("RGB")
img = transforms.Resize(self.img_resize)(img)
img = np.asarray(img, dtype=np.float32)
# Pillow reads gifs
mask = Image.open(self.y_train_masks[index]).convert("L")
mask = transforms.Resize(self.img_resize)(mask)
mask = np.asarray(mask, dtype=np.float32) # GreyScale
if self.X_transform:
img, mask = self.X_transform(img, mask)
if self.y_transform:
img, mask = self.y_transform(img, mask)
img = transforms.ToTensor()(img)
mask = mask_to_tensor(mask, self.threshold)
return img, mask
def __len__(self):
assert len(self.X_train) == len(self.y_train_masks)
return len(self.X_train)
class TestImageDataset(data.Dataset):
def __init__(self, X_data, img_resize=128):
"""
A dataset loader taking images paths as argument and return
as them as tensors from getitem()
Args:
X_data (list): List of paths to the training images
img_resize (tuple): Tuple containing the new size of the images
"""
self.img_resize = img_resize
self.X_train = X_data
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is class_index of the target class.
"""
img_path = self.X_train[index]
img = Image.open(img_path)
img = transforms.Resize(self.img_resize)(img)
img = np.asarray(img.convert("RGB"), dtype=np.float32)
img = transforms.ToTensor()(img)
return img, img_path.split("/")[-1]
def __len__(self):
return len(self.X_train)
关于图像数据增强,实现在augmentation.py:
import cv2
import numpy as np
def random_hue_saturation_value(image, hue_shift_limit=(-180, 180),
sat_shift_limit=(-255, 255),
val_shift_limit=(-255, 255), u=0.5):
if np.random.random() < u:
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(image)
hue_shift = np.random.uniform(hue_shift_limit[0], hue_shift_limit[1])
h = cv2.add(h, hue_shift)
sat_shift = np.random.uniform(sat_shift_limit[0], sat_shift_limit[1])
s = cv2.add(s, sat_shift)
val_shift = np.random.uniform(val_shift_limit[0], val_shift_limit[1])
v = cv2.add(v, val_shift)
image = cv2.merge((h, s, v))
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
return image
def random_shift_scale_rotate(image, mask,
shift_limit=(-0.0625, 0.0625),
scale_limit=(-0.1, 0.1),
rotate_limit=(-45, 45), aspect_limit=(0, 0),
borderMode=cv2.BORDER_CONSTANT, u=0.5):
if np.random.random() < u:
height, width, channel = image.shape
angle = np.random.uniform(rotate_limit[0], rotate_limit[1]) # degree
scale = np.random.uniform(1 + scale_limit[0], 1 + scale_limit[1])
aspect = np.random.uniform(1 + aspect_limit[0], 1 + aspect_limit[1])
sx = scale * aspect / (aspect ** 0.5)
sy = scale / (aspect ** 0.5)
dx = round(np.random.uniform(shift_limit[0], shift_limit[1]) * width)
dy = round(np.random.uniform(shift_limit[0], shift_limit[1]) * height)
cc = np.math.cos(angle / 180 * np.math.pi) * sx
ss = np.math.sin(angle / 180 * np.math.pi) * sy
rotate_matrix = np.array([[cc, -ss], [ss, cc]])
box0 = np.array([[0, 0], [width, 0], [width, height], [0, height], ])
box1 = box0 - np.array([width / 2, height / 2])
box1 = np.dot(box1, rotate_matrix.T) + np.array([width / 2 + dx, height / 2 + dy])
box0 = box0.astype(np.float32)
box1 = box1.astype(np.float32)
mat = cv2.getPerspectiveTransform(box0, box1)
image = cv2.warpPerspective(image, mat, (width, height), flags=cv2.INTER_LINEAR, borderMode=borderMode,
borderValue=(
0, 0,
0,))
mask = cv2.warpPerspective(mask, mat, (width, height), flags=cv2.INTER_LINEAR, borderMode=borderMode,
borderValue=(
0, 0,
0,))
return image, mask
def random_horizontal_flip(image, mask, u=0.5):
if np.random.random() < u:
image = cv2.flip(image, 1)
mask = cv2.flip(mask, 1)
return image, mask
def random_saturation(img, limit=(-0.3, 0.3), u=0.5):
if np.random.random() < u:
alpha = 1.0 + np.random.uniform(limit[0], limit[1])
coef = np.array([[[0.114, 0.587, 0.299]]])
gray = img * coef
gray = np.sum(gray, axis=2, keepdims=True)
img = alpha * img + (1. - alpha) * gray
img = np.clip(img, 0., 1.)
return img
def random_brightness(img, limit=(-0.3, 0.3), u=0.5):
if np.random.random() < u:
alpha = 1.0 + np.random.uniform(limit[0], limit[1])
img = alpha * img
img = np.clip(img, 0., 1.)
return img
def random_gray(img, u=0.5):
if np.random.random() < u:
coef = np.array([[[0.114, 0.587, 0.299]]]) # rgb to gray (YCbCr)
gray = np.sum(img * coef, axis=2)
img = np.dstack((gray, gray, gray))
return img
def random_contrast(img, limit=(-0.3, 0.3), u=0.5):
if np.random.random() < u:
alpha = 1.0 + np.random.uniform(limit[0], limit[1])
coef = np.array([[[0.114, 0.587, 0.299]]]) # rgb to gray (YCbCr)
gray = img * coef
gray = (3.0 * (1.0 - alpha) / gray.size) * np.sum(gray)
img = alpha * img + gray
img = np.clip(img, 0., 1.)
return img
def random_channel_shift(x, limit, channel_axis=2):
x = np.rollaxis(x, channel_axis, 0)
min_x, max_x = np.min(x), np.max(x)
channel_images = [np.clip(x_ch + np.random.uniform(-limit, limit), min_x, max_x) for x_ch in x]
x = np.stack(channel_images, axis=0)
x = np.rollaxis(x, 0, channel_axis + 1)
return x
def augment_img(img, mask):
img = random_hue_saturation_value(img,
hue_shift_limit=(-50, 50),
sat_shift_limit=(-5, 5),
val_shift_limit=(-15, 15))
img, mask = random_shift_scale_rotate(img, mask,
shift_limit=(-0.0625, 0.0625),
scale_limit=(-0.1, 0.1),
rotate_limit=(-0, 0))
img, mask = random_horizontal_flip(img, mask)
# img = random_channel_shift(img, limit=0.05)
# img = random_brightness(img, limit=(-0.5, 0.5), u=0.5)
# img = random_contrast(img, limit=(-0.5, 0.5), u=0.5)
# img = random_saturation(img, limit=(-0.5, 0.5), u=0.5)
# img = random_gray(img, u=0.2)
return img, mask
unet的网络结构实现在unet.py(注意这里用的是简单的双线性插值实现上采样):
import torch
import torch.nn as nn
import torch.nn.functional as F
BN_EPS = 1e-4
class ConvBnRelu2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, padding=1, dilation=1, stride=1, groups=1, is_bn=True,
is_relu=True):
super(ConvBnRelu2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding, stride=stride,
dilation=dilation, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(out_channels, eps=BN_EPS)
self.relu = nn.ReLU(inplace=True)
if is_bn is False: self.bn = None
if is_relu is False: self.relu = None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
## original 3x3 stack filters used in UNet
class StackEncoder(nn.Module):
def __init__(self, x_channels, y_channels, kernel_size=3):
super(StackEncoder, self).__init__()
padding = (kernel_size - 1) // 2
self.encode = nn.Sequential(
ConvBnRelu2d(x_channels, y_channels, kernel_size=kernel_size, padding=padding, dilation=1, stride=1,
groups=1),
ConvBnRelu2d(y_channels, y_channels, kernel_size=kernel_size, padding=padding, dilation=1, stride=1,
groups=1),
)
def forward(self, x):
# print('x',x.size())
y = self.encode(x) # y,x尺寸一致
# print('y',y.size())
y_small = F.max_pool2d(y, kernel_size=2, stride=2)
return y, y_small
class StackDecoder(nn.Module):
def __init__(self, x_big_channels, x_channels, y_channels, kernel_size=3):
super(StackDecoder, self).__init__()
padding = (kernel_size - 1) // 2
self.decode = nn.Sequential(
ConvBnRelu2d(x_big_channels + x_channels, y_channels, kernel_size=kernel_size, padding=padding,
dilation=1, stride=1, groups=1),
ConvBnRelu2d(y_channels, y_channels, kernel_size=kernel_size, padding=padding, dilation=1, stride=1,
groups=1),
ConvBnRelu2d(y_channels, y_channels, kernel_size=kernel_size, padding=padding, dilation=1, stride=1,
groups=1),
)
def forward(self, x_big, x): #decoder负责上采样和多尺度特征融合,输出分辨率和x_big一致
N, C, H, W = x_big.size()
y = F.upsample(x, size=(H, W), mode='bilinear') #直接把低分辨率的feature map双线性插值upsample到高分辨率
y = torch.cat([y, x_big], 1)
y = self.decode(y)
return y
## 1024x1024
#class UNet1024(nn.Module):
# def __init__(self, in_shape):
# super(UNet1024, self).__init__()
# C, H, W = in_shape
# # assert(C==3)
#
# # 1024
# self.down1 = StackEncoder(C, 24, kernel_size=3) # 512
# self.down2 = StackEncoder(24, 64, kernel_size=3) # 256
# self.down3 = StackEncoder(64, 128, kernel_size=3) # 128
# self.down4 = StackEncoder(128, 256, kernel_size=3) # 64
# self.down5 = StackEncoder(256, 512, kernel_size=3) # 32
# self.down6 = StackEncoder(512, 768, kernel_size=3) # 16
#
# self.center = nn.Sequential(
# ConvBnRelu2d(768, 768, kernel_size=3, padding=1, stride=1),
# )
#
# # 8
# # x_big_channels, x_channels, y_channels
# self.up6 = StackDecoder(768, 768, 512, kernel_size=3) # 16
# self.up5 = StackDecoder(512, 512, 256, kernel_size=3) # 32
# self.up4 = StackDecoder(256, 256, 128, kernel_size=3) # 64
# self.up3 = StackDecoder(128, 128, 64, kernel_size=3) # 128
# self.up2 = StackDecoder(64, 64, 24, kernel_size=3) # 256
# self.up1 = StackDecoder(24, 24, 24, kernel_size=3) # 512
# self.classify = nn.Conv2d(24, 1, kernel_size=1, padding=0, stride=1, bias=True)
#
# def _crop_concat(self, upsampled, bypass):
# """
# Crop y to the (h, w) of x and concat them.
# Used for the expansive path.
# Returns:
# The concatenated tensor
# """
# c = (bypass.size()[2] - upsampled.size()[2]) // 2
# bypass = F.pad(bypass, (-c, -c, -c, -c))
#
# return torch.cat((upsampled, bypass), 1)
#
# def forward(self, x):
# out = x # ;print('x ',x.size())
# #
# down1, out = self.down1(out) ##;print('down1',down1.size()) #256
# down2, out = self.down2(out) # ;print('down2',down2.size()) #128
# down3, out = self.down3(out) # ;print('down3',down3.size()) #64
# down4, out = self.down4(out) # ;print('down4',down4.size()) #32
# down5, out = self.down5(out) # ;print('down5',down5.size()) #16
# down6, out = self.down6(out) # ;print('down6',down6.size()) #8
# pass # ;print('out ',out.size())
#
# out = self.center(out)
# out = self.up6(down6, out)
# out = self.up5(down5, out)
# out = self.up4(down4, out)
# out = self.up3(down3, out)
# out = self.up2(down2, out)
# out = self.up1(down1, out)
# # 1024
#
# out = self.classify(out)
# out = torch.squeeze(out, dim=1)
# return out
# 128x128
class UNet128(nn.Module):
def __init__(self, in_channel):
super(UNet128, self).__init__()
# 128
self.down3 = StackEncoder(in_channel, 128, kernel_size=3) # 64
self.down4 = StackEncoder(128, 256, kernel_size=3) # 32
self.down5 = StackEncoder(256, 512, kernel_size=3) # 16
self.down6 = StackEncoder(512, 1024, kernel_size=3) # 8
self.center = nn.Sequential(
ConvBnRelu2d(1024, 1024, kernel_size=3, padding=1, stride=1),
)
# 8
# x_big_channels, x_channels, y_channels
self.up6 = StackDecoder(1024, 1024, 512, kernel_size=3) # 16
self.up5 = StackDecoder(512, 512, 256, kernel_size=3) # 32
self.up4 = StackDecoder(256, 256, 128, kernel_size=3) # 64
self.up3 = StackDecoder(128, 128, 64, kernel_size=3) # 128
self.classify = nn.Conv2d(64, 1, kernel_size=1, padding=0, stride=1, bias=True)# 1*1 kernel, 0 padding, 1 stride 输出size当然和输入保持一致
def forward(self, x):
out = x #
# print('x ',x.size())
down3, out = self.down3(out) #
# print('down3',down3.size())
down4, out = self.down4(out) #
# print('down4',down4.size())
down5, out = self.down5(out) #
# print('down5',down5.size())
down6, out = self.down6(out) #
# print('down6',down6.size())
# print('out ',out.size())
out = self.center(out)
# print('center',out.size())
out = self.up6(down6, out)
# print('up6',out.size()) #特征融合:down6和out
out = self.up5(down5, out)
# print('up5',out.size())
out = self.up4(down4, out)
# print('up4',out.size())
out = self.up3(down3, out) #down3尺寸和x一样,保证输出尺寸和原图相同
# print('up3',out.size())
out = self.classify(out)
# print('classify',out.size())
out = torch.squeeze(out, dim=1)
return out
交叉熵loss和dice loss实现在losses.py:
import torch.nn as nn
import torch.nn.functional as F
class BCELoss2d(nn.Module):
def __init__(self, weight=None, size_average=True):
super(BCELoss2d, self).__init__()
self.bce_loss = nn.BCELoss(weight, size_average)
def forward(self, logits, targets):
probs = F.sigmoid(logits) #二分类,sigmoid等价于softmax
probs_flat = probs.view(-1)
targets_flat = targets.view(-1)
return self.bce_loss(probs_flat, targets_flat)
class SoftDiceLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(SoftDiceLoss, self).__init__()
def forward(self, logits, targets):
num = targets.size(0)
probs = F.sigmoid(logits)
m1 = probs.view(num, -1)
m2 = targets.view(num, -1)
intersection = (m1 * m2)
score = 2. * (intersection.sum(1) + 1) / (m1.sum(1) + m2.sum(1) + 1)
score = 1 - score.sum() / num
return score
# https://github.com/pytorch/pytorch/issues/1249
def dice_coeff(pred, target):
smooth = 1.
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + smooth) / (m1.sum() + m2.sum() + smooth)
网络的各项训练方法实现在classifier.py:
import torch
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import ReduceLROnPlateau
from tqdm import tqdm
from collections import OrderedDict
import nn.losses as losses_utils
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
class CarvanaClassifier:
def __init__(self, net, max_epochs):
"""
The classifier for carvana used for training and launching predictions
Args:
net (nn.Module): The neural net module containing the definition of your model
max_epochs (int): The maximum number of epochs on which the model will train
"""
self.net = net
self.max_epochs = max_epochs
self.epoch_counter = 0
self.use_cuda = torch.cuda.is_available()
def restore_model(self, model_path):
"""
Restore a model parameters from the one given in argument
Args:
model_path (str): The path to the model to restore
"""
self.net.load_state_dict(torch.load(model_path))
def _criterion(self, logits, labels):
l = losses_utils.BCELoss2d().forward(logits, labels) + losses_utils.SoftDiceLoss().forward(logits, labels)
return l
def _validate_epoch(self, valid_loader, threshold):
losses = AverageMeter()
dice_coeffs = AverageMeter()
it_count = len(valid_loader)
batch_size = valid_loader.batch_size
images = None # To save the last images batch
targets = None # To save the last target batch
preds = None # To save the last prediction batch
with tqdm(total=it_count, desc="Validating", leave=False) as pbar:
for ind, (images, targets) in enumerate(valid_loader):
if self.use_cuda:
images = images.cuda()
targets = targets.cuda()
# Volatile because we are in pure inference mode
# http://pytorch.org/docs/master/notes/autograd.html#volatile
images = Variable(images, volatile=True)
targets = Variable(targets, volatile=True)
# forward
logits = self.net(images)
probs = F.sigmoid(logits)
preds = (probs > threshold).float()
loss = self._criterion(logits, targets)
acc = losses_utils.dice_coeff(preds, targets)
losses.update(loss.data[0], batch_size)
dice_coeffs.update(acc.data[0], batch_size)
pbar.update(1)
return losses.avg, dice_coeffs.avg, images, targets, preds
def _train_epoch(self, train_loader, optimizer, threshold):
losses = AverageMeter() # AverageMeter是一个对象,用于存储一个变量的当前值和平均值
dice_coeffs = AverageMeter()
# Total training files count / batch_size
batch_size = train_loader.batch_size
it_count = len(train_loader)
with tqdm(total=it_count,
desc="Epochs {}/{}".format(self.epoch_counter + 1, self.max_epochs),
# bar_format='{l_bar}{bar}| {n_fmt}/{total_fmt} [{remaining}{postfix}]'
) as pbar:
for ind, (inputs, target) in enumerate(train_loader):
if self.use_cuda:
inputs = inputs.cuda()
target = target.cuda()
inputs, target = Variable(inputs), Variable(target)
# forward
logits = self.net.forward(inputs)
probs = F.sigmoid(logits)
pred = (probs > threshold).float()
# backward + optimize
loss = self._criterion(logits, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print statistics
acc = losses_utils.dice_coeff(pred, target)
losses.update(loss.data[0], batch_size)
dice_coeffs.update(acc.data[0], batch_size)
# Update pbar
pbar.set_postfix(OrderedDict(loss='{0:1.5f}'.format(loss.data[0]),
dice_coeff='{0:1.5f}'.format(acc.data[0])))
pbar.update(1)
return losses.avg, dice_coeffs.avg
def _run_epoch(self, train_loader: DataLoader, valid_loader: DataLoader,
optimizer, lr_scheduler, threshold=0.5, callbacks=None):
# switch to train mode
self.net.train()
# Run a train pass on the current epoch
train_loss, train_acc = self._train_epoch(train_loader, optimizer, threshold)
# switch to evaluate mode
self.net.eval()
# Run the validation pass
val_loss, val_acc, last_images, last_targets, last_preds = self._validate_epoch(valid_loader, threshold)
# Reduce learning rate if needed
lr_scheduler.step(val_loss, self.epoch_counter)
print("train_loss = {:03f}, train_acc = {:03f}\n"
"val_loss = {:03f}, val_acc = {:03f}"
.format(train_loss, train_acc, val_loss, val_acc))
self.epoch_counter += 1
def train(self, train_loader: DataLoader, valid_loader: DataLoader,
epochs, threshold=0.5, callbacks=None):
"""
Trains the neural net
Args:
train_loader (DataLoader): The Dataloader for training
valid_loader (DataLoader): The Dataloader for validation
epochs (int): number of epochs
threshold (float): The threshold used to consider the mask present or not
callbacks (list): List of callbacks functions to call at each epoch
Returns:
str, None: The path where the model was saved, or None if it wasn't saved
"""
if self.use_cuda:
self.net.cuda()
optimizer = optim.Adam(self.net.parameters())
lr_scheduler = ReduceLROnPlateau(optimizer, 'min', patience=2, verbose=True, min_lr=1e-7)
for epoch in range(epochs):
self._run_epoch(train_loader, valid_loader, optimizer, lr_scheduler, threshold, callbacks)
def predict(self, test_loader, callbacks=None):
"""
Launch the prediction on the given loader and pass
each predictions to the given callbacks.
Args:
test_loader (DataLoader): The loader containing the test dataset
callbacks (list): List of callbacks functions to call at prediction pass
"""
# Switch to evaluation mode
self.net.eval()
it_count = len(test_loader)
with tqdm(total=it_count, desc="Classifying") as pbar:
for ind, (images, files_name) in enumerate(test_loader):
if self.use_cuda:
images = images.cuda()
images = Variable(images, volatile=True)
# forward
logits = self.net(images)
probs = F.sigmoid(logits)
probs = probs.data.cpu().numpy()
pbar.update(1)
最后主函数main.py:
import nn.classifier
import nn.unet as unet
import torch
from torch.utils.data import DataLoader
from torch.utils.data.sampler import RandomSampler, SequentialSampler
import img.augmentation as aug
from data.fetcher import DatasetFetcher
import os
from multiprocessing import cpu_count
from data.dataset import TrainImageDataset, TestImageDataset
import img.transformer as transformer
from torch.autograd import Variable
if __name__ == "__main__":
#输入kaggle账户密码,下载数据时用
os.environ['KAGGLE_USER'] = 'XXX'
os.environ['KAGGLE_PASSWD'] = 'XXX'
# Hyperparameters
img_resize = 128
in_channel = 3
batch_size = 3
epochs = 3
threshold = 0.5
validation_size = 0.2
sample_size = None # Put None to work on full dataset
# Training on 4576 samples and validating on 512 samples
# -- Optional parameters
threads = cpu_count()
# threads = 0
use_cuda = torch.cuda.is_available()
# print(os.path.abspath(__file__))
script_dir = os.path.dirname(os.path.abspath(__file__)) # os.path.abspath(__file__) 返回的是当前py文件的路径,不能找ipython命令行中运行
# Download the datasets
ds_fetcher = DatasetFetcher()
ds_fetcher.download_dataset(hq_files = False)#hq_files 是否下载高清图片数据集
# Get the path to the files for the neural net
# We don't want to split train/valid for KFold crossval
X_train, y_train, X_valid, y_valid = ds_fetcher.get_train_files(sample_size=sample_size, validation_size=validation_size)
full_x_test = ds_fetcher.get_test_files(sample_size)
# Define our neural net architecture
net = unet.UNet128(in_channel)
classifier = nn.classifier.CarvanaClassifier(net, epochs)
train_ds = TrainImageDataset(X_train, y_train, img_resize, X_transform=aug.augment_img, threshold=threshold) #semantic segmentation没有label, img(X)和mask(y)共用X_transform
train_loader = DataLoader(train_ds, batch_size,
sampler=RandomSampler(train_ds),
num_workers=threads,
pin_memory=use_cuda)
valid_ds = TrainImageDataset(X_valid, y_valid, img_resize, threshold=threshold)
valid_loader = DataLoader(valid_ds, batch_size,
sampler=SequentialSampler(valid_ds),
num_workers=threads,
pin_memory=use_cuda)
print("Training on {} samples and validating on {} samples "
.format(len(train_loader.dataset), len(valid_loader.dataset)))
classifier.train(train_loader, valid_loader, epochs)
#
# test_ds = TestImageDataset(full_x_test, img_resize)
# test_loader = DataLoader(test_ds, batch_size,
# sampler=SequentialSampler(test_ds),
# num_workers=threads,
# pin_memory=use_cuda)
#
# # Predict & save
# classifier.predict(test_loader)
