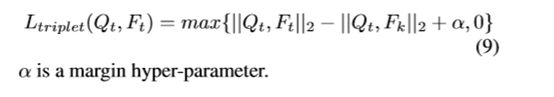目录
论文题目:Text2Scene: Generating Compositional Scenes from Textual Descriptions
(根据文本描述生成合成场景)
论文原文:https://arxiv.org/abs/1809.01110
论文出处:CVPR2019
论文原作者:Fuwen Tan1 Song Feng2 Vicente Ordonez1 1University of Virginia, 2IBM Thomas J. Watson Research Center.
报告人:苏叶
写在前面:
这篇文章没有使用当下比较流行的GANS,而是通过关注输入文本的不同部分和生成场景的当前状态,学会在每一个时间步上依次生成对象及其属性(位置、大小、外观等)。作者证明在较小的修改下,所提出的框架模型可以处理生成不同形式的场景。包括卡通场景,与真实场景对应的对象布局和合成图像。和最先进的使用自动度量的GANS和基于人类判断的高级方法相比,具有可解释结果的优势。
本文调整和训练模型可以生成三种类型的场景:(1)抽象场景(2)图像场景相对应的对象布局(COCO 数据集)(3)针对对应的图像合成场景(coco数据集中)。
用了一个可解释性模型,通过每一个时间步预测和添加新对象来迭代生成场景。在自动评价指标和人工评价时候均表现了最好的性能。

为生成文本描述图像是一个非常有挑战的工作,例如,1.输入文本描述间接暗示属性的存在,比如输入MIKE IS SURPRISED, 应该是mike非常吃惊,需要在面部表情有所体现。2.文本描述往往包含了包括相对空间复杂的信息。例如,输入jenny 向着mike和鸭子跑去,这里面jenny的方向依赖了后面两个对象的空间位置,在最后一个例子,大象走在一条直线上,也暗示了相对空间信息。
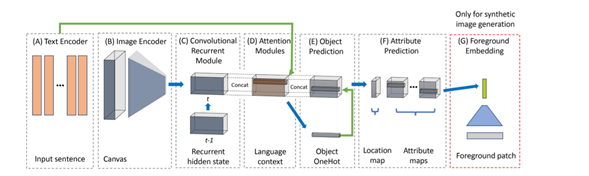
我们的模型,首先使用sequence to sequence方法将对象放在了一个空白的画布上,Text2Screen有一个文本编码器A,可以映射句子的潜在表示,为输入提供一系列的表征;接着是一个图像编码器B,为目前状态的生成场景编码,生成当前的画布;接着是一个卷积循环模块C,用于追踪空间位置,目前已经生成的历史,可以将当前的状态传给下一个步骤。D是注意力模块,集中于输入文本的不同部分,连续不断地集中于输入文本的不同部分;E是一个对象解码器,可以根据当前场景状态于已参与的输入文本预测下一个对象,可以决定放什么对象。F是一个属性解码器,可以为我们的预测对象分配属性。还有一个可选的前向嵌入G,用来学习合成图像生成任务中批量检索外表特征。
1.本文的主要贡献:
- 提出了Text2Screen模型,一个从自然语言描述中合成场景的框架
- 展示了Text2Screen模型在不同场景中的表现,包括卡通场景,与真实图像对应的语义布局和合成图像组合三个方面
- 对抽象场景数据集的抽象图像生成,COCO数据集的语义布局和合成图像生成做了大量的实验
2.相关工作:
大多数关于视觉描述语言的研究都是关于从图像生成标题的。最近,在文本到图像生成有了很多研究工作。大多数方法都利用了条件生成推理对抗网络(GANs)。虽然这些工作已经成功地生成了结果,质量也在不断提高,但在尝试合成具有多个交互对象的复杂场景的图像时,仍然面临着重大的挑战。受合成性原则的启发,我们的模型不使用GANs,而是通过连续生成包含组成场景的语义元素的对象(例如,以剪贴画、包围框或分段对象补丁的形式)来生成场景。
我们的工作还与之前的研究有关,前人也做了很多使用虚拟场景来反映和分析现实世界中的复杂情况。在[44]中,引入了一个图形化模型来从文本描述生成一个抽象场景。与前面的工作不同,我们的方法不使用语义解析器,而是从输入句子开始端到端的训练。我们的工作还涉及到像素级语义标签生成图像的研究[13,4,27],特别是[27],它提出了一种基于检索空间语义图的图像合成方法。我们的合成图像生成模型可选地使用[27]中的级联细化模块作为后处理步骤。与这些作品不同的是,我们的方法并没有给出场景中物体的空间布局,而是学会从文本中间接预测布局。
与我们的方法最接近的是[14,9,12]和[16],因为这些工作也试图预测显式的2D布局表示。Johnson等人提出了一种从结构场景图生成图像的图形卷积模型,被呈现的对象及其关系作为场景图的输入,而在我们的工作中,对象的存在是从文本中推断出来的。Hong等人使用传统的GANs进行图像合成,但与之前的工作不同的是,它在一个可分离的训练模块中生成中间表示。我们的工作还试图预测摄影图像合成的布局,不同的是,我们使用半参数检索模块生成像素级输出,而没有经过对抗性训练,展示了优越的结果。Kim等人从聊天日志中生成图形,而我们的工作使用的文本要少得多。Gupta等人提出了一种半参数化的生成类卡通图像的方法,呈现的对象也作为输入提供给模型,预测的布局前景和背景是由分开训练的模块执行。我们的方法是端到端的训练,超越了卡通场景。据我们所知,我们的模型是第一个在一个统一的框架下针对不同类型的场景(如框架场景、语义布局和合成图像)的工作。
3.模型各个部分介绍
Text2Scene采用了一个seq - seq框架,并介绍了空间推理和顺序推理的关键设计。具体来说,在每一个时间步骤中,模型通过以下三个步骤来修改背景画布:
- 模型关注输入文本,以决定下一个要添加的对象是什么,或者决定生成是否应该结束;
- 如果决定添加一个新对象,则模型在该对象的语言上下文中进行缩放,以决定其属性(如姿态、大小)和与周围环境的关系(如位置、与其他对象的交互);
- 模型将提取出的文本属性返回到画布和场景中,并将其转换为相应的视觉表示。
为了对这个过程进行建模,Text2Scene包含一个文本编码器,它以M个单词作为输入序列;包含一个对象解码器,它可以预测顺序的第T个对象Ot;一个属性解码器,它可以预测每个对象的属性。
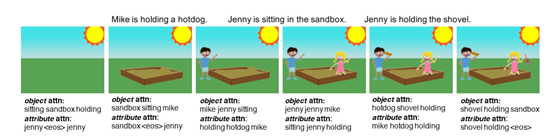
场景生成从最初的空画布开始,每个时间步长更新它。在合成图像生成任务中,我们还联合训练了一个前向嵌入嵌入网络,并将嵌入的向量作为目标属性。下图展示了一个抽象场景的步进式生成。
3.1文本编码器
我们的文本编码器是一个利用GRUs单元构成的双向循环网络。对于给定的句子,我们利用下面的公式计算每个单词wi:
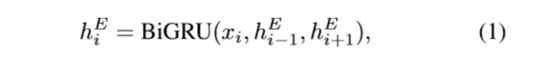
这里BiGRU是一个双向的GRU单元,xi为与第i个单词wi对应的词嵌入向量,hiE为编码当前单词及其上下文的隐藏向量。我们用hiE 和xi对,作为编码的文本特征,写作[hiE,xi]。
3.2对象和属性解码器
在每一步t,我们的模型通过对象表V(有k个特征)来预测下一个对象。使用上面生成的文本特征[hiE,xi]和当前画布Bt作为输入,使用卷积神经网络(CNN) 对Bt进行编码,得到一个C x H x W feature map,表示当前场景状态。我们使用卷积GRU (ConvGRU)对历史场景状态{htD}进行建模:

初始隐藏状态是通过文本编码器的最后隐藏状态来创建的。htD提供了场景中每个空间位置的时间动态信息表示。由于这种表示可能无法捕获小对象,因此上一步Ot-1中预测的对象的one-hot vector也作为输入提供给下游解码器。初始对象被设置为一个特殊的场景开始标记。
3.2.1基于注意力机制的对象解码器
我们的对象解码器是一个基于注意力机制的模型,输出一个对象词汇表V中所有可能的对象的似然得分。它以循环场景状态htD、文本特征[hiE,xi]和之前预测的对象Ot-1作为输入。
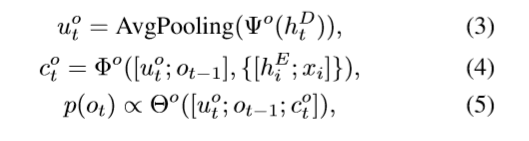
这里Ψ0是在htD上有空间attention的卷积网络。Ψ0的目标是收集对象预测所需的上下文,例如已经添加了哪些对象。已经参加的对象的空间特征通过平均池化得到一个向量Ut0。Φ0是基于文本的注意力模块,它使用[Ut0,Ot-1]去attend语言上下文[hiE,xi]和收集上下文向量Ct0。理想情况下,Ct0对所有描述的对象信息进行编码,这些对象到目前为止还没有添加到场景中。Θ0是一个双层感知器,它使用一个softmax函数,通过连接后面三个来预测下一个对象p(Ot)的可能性。
3.2.2基于注意力机制的属性解码器
基于注意力机制的属性解码器对响应对象Ot的属性集进行相似的预测。我们使用另一个注意力模块Φa捕捉Ot语言上下文信息,提取一个新的上下文向量Ct a更侧重于与当前对象Ot的内容。对于htD 每个空间位置,该模型预测一个位置似然和一组属性似然。这里,可能的位置被离散成相同的空间分辨率:

Φa是一个基于文本的注意力模块,将Ot与上下文[hiE,xi]对齐。Ψa是一个以图像为基础的注意力模块,旨在找到一个负担得起的位置来添加Ot。在与htD连接之前,Ct a在空间上被复制。最终的似然映射由卷积网络进行预测,接着是softmax分类器。对于连续属性{例如外观向量Qt用于程序检索(下一节)。我们使用l2-范数对输出标准化。
3.3 前向嵌入模块
我们预测了一个特定的属性:一个外观向量Qt,仅用于训练生成合成图像组合的模型。与其他属性一样,Qt对输出特征图中的每个位置进行预测,在测试时用于从其他图像中预先计算的对象段集合中检索类似的补丁。我们使用CNN训练一个patch的嵌入网络,将目标图像中的前向patch压缩成一个一维向量Ft。目标是使用triplet embedding loss来最小化Qt与Ft之间的l2-距离。