前言
任何一个有经验的系统管理员,都会告诉你: “ 正则表达式真是挺重要的! ” 为什么很重要呢?因为日常生活就使用的到啊!举个
例子来说, 在你日常使用 vim 作文书处理或程序撰写时使用到的 “ 搜寻 / 取代 ” 等等的功能, 这些举动要作的漂亮,就得要配合正则表达式
来处理啰!
简单的说,正则表达式就是处理字串的方法,他是以行为单位来进行字串的处理行为, 正则表达式通过一些特殊符号的辅助,可
以让使用者轻易的达到 “ 搜寻 / 删除 / 取代 ” 某特定字串的处理程序!
grep使用方法
正则表达式是一种字符模式,用于在查找过程中匹配制定的字符。
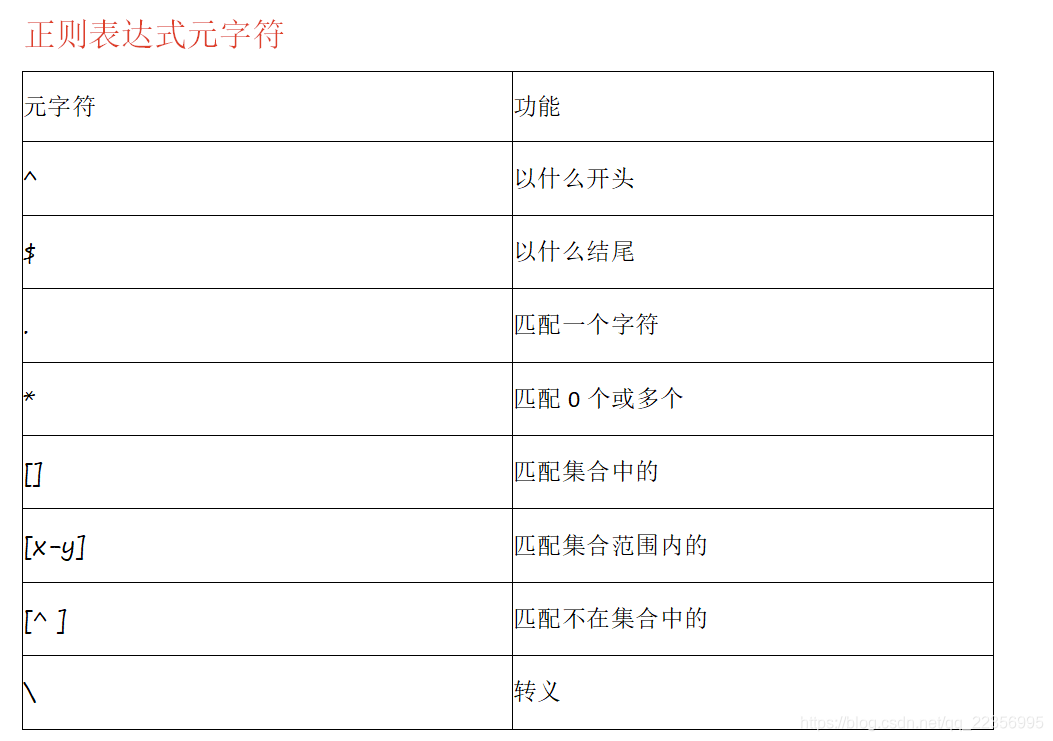
元字符通常在Linux中分为两类:
1.Shell元字符,由Linux Shell进行解析;
2.正则表达式元字符,由vi/grep/sed/awk等文本处理工具进行解析;
正则表达式一般以文本行进行处理,在进行下面实例之前,先为grep命令设置–color参数:
alias grep='grep --color=auto’
这样每次过滤出来的字符串都会带色彩了。
[dmtsai@study ~]$ grep [-A] [-B] [–color=auto] ’ 搜寻字串 ’ filename
选项与参数:
-A :后面可加数字,为 after 的意思,除了列出该行外,后续的 n 行也列出来;
-B :后面可加数字,为 befer 的意思,除了列出该行外,前面的 n 行也列出来;
–color=auto 可将正确的那个撷取数据列出颜色
范例一:用 dmesg 列出核心讯息,再以 grep 找出内含 qxl 那行
[dmtsai@study ~]$ dmesg | grep ‘qxl’
[ 0.522749] [drm] qxl: 16M of VRAM memory size
[ 0.522750] [drm] qxl: 63M of IO pages memory ready ( VRAM domain )
[ 0.522750] [drm] qxl: 32M of Surface memory size
[ 0.650714] fbcon: qxldrmfb ( fb0 ) is primary device
[ 0.668487] qxl 0000:00:02.0: fb0: qxldrmfb frame buffer device
#dmesg 可列出核心产生的讯息!包括硬件侦测的流程也会显示出来。
#使用的显卡是 QXL 这个虚拟卡,通过 grep 来 qxl 的相关信息,可发现如上信息。
范例二:承上题,要将捉到的关键字显色,且加上行号来表示:
[dmtsai@study ~]$ dmesg | grep -n --color=auto ‘qxl’
515:[ 0.522749] [drm] qxl : 16M of VRAM memory size
516:[ 0.522750] [drm] qxl : 63M of IO pages memory ready ( VRAM domain )
517:[ 0.522750] [drm] qxl : 32M of Surface memory size
529:[ 0.650714] fbcon: qxl drmfb ( fb0 ) is primary device
539:[ 0.668487] qxl 0000:00:02.0: fb0: qxl drmfb frame buffer device
#除了 qxl 会有特殊颜色来表示之外,最前面还有行号喔!其实颜色显示已经是默认在 alias 当中了!
范例三:承上题,在关键字所在行的前两行与后三行也一起捉出来显示
[dmtsai@study ~]$ dmesg | grep -n -A3 -B2 --color=auto ‘qxl’
#你会发现关键字之前与之后的数行也被显示出来!这样可以让你将关键字前后数据捉出来进行分析啦
创建一个测试使用的文件re-file,内容:
$vim re-file
I had a lovely time on our little picnic.Lovers were all around us. It is springtime. Ohlove, how much I adore you.
Do you knowthe extent of my love? Oh, by the way, I thinkI lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.is forever. I live for you. It’s hard to get back in the groove.
$ vim linux.txt
Linux is a good
god assdxw bcvnbvbjk
greatttttt wexcvxc
operaaaating dhfghfvx
gooodfs awrerdxxhkl
gdsystem awxxxx
glad
good

实例操作
匹配以love开头的所有行
$ grep ‘^love’ re-file
love, how much I adore you. Do you know
匹配love结尾的所有行
$ grep ‘love$’ re-file
clover. Did you see them? I can only hope love.
匹配以l开头,中间包含两个字符,结尾是e的所有行
$ grep ‘l…e’ re-file
I had a lovely time on our little picnic.
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
is forever. I live for you. It’s hard to get back in the
匹配0个或多个空行,后面是love的字符
$ grep ’ *love’ re-file
I had a lovely time on our little picnic.
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
匹配love或Love
$ grep ‘[Ll]ove’ re-file # 对l不区分大小写
I had a lovely time on our little picnic.
Lovers were all around us. It is springtime. Oh
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
匹配A-Z的字母,其次是ove
$ grep ‘[A-Z]ove’ re-file
Lovers were all around us. It is springtime. Oh
匹配不在A-Z范围内的任何字符行,所有的小写字符
$ grep ‘[^A-Z]’ re-file
I had a lovely time on our little picnic.
Lovers were all around us. It is springtime. Oh
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
is forever. I live for you. It’s hard to get back in the
groove.
匹配love.
$ grep ‘love.’ re-file
clover. Did you see them? I can only hope love.
匹配空格
$ grep ‘^$’ re-file
匹配任意字符
$ grep ‘.*’ re-file
I had a lovely time on our little picnic.
Lovers were all around us. It is springtime. Oh
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
is forever. I live for you. It’s hard to get back in the
groove.
前面o字符重复2到4次
$ grep ‘o{2,4}’ re-file
groove.
重复o字符至少2次
$ grep ‘o{2,}’ re-file
groove.
重复0字符最多2次
$ grep ‘o{,2}’ re-file
I had a lovely time on our little picnic.
Lovers were all around us. It is springtime. Oh
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
is forever. I live for you. It’s hard to get back in the
groove.
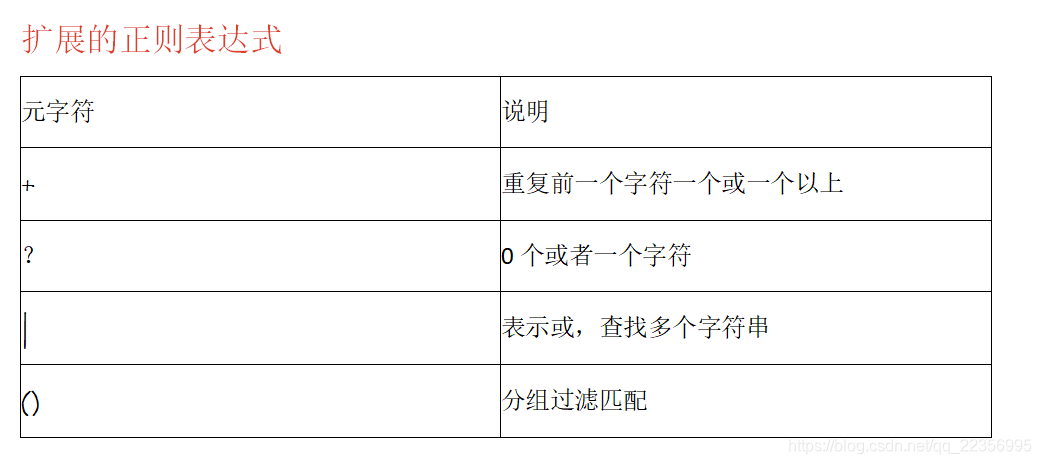
重复前一个字符一个或一个以
$ egrep “go+d” linux.txt
Linux is a good
god assdxw bcvnbvbjk
gooodfs awrerdxxhkl
good
0个或者一个字符
ansheng@Ubuntu:/tmp$ egrep “go?d” linux.txt
god assdxw bcvnbvbjk
gdsystem awxxxx
或,查找多个字符串
$ egrep “gd|good” linux.txt
Linux is a good
gdsystem awxxxx
good
分组过滤匹配
$ egrep “g(la|oo)d” linux.txt
Linux is a good
glad
good
sed使用方法
[dmtsai@study ~]$ sed [-nefr] [ 动作 ]
选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到屏幕上。
但如果加上 -n 参数后,则只有经过 sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在指令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以执行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正则表达式的语法。(默认是基础正则表达式语法)
-i :直接修改读取的文件内容,而不是由屏幕输出。
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表“选择进行动作的行数”,举例来说,如果我的动作
是需要在 10 到 20 行之间进行的,则“ 10,20[动作行为] ”
function 有下面这些咚咚:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正则表达式!
例如 1,20s/old/new/g 就是啦!
以行为单位的新增 / 删除功能
范例一:将 /etc/passwd 的内容列出并且打印行号,同时,请将第 2~5 行删除!
[dmtsai@study ~]$ nl /etc/passwd | sed ‘2,5d’
1 root❌0:0:root:/root:/bin/bash
6 sync❌5:0:sync:/sbin:/bin/sync
7 shutdown❌6:0:shutdown:/sbin:/sbin/shutdown
…(后面省略)…
范例二:承上题,在第二行后(亦即是加在第三行)加上 “drink tea?” 字样!
[dmtsai@study ~]$ nl /etc/passwd | sed ‘2a drink tea’
1 root❌0:0:root:/root:/bin/bash
2 bin❌1:1:bin:/bin:/sbin/nologin
drink tea
3 daemon❌2:2:daemon:/sbin:/sbin/nologin
…(后面省略)…
范例三:在第二行后面加入两行字,例如 “Drink tea or …” 与 “drink beer?”
[dmtsai@study ~]$ nl /etc/passwd | sed '2a Drink tea or …\
drink beer ?’
1 root❌0:0:root:/root:/bin/bash
2 bin❌1:1:bin:/bin:/sbin/nologin
Drink tea or …
drink beer ?
3 daemon❌2:2:daemon:/sbin:/sbin/nologin
…(后面省略)…
以行为单位的取代与显示功能
范例四:我想将第 2-5 行的内容取代成为 “No 2-5 number” 呢?
[dmtsai@study ~]$ nl /etc/passwd | sed ‘2,5c No 2-5 number’
1 root❌0:0:root:/root:/bin/bash
No 2-5 number
6 sync❌5:0:sync:/sbin:/bin/sync
…(后面省略)…
范例五:仅列出 /etc/passwd 文件内的第 5-7 行
[dmtsai@study ~]$ nl /etc/passwd | sed -n ‘5,7p’
5 lp❌4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync❌5:0:sync:/sbin:/bin/sync
7 shutdown❌6:0:shutdown:/sbin:/sbin/shutdown
部分数据的搜寻并取代的功能
格式类似 sed ‘s/ 要被取代的字串 / 新的字串 /g’
1、这个取得 IP 数据的范例,一段一段的来处理
步骤一:先观察原始讯息,利用 /sbin/ifconfig 查询 IP 为何?
[dmtsai@study ~]$ /sbin/ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::5054:ff:fedf:e174 prefixlen 64 scopeid 0x20
ether 52:54:00:df:e1:74 txqueuelen 1000 ( Ethernet )
…(以下省略)…
#因为我们还没有讲到 IP ,这里你先有个概念即可啊!我们的重点在第二行,
#也就是 192.168.1.100 那一行而已!先利用关键字捉出那一行!
步骤二:利用关键字配合 grep 撷取出关键的一行数据
[dmtsai@study ~]$ /sbin/ifconfig eth0 | grep 'inet ’
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
#当场仅剩下一行!要注意, CentOS 7 与 CentOS 6 以前的 ifconfig 指令输出结果不太相同,
#鸟哥这个范例主要是针对 CentOS 7 以后的喔!接下来,我们要将开始到 addr: 通通删除,
#就是像下面这样:
#inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
#上面的删除关键在于“ ^.*inet ”啦!正则表达式出现! _
步骤三:将 IP 前面的部分予以删除
[dmtsai@study ~]$ /sbin/ifconfig eth0 | grep 'inet ’ | sed ‘s/^.*inet //g’
192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
#仔细与上个步骤比较一下,前面的部分不见了!接下来则是删除后续的部分,亦即:
192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
#此时所需的正则表达式为:“ ’ netmask.$ ”就是啦!
步骤四:将 IP 后面的部分予以删除
[dmtsai@study ~]$ /sbin/ifconfig eth0 | grep 'inet ’ | sed ‘s/^.*inet //g’ \
| sed ‘s/ netmask.$//g’
192.168.1.100
2 、假设我只要 MAN 存在的那几行数据, 但是含有 # 在内的注解我不想要,而且空白
行我也不要!此时该如何处理呢?可以通过这几个步骤来实作看看
步骤一:先使用 grep 将关键字 MAN 所在行取出来
[dmtsai@study ~]$ cat /etc/man_db.conf | grep ‘MAN’
#MANDATORY_MANPATH manpath_element
#MANPATH_MAP path_element manpath_element
#MANDB_MAP global_manpath [relative_catpath]
#every automatically generated MANPATH includes these fields
…(后面省略)…
步骤二:删除掉注解之后的数据!
[dmtsai@study ~]$ cat /etc/man_db.conf | grep ‘MAN’| sed ‘s/#.KaTeX parse error: Expected 'EOF', got '#' at position 50: …..(后面省略).... **#̲从上面可以看出来,原本注解的数… cat /etc/man_db.conf | grep ‘MAN’| sed 's/#.KaTeX parse error: Expected group after '^' at position 14: //g' | sed '/^̲/d’
MANDATORY_MANPATH /usr/man
MANDATORY_MANPATH /usr/share/man
MANDATORY_MANPATH /usr/local/share/man
…(后面省略)…
直接修改文件内容(危险动作)
sed 的 “ -i ” 选项可以直接修改文件内容,这功能非常有帮助!
下载的 regular_express.txt 文件来测试
范例六:利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 !
[dmtsai@study ~]$ sed -i ‘s/.$/!/g’ regular_express.txt
#上头的 -i 选项可以让你的 sed 直接去修改后面接的文件内容而不是由屏幕输出喔!
#这个范例是用在取代!请您自行 cat 该文件去查阅结果啰!
范例七:利用 sed 直接在 regular_express.txt 最后一行加入 “# This is a test”
[dmtsai@study ~]$ sed -i ‘$a # This is a test’ regular_express.txt
#由于 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增啰!
awk :好用的数据处理工具
运行格式 [dmtsai@study ~]$ awk ’ 条件类型 1{ 动作 1} 条件类型 2{ 动作 2} …’ filename
awk 后面接两个单引号并加上大括号 {} 来设置想要对数据进行的处理动作。 awk 可以处理后续接的文件,也可以读取来自前个指令的
standard output 。
例1 用 last 可以将登陆者的数据取出来
dmtsai@study ~]$ last -n 5 <==仅取出前五行
dmtsai pts/0 192.168.1.100 Tue Jul 14 17:32 still logged in
dmtsai pts/0 192.168.1.100 Thu Jul 9 23:36 - 02:58 ( 03:22 )
dmtsai pts/0 192.168.1.100 Thu Jul 9 17:23 - 23:36 ( 06:12 )
dmtsai pts/0 192.168.1.100 Thu Jul 9 08:02 - 08:17 ( 00:14 )
dmtsai tty1 Fri May 29 11:55 - 12:11 ( 00:15 )
例2 取出帐号与登陆者的 IP ,且帐号与 IP 之间以 [tab] 隔开
[dmtsai@study ~]$ last -n 5 | awk ‘{print $1 “\t” $3}’
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai Fri
awk 的内置变量

以上面 last -n 5 的例子来做说明,如果我想要:
列出每一行的帐号(就是 $1 );
列出目前处理的行数(就是 awk 内的 NR 变量)
并且说明,该行有多少字段(就是 awk 内的 NF 变量)
[dmtsai@study ~]$ last -n 5| awk ‘{print $1 "\t lines: " NR "\t columns: " NF}’
dmtsai lines: 1 columns: 10
dmtsai lines: 2 columns: 10
dmtsai lines: 3 columns: 10
dmtsai lines: 4 columns: 10
dmtsai lines: 5 columns: 9
#注意喔,在 awk 内的 NR, NF 等变量要用大写,且不需要有钱字号 $ 啦!
awk 的逻辑运算字符
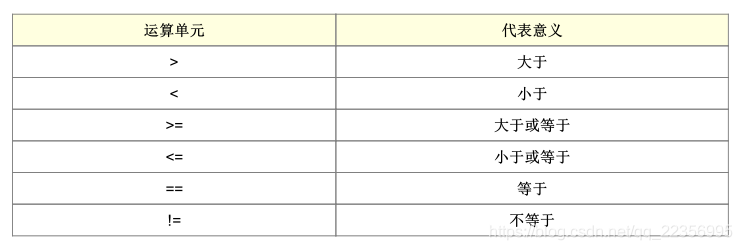
在 /etc/passwd 当中是以冒号 “:” 来作为字段的分隔, 该文件中第一字段为帐号,第三字段则是 UID 。那假设我要查阅,第三栏小于 10 以下的数据,并且仅列出帐号与第三栏, 那么可以这样做:
[dmtsai@study ~]$ cat /etc/passwd | awk ‘{FS=":"} $3 < 10 {print $1 "\t " $3}’
root❌0:0:root:/root:/bin/bash
bin 1
daemon 2
…(以下省略)…
不过,怎么第一行没有正确的显示出来呢?这是因为我们读入第一行的时候,那些变量 $1,
cat /etc/passwd | awk ‘BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}’
root 0
bin 1
daemon 2
…(以下省略)…
除了 BEGIN 之外,我们还有 END 呢!另外,如果要用 awk 来进行 “ 计算功能 ” 呢?以下面的例子来看, 假设我有一个薪资数据表文件名为 pay.txt ,内容是这样的:
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
如何帮我计算每个人的总额呢?而且我还想要格式化输出喔!我们可以这样考虑:
第一行只是说明,所以第一行不要进行加总 ( NR==1 时处理);
第二行以后就会有加总的情况出现 ( NR>=2 以后处理)
[dmtsai@study ~]$ cat pay.txt | \
awk ‘NR==1{printf “%10s %10s %10s %10s %10s\n”,$1,$2,$3,$4,“Total” }
NR>=2{total = $2 + $3 + $4
printf “%10s %10d %10d %10d %10.2f\n”, $1, $2, $3, $4, total}’
Name 1st 2nd 3th Total
VBird 23000 24000 25000 72000.00
DMTsai 21000 20000 23000 64000.00
Bird2 43000 42000 41000 126000.00
awk 的指令间隔:所有 awk 的动作,亦即在 {} 内的动作,如果有需要多个指令辅助时,可利用分号 “;” 间隔, 或者直接以 [Enter] 按键来隔开每个指令,例如上面的范例中,鸟哥共按了三次 [enter] 喔!
逻辑运算当中,如果是 “ 等于 ” 的情况,则务必使用两个等号 “==” !
格式化输出时,在 printf 的格式设置当中,务必加上 \n ,才能进行分行!
与 bash shell 的变量不同,在 awk 当中,变量可以直接使用,不需加上 $ 符号
awk 的动作内 {} 也是支持 if (条件) 的喔! 举例来说,上面的指令可以修订成为这
样:
[dmtsai@study ~]$ cat pay.txt | \
awk ‘{if ( NR==1 ) printf “%10s %10s %10s %10s %10s\n”,$1,$2,$3,$4,“Total”}
NR>=2{total = $2 + $3 + $4
printf “%10s %10d %10d %10d %10.2f\n”, $1, $2, $3, $4, total}’
总结
grep 与 egrep 在正则表达式里面是很常见的两支程序,其中, egrep 支持更严谨的正则表达式的语法;grep全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
sed擅长对数据行进行处理,sed是一种流编辑器,处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。利用sed命令可以将数据行进行替换、删除、新增、选取等特定工作;
awk 可以使用 “ 字段 ” 为依据,进行数据的重新整理与输出;擅长对数据列进行处理,就是把数据逐行的读入,以空格为默认分隔符再将每行切断,对切断的部分再进行分析处理。
