前言
随着网站安全做的越来越好,不少网站,直接去爬取数据是无法爬出来的,必须要验证登陆,即登陆之后才能做后面的操作,因此需要解决的第一步就是登陆
登陆的常用方式:
1、使用request库,模拟post请求
2、使用框架自己集成的,比如在使用scrapy的时候,可以直接模拟登陆
3、使用selenium模拟浏览器登陆
前两种之前有大概的分享,下面使用selenium的方式模拟登陆
selenium简介
- Selenium最初是由ThoughtWorks公司一个叫Jason R. Huggins的工程师和他的团队开发出来
- Selenium是仅针对Web系统的一款自动化测试工具
- Selenium是免费的、开源的,很多公司选择Selenium和它是免费的有很大关系
- Selenium不是一个工具,它是一系列工具的总称
- Selenium支持多种编程语言
- Selenium支持多种浏览器
- Selenium可以运行在多个平台上
对于开发人员来说,使用Selenium的好处是显而易见的,通过使用selenium的API,可以提取并分析html上的页面元素,并模拟用户的操作行为,进行事件处理等操作,比如爬虫,登陆到主页后,完全可以通过保存的本地html文件进行页面的数据解析,是不是很方便
总体思路
1、进入登陆页面
2、分析登陆表单输入框中用户名和密码的位置
3、调用driver,将自己的用户名和密码输入,完成自动登录
4、登陆时,建议中间停顿一小段时间,避免被发现
1、环境准备
下载chromedriver.exe,放在本地的某个文件夹下,这里提供一个下载的网站,首先看一下自己的chrome浏览器版本,然后下载对应版本的,可以在浏览器输入:chrome://version进行查看
http://chromedriver.storage.googleapis.com/index.html

下面通过一个简单的例子,模拟登陆豆瓣网站来说明,首先分析一下代码的思路
2、获取登陆的页面
要说的第一个注意点,进入到登陆页面后,默认情况下是跳转到密码登陆,但这个并不确定,因此需要首先跳转到这个页面,这一步容易忽略,否则后面driver打开浏览器的时候就动不了
3、完整代码
from selenium import webdriver
from scrapy.selector import Selector
import time
browser = webdriver.Chrome(executable_path="D:/logs/python代码/driver/chromedriver.exe")
#知乎登陆
html_url = "https://accounts.douban.com/passport/login?source=main"
browser.get(html_url)
#切换到登陆页面
browser.find_element_by_xpath("//div[@class='account-body-tabs']/ul/li[2]").click()
#找到登录用的输入框
username='用户名'
password='密码'
browser.find_element_by_xpath("//div[@class='account-form-field']/input[@id='username']").send_keys(username)
time.sleep(3)
browser.find_element_by_xpath("//div[@class='account-form-field']/input[@id='password']").send_keys(password)
time.sleep(3)
#调用点击登陆的按钮进行登陆
browser.find_element_by_xpath("//div[@class='account-form-field-submit ']/a").click()
print("success")
由于这里没有验证码,因此代码并不复杂,直接运行即可,观察效果,会自动打开浏览器并完成登陆并进入到首页
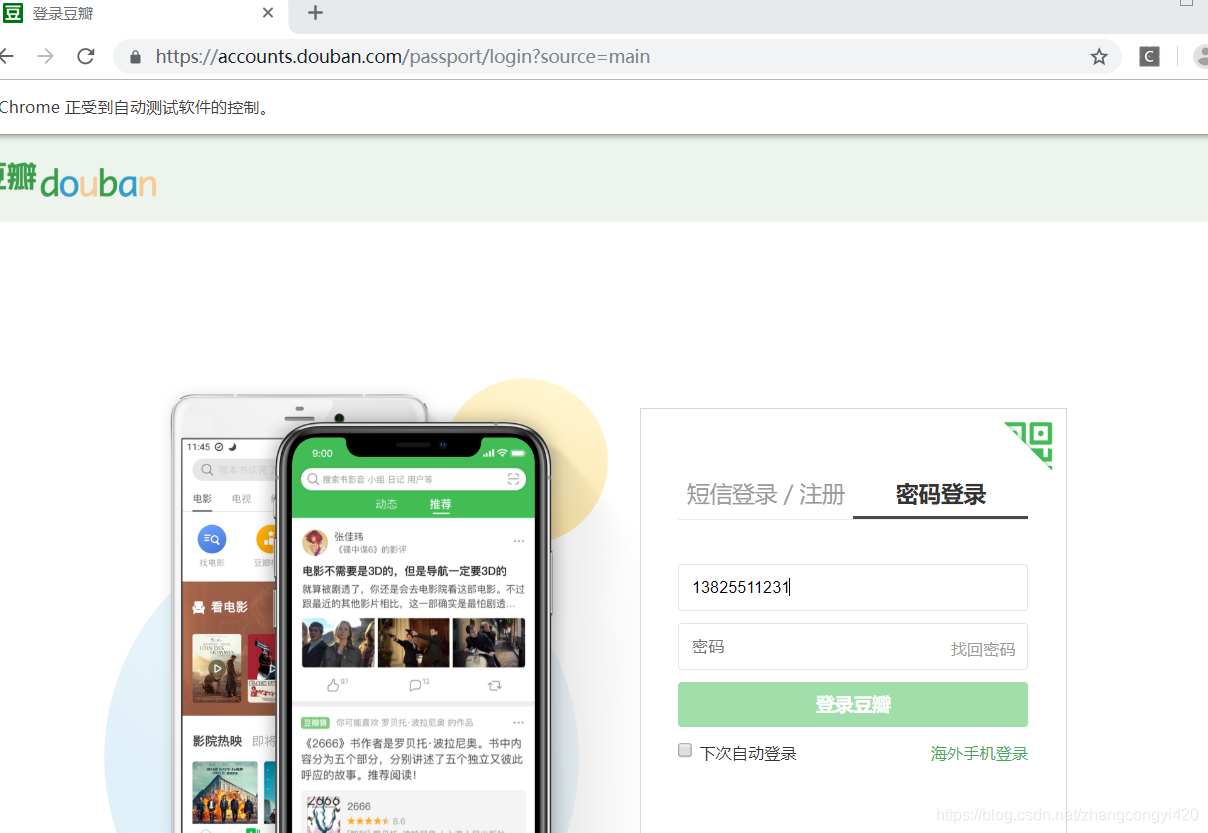
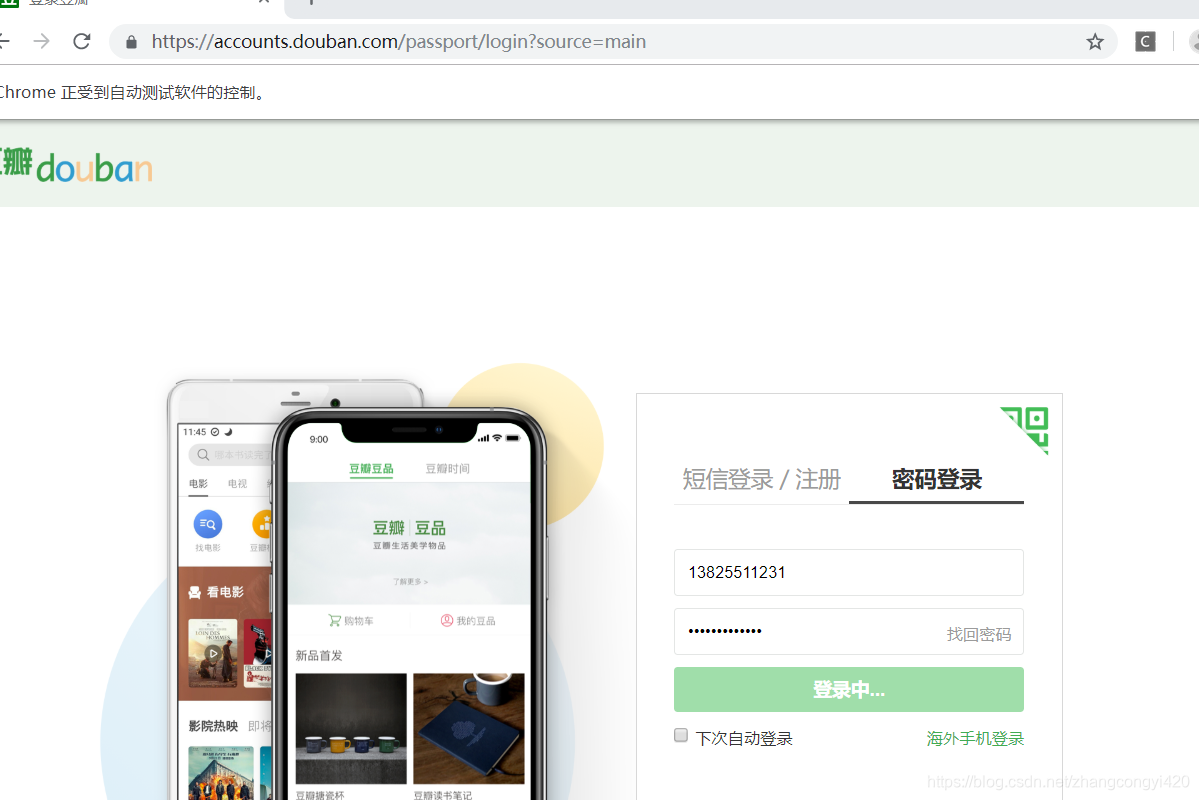
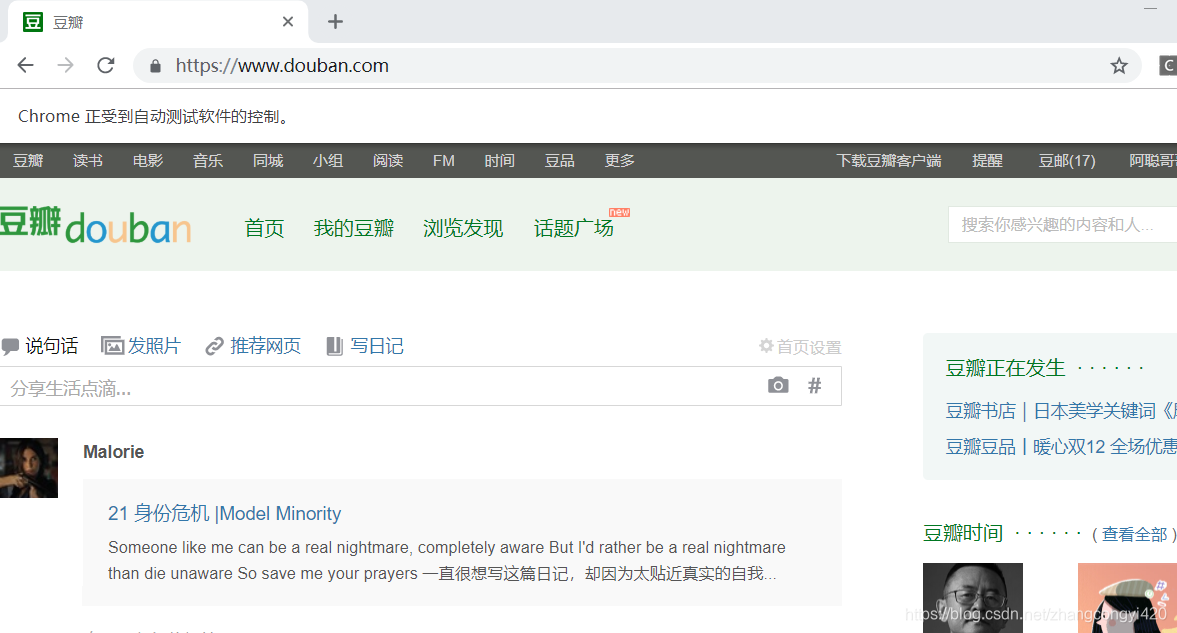
4、带有验证码的登陆
这个实现起来稍复杂点,总体思路前几步仍然和上面相同,不同的地方在于对验证码的处理上,对于验证码的处理主要分为下面两点:
- 保存验证码图片到本地
- 通过第三方库或者自己封装代码识别验证码
- 将识别后的验证码信息一起填入表单并提交表单进行登陆
下面以登陆去哪儿网为例进行简单说明:
下面直接贴出代码,对代码部分做一些解释
import requests
from chat1.tools.chaojiying import Chaojiying_Client# 必须先把官方的Api文件放到同级目录下
from selenium import webdriver
import time
headers = {
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36',
}
def get_img_num(driver):
driver.get_screenshot_as_png()
time.sleep(2)
account = '超级鹰用户名'
password = '超级鹰密码'
id = '902752'
image_kind = 1902 # 四位英文或数字
img_url = "https://user.qunar.com/captcha/api/image?k={en7mni(z&p=ucenter_login&c=ef7d278eca6d25aa6aec7272d57f0a9a"
cookies = dict()
#driver = webdriver.Chrome(executable_path="D:/logs/python代码/driver/chromedriver.exe")
for one in driver.get_cookies():
cookies[one['name']] = one['value']
response = requests.get(img_url, cookies=cookies)
with open('D:\\logs\\python代码\\验证码.jpg', 'wb') as fp:
fp.write(response.content)
chaojiying = Chaojiying_Client(account, password, id)
im = open('D:\\logs\\python代码\\验证码.jpg', 'rb').read()
image_num = chaojiying.PostPic(im, image_kind)
if image_num['err_str'] == 'OK':
print('验证码识别成功')
print('验证码是{0}'.format(image_num['pic_str']))
return image_num['pic_str']
else:
print('验证码识别失败')
from lxml import etree
# 此处登录窗口没有在iframe框架里面,如果再iframe框架里面一定要先进入框架里面
def login():
# 记得先在主页点一次
url = 'http://user.qunar.com/passport/login.jsp?ret=https%3A%2F%2Fwww.qunar.com%2F%3Fex_track%3Dauto_4e0d874a'
driver = webdriver.Chrome(executable_path="D:/logs/python代码/driver/chromedriver.exe")
driver.get(url)
driver.implicitly_wait(10)
# 切换登录模式为账号密码登录
first_botton = driver.find_element_by_class_name('pwd-login')
first_botton.click()
#使用zha那个号登陆
driver.find_element_by_xpath("//label[@for='radio_normal'][1]").click()
#获取用户名
username = driver.find_element_by_xpath("//div[@class='field-login']/div/input[@name='username']")
username.clear()
username.send_keys('你的用户名')
time.sleep(3)
# 获取密码
password = driver.find_element_by_xpath("//input[@name='password']")
password.clear()
password.send_keys('你的用密码')
time.sleep(2)
image_input = driver.find_element_by_xpath("//input[@name='vcode']")
image_input.clear()
image_num = get_img_num(driver)
image_input.send_keys(image_num) # 输入验证码
time.sleep(2)
#点击登录按钮
login_button = driver.find_element_by_id('submit') # 点击登录按钮
login_button.click()
cookies = driver.get_cookies()
print(cookies)
driver.implicitly_wait(10)
driver.refresh()
print(driver.page_source)
if __name__ == '__main__':
login()
这里识别图片验证码,使用了“超级鹰”平台的API,这个是不少网友推荐的一种比较好的识别验证码的平台,收费很低,进去注册个账号就可以了
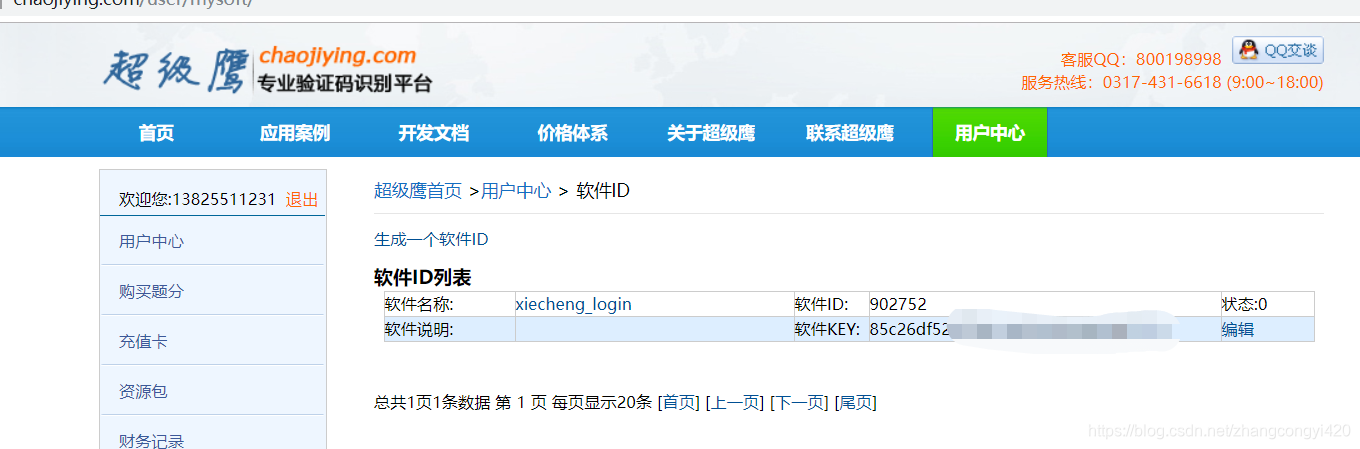
然后把官网的demo文件下载下来,放到工程下的某个文件夹里
放到项目里面,简单配置一下官方代码,把平台分配给你的信息填进去,然后找一个图片验证码测试一下,
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password= password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = Chaojiying_Client('你的账户', '你的密码', '85c26df5207f8e14e3b996aab04d371c') #用户中心>>软件ID 生成一个替换 96001
im = open('D:\\logs\\python代码\\11.jpg', 'rb').read()
#1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
print(chaojiying.PostPic(im, 1902) )
效果如下,

整个代码部分就是这么多,只需要把超级鹰识别验证码的部分封装一下融合到登陆的逻辑中即可
本篇到这里就结束了,最后感谢观看!
