分治算法
一.分治算法思想
把一个复杂的大问题分解成一个一个规模较小的相同的子问题,就是分治算法。
二.分治算法的问题特征
- 该问题的规模缩小到一定的程度就可以容易地解决
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
- 利用该问题分解出的子问题的解可以合并为该问题的解;
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
也就是说这个问题能分解,且分解出来子问题的规模相同,相互独立(和动态规划的区别就是:动态规划的子问题具有重叠性,重叠得越多,动规的效率性就更显著)。通过依次解决子问题,得到子问题的答案,然后合并成原问题的解。
三.分治算法的步骤
1.分解(Divide):将问题划分为一些子问题,子问题的形式与原问题一样,只是规模更小。
2.解决(Conquer):递归地求解出子问题。如果子问题规模足够小,则停止递归,直接求解。
3.合并(Combine):将子问题的解组合成原问题的解。
四.分治算法的常见应用
1.二分查找
先确定待查记录所在的范围(区间),然后逐步缩小范围,直到找到或者找不到该记录为止。
二分查找只适用于有序表,且仅限于顺序存储结构;
代码:
int Search_Bin(SSTable ST,keyType key)
{ //在有序表ST中折半查找其关键字等于key的数据元素。
//若找到,则函数值为该元素在表中的位置,否则为0。
low=1; high=ST.length; //置区间初值;
while(low<=high)
{
mid=(low+high)/2; //计算总结元素坐标;
if(key==ST.elem[mid].key)
return mid; //找到待查元素;
else if(key<ST.elem[mid].key)
high=mid-1; //调整右边界;
//继续在前半区进行查找;
else
low=mid+1; //调整左边界;
//继续在后半区进行查找;
}
return 0; //顺序表中不存在待查元素;
2.大整数乘法
KaraTsuba乘法:–百度百科
普通乘法的复杂度是n2,而Karatsuba算法的复杂度仅为3nlog3≈3n1.585(log3是以2为底的);
Karatsuba算法主要应用于两个大数的相乘,原理是将大数分成两段后变成较小的数位,然后做3次乘法,并附带少量的加法操作和移位操作。
现有两个大数,x,y。
首先将x,y分别拆开成为两部分,可得x1,x0,y1,y0。他们的关系如下:
x = x1 * 10m + x0;
y = y1 * 10m + y0。其中m为正整数,m < n,且x0,y0 小于 10m。
那么 xy = (x1 * 10m + x0)(y1 * 10m + y0)
=z2 * 102m + z1 * 10m + z0,其中:
z2 = x1 * y1;
z1 = x1 * y0 + x0 * y1;
z0 = x0 * y0。
此步骤共需4次乘法,但是由Karatsuba改进以后仅需要3次乘法。因为:
z1 = x1 * y0+ x0 * y1
z1 = (x1 + x0) * (y1 + y0) - x1 * y1 - x0 * y0,
故z1 便可以由一次乘法及加减法得到。
伪代码:
procedure Karatsuba(num1,num2)
{
if((num1<10)||(num2<10))
return num1 * num2
m = max(size(num1),size(num2))
m2 = m/2
//max比较num1和num2的长度大小;
high1, low1 = split_at(num1, m2)
high2, low2 = split_at(num2, m2)
//split_at字符串拆分;
//以m2为固定长度拆分;
z0 = karatsuba(low1, low2)
z1 = karatsuba((low1 + high1),(low2 + high2))
z2 = karatsuba(high1,high2)
return(z2 * 10^(m)) + ((z1 - z2 - z0)* 10^(m/2)) + (z0)
}
3.Strassen矩阵乘法
两个矩阵的乘法仅当第一个矩阵B的列数和另一个矩阵A的行数相等时才能定义。如A是m×n矩阵和B是n×p矩阵,它们的乘积AB是一个m×p矩阵,它的一个元素其中 1 ≤ i ≤ m, 1 ≤ j ≤ p。
把八次乘法变成七次乘法和一次加减法;


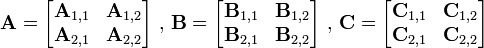
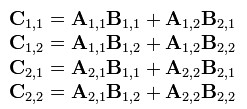
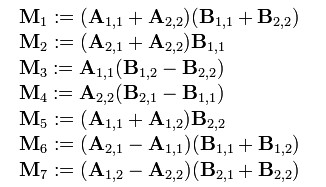
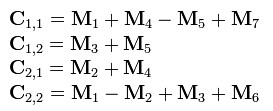
–转载别人博客园的
4.棋盘覆盖
5.归并排序
把两个已排序的子序列合并成一个有序序列的过程。
6.快速排序
通过一趟排序将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这个两部分记录继续进行排序,已达到整个序列有序。
代码:
void QuickSort(SqList &L)
{ //对顺序表L进行快排;
QSort(L,1,L.length);
}
void QSort(SqList &l,int low,int high)
{ //对顺序表L中的子序列表L.r[low..high]作快速排序;
if(low<high) //长度大于1;
{
pivotloc=Partition(L,low,high)
// 将L.r[low..high]一分为二;
QSort(L,low,pivotloc-1);//对低子表递归排序;
QSort(L,pivotloc+1,high);//对高子表递归排序
}
}
int Partition(SqList &L,int low,int high)
{//交换顺序表L中子表r[low..high]的记录,枢轴记录到位
//并返回其所在位置,此时在它之前(后)的记录均不大(小)于它
L.r[0]=L.r[low];
//用子表的第一个记录作为枢轴记录
pivotkey=L.r[low].key;
//枢轴记录关键字
while(low<high)
{ //从表的两端交替的向中间扫描扫描
while(low<high&&L.r[high].key>=pivotkey)
--high;
L.r[low]=L.r[high];
//将比枢轴记录小的记录移到低端
while(low<high&&L.r[high].key<=pivotkey)
++low;
L.r[high]=L.r[low];
//将比枢轴记录大的记录移到高端
}
L.r[low]=L.r[0]; //枢轴记录到位
return low; //返回枢轴位置
}
