该系列仅在原课程基础上部分知识点添加个人学习笔记,或相关推导补充等。如有错误,还请批评指教。在学习了 Andrew Ng 课程的基础上,为了更方便的查阅复习,将其整理成文字。因本人一直在学习英语,所以该系列以英文为主,同时也建议读者以英文为主,中文辅助,以便后期进阶时,为学习相关领域的学术论文做铺垫。- ZJ
Coursera 课程 |deeplearning.ai |网易云课堂
转载请注明作者和出处:ZJ 微信公众号-「SelfImprovementLab」
知乎:https://zhuanlan.zhihu.com/c_147249273
CSDN:http://blog.csdn.net/JUNJUN_ZHAO/article/details/78913044
2.9 logisticlogistic 回归中的梯度下降法
Logistic Regression Gradient Descent
(字幕来源:网易云课堂)

welcome back, in this video we’ll talk about how to compute derivatives for you,to implement gradient descent for logisticlogistic regression.but I want to start explaining things this way to get you familiar with these ideas.so that hopefully you’ll make a bit more sense when we talk about full fledged neural networks.
欢迎回来,在本节我们将讨论怎样计算偏导数,来实现 logisticlogistic 回归的梯度下降 有点大材小用了,但是我认为以这种方式来讲解,可以更好地理解梯度下降,从而在讨论神经网络时,可以更深刻而全面地理解神经网络。
so let’s dive into gradient descent for logisticlogistic and b,in addition to the feature values x1 x2
接下来开始学习 logisticlogistic。
so these things in a computation graph get used to compute z which is w1w1 regression what we want to do,is to modify the parameters w and b,in order to reduce this loss,we’ve described before propagation steps,of how you actually compute the loss on a single training example.
因此用来计算zz 的值,来最小化损失函数, 在前面我们已经前向传播步骤,在单个训练样本上计算损失函数。
now let’s talk about how you can go backwards to talk to compute the derivatives,here’s the cleaned up version of the diagram,because what we want to do is compute derivatives respect to this loss,the first thing we want to do we’re going backwards is to compute the derivative of this loss with respect to the script over there,with respect to this variable a,and so in the code,you know you just use da right to denote this variable,and it turns out that if you are familiar with calculus,you can show that this ends up being negative y over a,plus one minus y over one minus a,and the way you do that is you take the formula,for the loss and if you are familiar with calculus,you can compute the derivative with respect to the variable lowercase a and you get this formula.
现在让我们来 讨论怎样向后计算偏导数,这是整洁版本的图,要想计算损失函数L的导数,首先我们要,向前一步 先计算损失函数的导数,这里有个标记,关于变量aa的导数,就是这个式子。

but if you’re not familiar of calculus,don’t worry about it,we’ll provide the derivative formulas you need,through out this course so if you are a expert in calculus,you’ll encourage you to look up the formula for the loss from their previous slide,and try to get director for respect to a using you know calculus,but if you don’t know enough calculus to do that,don’t worry about it,now having computed this quantity or da,the derivative of your final output variable respect to a,you can then go backwards and it turns out that you can show dz,which this is the Python code variable name,this is going to be you know the derivative of the loss,with respect to 关于 z or for L you can really write,the loss including a and y explicitly as parameters,or not right give either type of notation is equally acceptable they can show that,this is equal to a minus y,just a couple comments only for those of you did a experts in calculus.
如果你不熟悉微积分,也不必太担心,我们会列出本课程涉及的所有求导公式,因此 如果你非常熟悉微积分,我们鼓励你,通过上一张幻灯片中的损失函数公式,使用微积分 直接求出变量aa,给熟悉微积分的人解释一下。
if you’re not explain calculus,don’t worry about it,but it turns out that this right dL dz,this can be expressed as dL da times,da dz and it turns out that da dz,this turns out to be a times 1 minus a,and dL da we are previously worked out over here,and so if you take these two quantities dL da,which is this term together with da dz,which is this term and just take these two things,and multiply them you can show that you,the equation simplifies the a minus y,so that’s how you derive it,and this is really the chain rule that,and this is really the chain rule that.
如果你对微积分不熟悉,也不用担心,实际上 dL/dzdL/dz),这个推导的过程,就是我之前提到过的“链式法则”。

I briefly clue to you before ok,so feel free to go through that calculation yourself,if you are knowledgeable calculus,but if you aren’t all you need to know is that,you can compute dz as a minus y,and it already done the calculus for you,and then the final step in back propagation is to go back to compute how much you need to change w and b,so in particular you can show that the derivative respect to w1w1 is equal to dz.
如果你对微积分熟悉,放心地去计算,整个求导过程,如果不熟悉微积分,你只需要知道,dzdz等于dz。
so if you want to do gradient descents,with respect to just this one example,what you will do is the following,you would use this formula to compute dz,and then use these formulas to compute dw1dw1 regression with respect to a single training example.
因此关于单个样本的梯度下降法,你所需要做的就是这些事情,使用这个公式计算dzdz回归的梯度下降法。
but to train logisticlogistic regression model you have not just one training example,given entire training set of m training examples,so in the next video.let’s see how you can take these ideas and apply them,to learning not just from one example,but from an entire training set.
但是训练logisticlogistic回归模型,不仅仅只有一个训练样本,而是有 m 个训练样本的整个训练集,因此在下一节视频中,这些想法如何应用到,整个训练样本集中,而不仅仅只是单个样本上。
重点总结:
对单个样本而言,逻辑回归 Loss function 表达式:
反向传播过程:(红色部分)
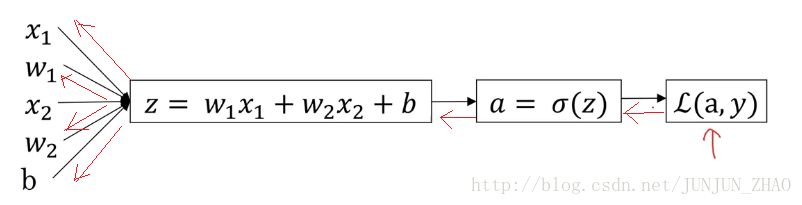
前面过程的 dada 求导:
再对w1、w2和bw1、w2和b进行求导:
梯度下降法:

该系列仅在原课程基础上部分知识点添加个人学习笔记,或相关推导补充等。如有错误,还请批评指教。在学习了 Andrew Ng 课程的基础上,为了更方便的查阅复习,将其整理成文字。因本人一直在学习英语,所以该系列以英文为主,同时也建议读者以英文为主,中文辅助,以便后期进阶时,为学习相关领域的学术论文做铺垫。- ZJ