原文下载 提取码:7mfx
目录
1. 比赛介绍
SemEval2019Task3_ERC是2019年Semantic Evaluation的第三个任务,对话情感识别。
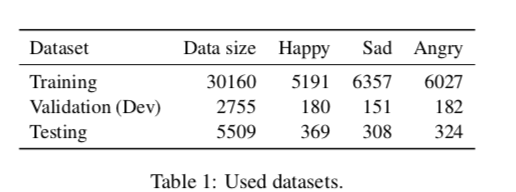
使用的数据集是EmoContext,该对话数据集为纯文本数据集,来自社交平台。分为训练集、验证集和测试集。其中训练集、验证集、测试集各包含30,160、2755和5509个对话,每个对话都包含三轮(2人对话数据集(Person1,Person2,Person1)),因此训练集、验证集、测试集各包含90,480、8265和16,527个子句(utterances)。
这个数据集存在严重的类别不均衡现象,和其他数据不均衡现象有所区别,它在训练集比较均衡,但在验证集和测试集中每一个情感类别数据大约占总体的<4%(符合实际情况,实际对话中大部分子句是不包含任何情感的),具体统计情况如下:
与一般的判断给定文本/句子情感的任务不同,该任务的的目标是,给定一个对话(3轮),判断最后一轮/最后一个子句说话者所表达的情感,建模时需要利用对话的上下文(context)来判断最后一个子句的情感。
数据集的每个对话中,只有最后一个子句有情感标签,该数据集的情感标签分为三类:Happiness、Sadness、Anger还有一个附加的标签(others)。其中有5740个对话标签为Happiness,6816个对话标签为Sadness,6533个对话标签为Anger,剩余对话标签全为others。
比赛采用的评估指标为:micro F1-score(只在三个情感类别Happiness、Sadness、Anger上计算micro F1-score,不包括others。本文所采用模型的最好结果是 0.7089)
数据集样例如下图所示:

虽然这只是一个包含3轮对话且只有最后一轮对话有情感标签的数据集,但是可以把基于该数据集训练的模型,应用到更广泛的场景,如判断一个对话中任意一个子句的情感。假设该对话包含N个子句/N轮,若要判断第i个子句的情感,只需要把第i个子句连同第i-1,i-2个子句一同喂给训练好的模型,就可以判断第i个子句的情感了。其中i=1,...,N ,对话中每一个子句的情感就可以确定了(对 对话中前两个子句判断情感时,可以通过填充实现)。
2. 模型描述

- 输入
把对话的三个子句拼接在一起,整体作为输入。对整个对话进行预处理(分词等),然后通过embedding层,转换为词向量。embedding的词嵌入矩阵使用GoEmb和GTEmb拼接进行初始化(300+300=600维,funetuing)。
其中GoEmb为Google word embedding,使用100billion的谷歌新闻数据进行预训练word2vec词向量,300维;GTEmb在1.1million的推特数据上进行预训练词向量,300维。
实际上,原文中使用了多种预训练词向量,并考虑他们之间的组合拼接,最后GoEmb和GTEmb拼接效果最好;而且还在词向量基础上附加一些统计特征,如大写字符和特殊字符等所占的比例,实验证明这些附加的统计特征没什么用,如下图所示:

- encoder
输入对话统一长度为50,输入tensor维度为(batch,50,600),先通过一个1维卷积层(大小3,200个,把输入看作是多通道的一维卷积,嵌入维600为通道),得到tensor(batch,48,200);在通过一个1维最大池化层(大小4,步长4),得到tensor(batch,12,200);再通过一个双向的LSTM(200单元),得到tensor(batch,12,400);然后再通过一个1维的全局最大池化,得到tensor(batch,400),再通过两个Dense 层,接softmax层做分类即可。
- 预测
本文通过训练多个不同的模型,采用多数投票策略,对一个样本,哪个类别获得的票数最多,则把它划分为该类别。
