开源实现(PyTorch) (基于Github上,TextGCN的PyTorch实现版本,额外添加了一些详细的注释;官方实现基于TF)
本篇博客是对论文《Graph Convolutional Networks for Text Classification》的阅读笔记。
目录
1. 简介
文本分类是自然语言处理中一个常见的基础问题。我们常用的文本表示方法有CNN,RNN/LSTM等等。这些模型会优先考虑文本的顺序信息和局部信息,能够很好的捕获连续词序列中的语义和语法信息,但是它忽略了全局(这个数据集/语料库)的词共现,全局词共现中携带了不连续以及长距离的语义信息。
这篇文章提出了一个新颖的基于图神经网络的方法来做文本分类,使用整个数据集/语料库来构建一个大的异构图(图中包含两类节点,一类是文档节点(待分类文本),另一类是单词节点(数据集/语料库中的所有单词(去重))),并且使用图卷积网络联合学习单词和文档的嵌入。
实验阶段,本文提出的模型在几个bench mark数据集上取得了state-of-the-art的结果,并且没有使用任何预训练词嵌入和外部知识。对于标注数据量较少的情形,相比与其他一些深度学习模型(基于CNN、LSTM等),TextGCN具有较强鲁棒性,当标注数据大量较少时,其性能仍然突出,下降不大。(具体实验配置和细节可以查看原文和开源实现)
该方法还可以自动学习具有预测性的词嵌入和文档嵌入,训练好TextGCN模型后,取其隐层或输出层的输出,即对每个节点(文档和单词)学习的特征表示向量,进行降维并可视化,会发现同类的文档和词会聚集在一起。(具体实验配置和细节可以查看原文和开源实现)
2. 方法
- 图卷积网络(GCN)
本文使用的图卷积公式如下所示:
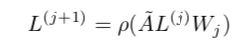
其中:
1)图,V是节点集合,节点数量为 n = |V|,E是边集。
2)A是图的邻接矩阵(n*n),如果定点有边相连,那么
(无权图);
所连边上的权重(有权图)。
3)需要引入自连接,可以看作每一个顶点都与自身相连,这样在图卷积操作更新自身节点的特征时,可以用到之前自身的特征。此时,A = A+I。
4)计算图的度矩阵D, 即度矩阵的对角线元素值为邻接矩阵对应行的和。
5)计算归一化/正则化的邻接矩阵: .可以消除邻居比较多的节点影响会比较大的问题。
6),X中的每一行是每个节点的初始特征向量,m为特征向量维度。
7)代表激活函数,
为第j个图卷积层的权重矩阵。
更多图神经网络的知识可以查看我的图神经网络专栏。
- TextGCN
本文基于整个数据集/语料库来构建一个异构图,将数据集中的待分类文档和数据集中的单词(去重)作为节点,如下图所示:

图中节点的数量是数据集/语料库中的单词数量+文档数量,O开头的是文档节点,其他的是词节点。图中黑线的线代表文档-词之间的边,灰色的表示词-词之间的边。R(x)表示x的embedding表示(包括文档和单词的embedding表示)。节点的不同颜色代表文档的不同类型/类别。
TextGCN输入的初始图特征矩阵X是n*n维的,其中n为图中的节点数 = 单词数量+文档数量,每个节点(文档和单词)初始都用one-hot形式编码,所以X是一个单位矩阵。
当某个单词出现在某个文档中时,二者之间会有一条边相连,边上的权重为单词的TF-IDF值,TF=该词在该文档中的出现次数,IDF为总的文档数比上包含该词的文档数再取log。
词-词之间的边基于全局词共现信息。全局词共现信息使用一个固定大小的滑动窗口在整个数据集/语料库中滑动(每次右移一个词的位置)统计词共现信息,然后使用点互信息(PMI)计算两个词节点连线的权重。具体如下:

其中,#W表示滑动窗口的总数量,#W(i)表示包含单词i的滑动窗口数量,#W(i,j)表示同时包含单词i和单词j(可以不相邻)的滑动窗口的数量。统计完后,带入上式计算PMI,PMI为正表示词与词之间的语义相关性较高,为负表示两个词之间的语义联系较小或者不存在,所以我们只给PMI为正的两个词节点连边,边上的权重为两个词的PMI值。
该异构图的邻接矩阵定义如下(i=j的情况,对应自连接):
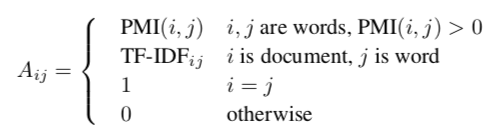
本文使用一个简单的二层图卷积网络,结构如下:
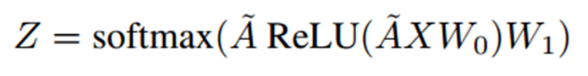
第一层使用ReLU作为激活函数,第二层使用softmax函数作分类。损失函数为交叉熵:
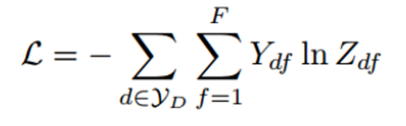
TextGCN训练和一般的图神经网络训练类似,采用full-batch的训练方式,即一个epoch更新一次参数。把整个数据集/图(包含文档节点和单词节点)进行前向传播(X n*n),通过mask取出划分的训练集对应部分的输出,和训练集对应的标签计算loss和梯度,对模型参数进行更新;验证或测试时,也是把整个数据集进行前向传播,通过mask取出划分的验证集或测试集对应部分的输出,和真实标签计算相应的指标。
训练结束后,会得到每个文档节点和单词节点的嵌入表示。对于最后一层产生的文档节点的嵌入表示(num_classes维,表示该文档在每一个类别上的置信度),按行取argmax得到预测的标签。
3. 结论分析
Text GCN可以捕获文档和词的关系以及全局词共现信息,文档节点的标签信息可以通过他们的邻居节点传递,传递给其他的单词和文档。在情感分类任务上(MR语料)上Text GCN没有表现出优于其他基准模型的结果,主要是因为GCN忽略了词序信息且MR预料中的数据都非常短,这在情感分类当中时非常有用的。
实验还证明了参数的敏感性。在Text GCN中,窗口大小和第一层GCN输出的向量维度大小(隐层维度)的选择都对结果有影响,较小的窗口不能得到有效地全局词共现信息,太大的窗口会使得本来关系并不密切的两个节点(单词)之间产生连边。
在本文的实验中,Text GCN可以有很好的文本分类结果,但是不能快速生成embedding,也不能为新的文本作分类(当出现新文本时,需要在图中添加新的文档节点和单词节点,并更新边的权重和图结构,然后再基于新的异构图,重新训练上述过程,才能为新文本分类,为新节点生成embedding)。
在未来的工作中可以引入归纳机制,注意力机制,发展无监督的text GCN框架。
