最近散事特别多,讨厌这种每天忙碌又迷茫的生活,一直想把这篇博客写了,前几天因为一直再弄一篇OpenCv的论文,还好能发了,今天刚抽出空就写写吧。
1、栏目dom分析
前几天有个医科学校做视频通话的项目,需要引入一些牙科相关的内容,如果手动去更新根本不可能,所以想引入一些网站上的内容,就查到了https://www.iyachi.com/这个网站,栏目在上面已经列出来,如牙周炎、牙龈肿痛等,经分析每个栏目的DOM结构都一样,以牙周炎分析为例,如下图:

文章列表全在一个类名为“category table table-striped table-bordered table-hover table-noheader”的table标签中,table下是tr标签,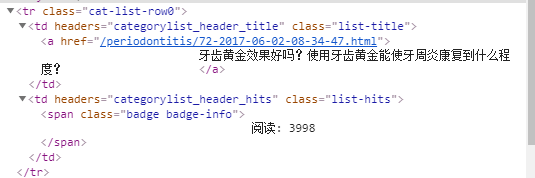
tr标签下的td标签含有文章url和文章标题,同时含有阅读量信息。
页码结构如下,

页码信息在css类名为pagination的div中,ul标签下的li标签含有页码信息和页码的url地址,第1页是“/periodontitis.html?start=0*10”,第二页是“/periodontitis.html?start=1*10”,依次类推。第一个li是“开始”页,第二个li是“上一页”,最后一个li是“最后一页”,所以需要取页码列表的[2:-2].
2、栏目列表初始化
下面列出python代码结构

def __init__(self):
self.url={
"健康误区":"https://www.iyachi.com/jiankangwuqu.html",
"牙周炎":"https://www.iyachi.com/periodontitis.html",
"牙龈肿痛":"https://www.iyachi.com/swollengums.html",
"牙龈萎缩":"https://www.iyachi.com/gingivalrecession.html",
"牙龈出血":"https://www.iyachi.com/bleedinggums.html",
"牙齿松动":"https://www.iyachi.com/looseteeth.html",
"蛀牙":"https://www.iyachi.com/toothdecay.html",
"牙齿黄金":"https://www.iyachi.com/teethgold.html",
"好文共享":"https://www.iyachi.com/expertmonograph.html",
"爱牙活动":"https://www.iyachi.com/activity.html",
"爱牙推荐":"https://www.iyachi.com/",
"爱牙问答":"https://www.iyachi.com/wenda.html",
"爱牙新闻":"https://www.iyachi.com/news.html"
}
self.article_url_list=[]#文章列表
self.headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}以上是内容的初始化,不必多解释。
3、获取文章列表
for name,url in self.url.items():
print('检测名字为"%s"的栏目'%(name))
res_html=rq.get(url=url,headers=self.headers).content.decode("utf-8")
res_data=etree.HTML(res_html)
page_url_list=res_data.xpath('//div[@class="pagination"]//ul/li')[2:-2]#页码列表
page_len=len(page_url_list)
for i in range(page_len+1):
page_url=url+"?start=%d"%(i*10)#某栏目的第i+1页
self.getArticleList(page_url,name)#获取第i+1页的栏目名字为name文章列表上面代码首先遍历栏目列表,然后根据栏目的url获取到每一个栏目的文章的列表,最后遍历文章列表,调用获得文章详情的方法来获取文章详情。
4、文章详情DOM分析
如下图,

文章内容在一个css类名为article-content clearfix的section标签里,可以通过xpath的string获取到,文章标题获取有两种方法:一是在文章列表中获得,即前面提到的tr标签里;二是在文章详情里,如下图,

标题在类名为article-title的h1标签里,本文说的代码里是通过文章列表里获取的。获取文章详情代码如下:
def getArticleContent(self,url):
article_html=rq.get(url=url,headers=self.headers).content.decode("utf-8")
article_every=etree.HTML(article_html)
article_every_data=article_every.xpath('string(//section[@class="article-content clearfix"])').strip()
return article_every_data5、存至数据库
这部分不多讲解,直接上代码:
def insertData(self,articleName,articleContent,articleTitle,url):
#print("检测名字为%s的栏目"%(articleName))
#print("栏目地址%s"%(url))
selectSql="select * from ARTICLE where article_url='%s'"%(url)
#print(selectSql)
db=pymysql.connect("192.168.1.8","root","test","IYACHI")
cursor=db.cursor()
cursor.execute(selectSql)
if(cursor.rowcount!=0):
print('文章名字为"%s"的文章已经存在,无需更新'%(articleTitle))
else:
print("即将存储……")
insertSql="insert into ARTICLE(article_name,article_title,article_url,article_content) values ('%s','%s','%s','%s')"%(articleName,articleTitle,url,articleContent)
#print(insertSql)
cursor.execute(insertSql)
db.commit()
print ("【新文章提醒】这是一则新的文章,名称为《%s》,已为您更新到数据库" % (articleName))6、总结
这个咨询详情的获取并不难,大约一上午就能搞定,这次就当是练练手了。想要做到页面上去,还需要用后端语言做数据接口,本文不在说明。最终结果如下:

完整代码如下:
#_*_conding:utf-8_*_
"""
作者:liqq
作用:爬取http://iyachi.com的内容并存库
环境:python3.7
"""
import requests as rq
from lxml import etree
from bs4 import BeautifulSoup
import pymysql
class Iyachi(object):
def __init__(self):
self.url={
"健康误区":"https://www.iyachi.com/jiankangwuqu.html",
"牙周炎":"https://www.iyachi.com/periodontitis.html",
"牙龈肿痛":"https://www.iyachi.com/swollengums.html",
"牙龈萎缩":"https://www.iyachi.com/gingivalrecession.html",
"牙龈出血":"https://www.iyachi.com/bleedinggums.html",
"牙齿松动":"https://www.iyachi.com/looseteeth.html",
"蛀牙":"https://www.iyachi.com/toothdecay.html",
"牙齿黄金":"https://www.iyachi.com/teethgold.html",
"好文共享":"https://www.iyachi.com/expertmonograph.html",
"爱牙活动":"https://www.iyachi.com/activity.html",
"爱牙推荐":"https://www.iyachi.com/",
"爱牙问答":"https://www.iyachi.com/wenda.html",
"爱牙新闻":"https://www.iyachi.com/news.html"
}
self.article_url_list=[]
self.headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
def main(self):
for name,url in self.url.items():
print('检测名字为"%s"的栏目'%(name))
res_html=rq.get(url=url,headers=self.headers).content.decode("utf-8")
res_data=etree.HTML(res_html)
page_url_list=res_data.xpath('//div[@class="pagination"]//ul/li')[2:-2]#页码列表
page_len=len(page_url_list)
for i in range(page_len+1):
page_url=url+"?start=%d"%(i*10)#某栏目的第i+1页
self.getArticleList(page_url,name)#获取第i+1页的栏目名字为name文章列表
def getArticleList(self,url,name):
data={}
article_tr=rq.get(url=url,headers=self.headers).content.decode('utf-8')
article_tr_html=etree.HTML(article_tr)
article_tr_list=article_tr_html.xpath("//table[@class='category table table-striped table-bordered table-hover table-noheader']//tr")
for article_tr in article_tr_list:
if article_tr.xpath("./td[1]/a/@href"):
article_title=article_tr.xpath("./td[1]/a/text()")[0].strip()
#print(article_title)
article_url="http://iyachi.com"+article_tr.xpath("./td[1]/a/@href")[0]
#self.article_url_list.append(article_url)#这里是文章列表
article_content=self.getArticleContent(article_url)
data["article_name"]=name
data["article_title"]=article_tr.xpath("./td[1]/a/text()")[0].strip()
data["content"]=article_content.strip()
data["article_url"]=article_url
#print(data)
self.insertData(data["article_name"],data["content"],data["article_title"],data["article_url"])
def getArticleContent(self,url):
article_html=rq.get(url=url,headers=self.headers).content.decode("utf-8")
article_every=etree.HTML(article_html)
article_every_data=article_every.xpath('string(//section[@class="article-content clearfix"])').strip()
return article_every_data
def insertData(self,articleName,articleContent,articleTitle,url):
#print("检测名字为%s的栏目"%(articleName))
#print("栏目地址%s"%(url))
selectSql="select * from ARTICLE where article_url='%s'"%(url)
#print(selectSql)
db=pymysql.connect("192.168.1.8","root","test","IYACHI")
cursor=db.cursor()
cursor.execute(selectSql)
if(cursor.rowcount!=0):
print('文章名字为"%s"的文章已经存在,无需更新'%(articleTitle))
else:
print("即将存储……")
insertSql="insert into ARTICLE(article_name,article_title,article_url,article_content) values ('%s','%s','%s','%s')"%(articleName,articleTitle,url,articleContent)
#print(insertSql)
cursor.execute(insertSql)
db.commit()
print ("【新文章提醒】这是一则新的文章,名称为《%s》,已为您更新到数据库" % (articleName))
#print(cursor.fetchone())
#print(cursor.rowcount)
def cursor(self):
db=pymysql.connect("192.168.1.8","root","test","IYACHI")
cursor=db.cursor()
return cursor
#if __name__=="__main__":
iyachi=Iyachi()
iyachi.main()
有问题请联系:邮箱:[email protected]
