TensorFlow Hub 模型复用
TF Hub 网站
打开主页 https://tfhub.dev/ ,在左侧有 Text、Image、Video 和 Publishers 等选项,可以选取关注的类别,然后在顶部的搜索框输入关键字可以搜索模型。
TF Hub 安装
是单独的一个库,需要单独安装,安装命令如下:
pip install tensorflow-hub
TF Hub 模型使用样例


import tensorflow_hub as hub hub_handle = 'https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2' hub_model = hub.load(hub_handle) outputs = hub_model(inputs)
hub.load(url) 就是把 TF Hub 的模型从网络下载和加载进来, hub_module 就是运行模型, outputs 即为输出
以 stylization 为例该模型的地址如下:
https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2
其中,末尾的 2 为该模型的版本号
目前还有很多模型是基于 TF1.0 的,选择的过程中请注意甄别,有些模型会明确写出来是试用哪个版本,或者,检查使用是否是 tfhub 0.5.0 或以上版本的 API hub.load(url) ,在之前版本使用的是 hub.Module(url)
tfhub.dev,请大家转换域名到国内镜像 https://hub.tensorflow.google.cn/ ,模型下载地址也需要相应转换。
import matplotlib.pyplot as plt import numpy as np import tensorflow as tf import tensorflow_hub as hub def crop_center(image): """Returns a cropped square image.""" shape = image.shape new_shape = min(shape[1], shape[2]) offset_y = max(shape[1] - shape[2], 0) // 2 offset_x = max(shape[2] - shape[1], 0) // 2 image = tf.image.crop_to_bounding_box(image, offset_y, offset_x, new_shape, new_shape) return image def load_image_local(image_path, image_size=(512, 512), preserve_aspect_ratio=True): """Loads and preprocesses images.""" # Load and convert to float32 numpy array, add batch dimension, and normalize to range [0, 1]. img = plt.imread(image_path).astype(np.float32)[np.newaxis, ...] if img.max() > 1.0: img = img / 255. if len(img.shape) == 3: img = tf.stack([img, img, img], axis=-1) img = crop_center(img) img = tf.image.resize(img, image_size, preserve_aspect_ratio=True) return img def show_image(image, title, save=False): plt.imshow(image, aspect='equal') plt.axis('off') if save: plt.savefig(title + '.png', bbox_inches='tight', dpi=fig.dpi,pad_inches=0.0) else: plt.show() content_image_path = "images/contentimg.jpeg" style_image_path = "images/styleimg.jpeg" content_image = load_image_local(content_image_path) style_image = load_image_local(style_image_path) show_image(content_image[0], "Content Image") show_image(style_image[0], "Style Image") # Load image stylization module. hub_module = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2'); # Stylize image. outputs = hub_module(tf.constant(content_image), tf.constant(style_image)) stylized_image = outputs[0] show_image(stylized_image[0], "Stylized Image", True)
大家可以在如下路径获取 notebook 和代码体验:
https://github.com/snowkylin/tensorflow-handbook/tree/master/source/_static/code/zh/tfhub
也可在谷歌提供的如下 notebook 体验:
TF Hub 模型retrain样例
需要进行二次训练。针对这种情况,TF Hub 提供了很方便的 Keras 接口 hub.KerasLayer(url) ,其可以封装在 Keras 的 Sequential 层状结构中,进而可以针对开发者的需求和数据进行再训练
import tensorflow as tf import tensorflow_hub as hub num_classes = 10 # 使用 hub.KerasLayer 组件待训练模型 new_model = tf.keras.Sequential([ hub.KerasLayer("https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4", output_shape=[2048], trainable=False), tf.keras.layers.Dense(num_classes, activation='softmax') ]) new_model.build([None, 299, 299, 3]) # 输出模型结构 new_model.summary()
剩下的训练和模型保存跟正常的 Keras 的 Sequential 模型完全一样。
可在谷歌提供的如下 notebook 体验:
TensorFlow Datasets 数据集载入
开箱即用的数据集集合,包含数十种常用的机器学习数据集。
可以通过以下安装:
pip install tensorflow-datasets
import tensorflow as tf import tensorflow_datasets as tfds
dataset = tfds.load("mnist", split=tfds.Split.TRAIN) dataset = tfds.load("cats_vs_dogs", split=tfds.Split.TRAIN, as_supervised=True) dataset = tfds.load("tf_flowers", split=tfds.Split.TRAIN, as_supervised=True)
export TFDS_HTTPS_PROXY=http://代理服务器IP:端口
tfds.load 方法返回一个 tf.data.Dataset 对象。部分重要的参数如下:
-
as_supervised:若为 True,则根据数据集的特性,将数据集中的每行元素整理为有监督的二元组(input, label)(即 “数据 + 标签”)形式,否则数据集中的每行元素为包含所有特征的字典。 -
split:指定返回数据集的特定部分。若不指定,则返回整个数据集。一般有tfds.Split.TRAIN(训练集)和tfds.Split.TEST(测试集)选项。
# 使用 TessorFlow Datasets 载入“tf_flowers”数据集 dataset = tfds.load("tf_flowers", split=tfds.Split.TRAIN, as_supervised=True) # 对 dataset 进行大小调整、打散和分批次操作 dataset = dataset.map(lambda img, label: (tf.image.resize(img, [224, 224]) / 255.0, label)) \ .shuffle(1024) \ .batch(32) # 迭代数据 for images, labels in dataset: # 对images和labels进行操作
Swift for TensorFlow
S4TF 简介
专门针对 TensorFlow 优化过的 Swift 版本。
S4TF 环境配置
本地安装 Swift for TensorFlow
目前 S4TF 支持 Mac 和 Linux 两个运行环境。安装需要下载预先编译好的软件包,同时按照对应的操作系统的说明进行操作。安装后,即可以使用全套 Swift 工具,包括 Swift(Swift REPL / Interpreter)和 Swiftc(Swift 编译器)。官方文档(含下载地址)可见 这里 。
在 Colaboratory 中快速体验 Swift for TensorFlow
Google 的 Colaboratory 可以直接支持 Swift 语言的运行环境。可以 点此 直接打开一个空白的,具备 Swift 运行环境的 Colab Notebook ,这是立即体验 Swift for TensorFlow 的最方便的办法。
在 Docker 中快速体验 Swift for TensorFlow
在本机已有 docker 环境的情况下,使用预装 Swift for TensorFlow 的 Docker Image 是非常方便的。
-
获得一个 S4TS 的 Jupyter Notebook
在命令行中执行
nvidia-docker run -ti --rm -p 8888:8888 --cap-add SYS_PTRACE -v "$(pwd)":/notebooks zixia/swift来启动 Jupyter ,然后根据提示的 URL ,打开浏览器访问即可。 -
获得一个已经安装好 S4TF 的 Swift REPL 环境
在命令行中执行
docker run -it --privileged --userns=host zixia/swift swift
S4TF 基础使用
import TensorFlow // 声明两个Tensor let x = Tensor<Float>([1]) let y = Tensor<Float>([2]) // 对两个 Tensor 做加法运算 let w = x + y // 输出结果 print(w)
在 Swift 中使用标准的 TensorFlow API
let x = Tensor<BFloat16>(zeros: [32, 128]) let h1 = sigmoid(matmul(x, w1) + b1) let h2 = tanh(matmul(h1, w1) + b1) let h3 = softmax(matmul(h2, w1) + b1)
let imageBatch = Dataset(elements: images) let labelBatch = Dataset(elements: labels) let zipped = zip(imageBatch, labelBatch).batched(8) let imageBatch = Dataset(elements: images) let labelBatch = Dataset(elements: labels) for (image, label) in zip(imageBatch, labelBatch) { let y = matmul(image, w) + b let loss = (y - label).squared().mean() print(loss) }
matmul() 的别名: •
matmul(a, b) 可以简写为 a • b。• 符号在 Mac 上,可以通过键盘按键 Option + 8 输入。
在 Swift 中直接加载 Python 语言库
import Python let np = Python.import("numpy") let x = np.array([[1, 2], [3, 4]]) let y = np.array([11, 12]) print(x.dot(y))
import Glibc let x = malloc(18) memcpy(x, "memcpy from Glibc", 18) free(x)
语言原生支持自动微分
@differentiable func frac(x: Double) -> Double { return 1/x } gradient(of: frac)(0.5)
frac() 标记为 @differentiable ,然后就可以通过 gradient() 函数,将其转换为求解微分的新函数 gradient(of: frac),接下来就可以根据任意 x 值求解函数 frac 所在 x 点的梯度了
Swift 使用 func 声明一个函数。在函数的参数中,变量名的冒号后面代表的是 “参数类型”;在函数参数和函数体({}) 之前,还可以通过瘦箭头(->)来指定函数的 ``返回值类型``。
比如在上面的代码中,参数变量名为 “x”;参数类型为 “Double”;函数返回类型为 “Double”。
以最简单的 MNIST 数字分类为例子,给大家介绍一下基础的 S4TF 编程代码实现
import TensorFlow import Python import Foundation import MNIST
struct MLP: Layer { // 定义模型的输入、输出数据类型 typealias Input = Tensor<Float> typealias Output = Tensor<Float> // 定义 flatten 层,将二维矩阵展开为一个一维数组 var flatten = Flatten<Float>() // 定义全连接层,输入为 784 个神经元,输出为 10 个神经元 var dense = Dense<Float>(inputSize: 784, outputSize: 10) @differentiable public func callAsFunction(_ input: Input) -> Output { // 模型运行时,将 input 顺序传递给:flatten 和 dense 层,将结果返回作为模型输出。 return input.sequenced(through: flatten, dense) } }
为了定义一个 Swift 神经网络模型,我们需要建立一个遵循 Layer 协议,来声明一个定义神经网络结构的 Struct。
其中,最为核心的部分是声明 callAsFunction(_:) 方法,来定义输入和输出 Tensor 的映射关系。
callAsFunction(_:) 中可以通过类似 Keras 的 Sequential 的方法进行定义:input.sequences(through: layer1, layer2, ...) 将输入和所有的后续处理层 layer1, layer2, … 等衔接起来。
在代码中,我们会看到形如 callAsFunction(_ input: Input) 这样的函数声明。其中,_ 代表忽略参数标签。
Swift 中,每个函数参数都有一个 参数标签 (Argument Label) 以及一个 参数名称(Parameter Name)。 参数标签 主要应用在调用函数的情况,使得函数的实参与真实命名相关联,更加容易理解实参的意义。同时因为有 参数标签 的存在,实在的顺序是可以随意改变的。
如果你不希望为参数添加标签,可以使用一个下划线 (_) 来代替一个明确的 参数标签。
var model = MLP() let optimizer = Adam(for: model) let mnist = MNIST() let ((trainImages, trainLabels), (testImages, testLabels)) = mnist.loadData() let imageBatch = Dataset(elements: trainImages).batched(32) let labelBatch = Dataset(elements: trainLabels).batched(32)
for (X, y) in zip(imageBatch, labelBatch) { // Caculate the gradient let grads = gradient(at: model) { model -> Tensor<Float> in let logits = model(X) return softmaxCrossEntropy(logits: logits, labels: y) } // Update parameters by optimizer optimizer.update(&model.self, along: grads) }
Swift 的闭包函数声明为:{ (parameters) -> return type in statements },其中:parameters 为闭包接受的参数,return type 为闭包运行完毕的返回值类型,statements 为闭包内的运行代码。
比如上述代码中的 { model -> Tensor<Float> in 这一段,就声明了一个传入参数为 model,返回类型为 Tensor<Float> 的闭包函数。
如果函数需要一个闭包作为参数,且这个参数是最后一个参数,那么我们可以将闭包函数放在函数参数列表外(也就是括号外),这种格式称为尾随闭包。
在 Swift 语言中,函数缺省是不可以修改参数的值的。为了让函数能够修改传入的参数变量,需要将传入的参数作为输入输出参数(In-Out Parmeters)。具体表现为需要在参数前加 & 符号,表示这个值可以被函数修改。
let logits = model(testImages) let acc = mnist.getAccuracy(y: testLabels, logits: logits) print("Test Accuracy: \(acc)" )
TensorFlow in Julia
TensorFlow.jl 简介
使用 Julia ,写的快,跑的更快。
TensorFlow.jl 环境配置
在 docker 中快速体验 TensorFlow.jl
在本机已有 docker 环境的情况下,使用预装 TensorFlow.jl 的 docker image 是非常方便的。
在命令行中执行 docker run -it malmaud/julia:tf ,然后就可以获得一个已经安装好 TensorFlow.jl 的 Julia REPL 环境。 (如果你不想直接打开 Julia,请在执行 docker run -it malmaud/julia:tf /bin/bash 来打开一个 bash 终端。如需执行您需要的 jl 代码文件,可以使用 docker 的目录映射)
在 julia 包管理器中安装 TensorFlow.jl
在命令行中执行 julia 进入 Julia REPL 环境,然后执行以下命令安装 TensorFlow.jl
using pkg
Pkg.add("TensorFlow")
TensorFlow.jl 基础使用
using TensorFlow
# 定义一个 Session
sess = TensorFlow.Session() # 定义一个常量和变量 x = TensorFlow.constant([1]) y = TensorFlow.Variable([2]) # 定义一个计算 w = x + y # 执行计算过程 run(sess, TensorFlow.global_variables_initializer()) res = run(sess, w) # 输出结果 println(res)
MNIST 数字分类
# 使用自带例子中的 mnist_loader.jl 加载数据 include(Pkg.dir("TensorFlow", "examples", "mnist_loader.jl")) loader = DataLoader() # 定义一个 Session using TensorFlow sess = Session() # 构建 softmax 回归模型 x = placeholder(Float32) y_ = placeholder(Float32) W = Variable(zeros(Float32, 784, 10)) b = Variable(zeros(Float32, 10)) run(sess, global_variables_initializer()) # 预测类和损失函数 y = nn.softmax(x*W + b) cross_entropy = reduce_mean(-reduce_sum(y_ .* log(y), axis=[2])) # 开始训练模型 train_step = train.minimize(train.GradientDescentOptimizer(.00001), cross_entropy) for i in 1:1000 batch = next_batch(loader, 100) run(sess, train_step, Dict(x=>batch[1], y_=>batch[2])) end # 查看结果并评估模型 correct_prediction = indmax(y, 2) .== indmax(y_, 2) accuracy=reduce_mean(cast(correct_prediction, Float32)) testx, testy = load_test_set() println(run(sess, accuracy, Dict(x=>testx, y_=>testy)))
图执行模式下的 TensorFlow
TensorFlow 1+1
TensorFlow 的图执行模式是一个符号式的(基于计算图的)计算框架。简而言之,如果你需要进行一系列计算,则需要依次进行如下两步:
-
建立一个“计算图”,这个图描述了如何将输入数据通过一系列计算而得到输出;
-
建立一个会话,并在会话中与计算图进行交互,即向计算图传入计算所需的数据,并从计算图中获取结果。
使用计算图与会话进行基本运算
import tensorflow.compat.v1 as tf tf.disable_eager_execution() # 以下三行定义了一个简单的“计算图” a = tf.constant(1) # 定义一个常量张量(Tensor) b = tf.constant(1) c = a + b # 等价于 c = tf.add(a, b),c是张量a和张量b通过 tf.add 这一操作(Operation)所形成的新张量 sess = tf.Session() # 实例化一个会话(Session) c_ = sess.run(c) # 通过会话的 run() 方法对计算图里的节点(张量)进行实际的计算 print(c_)
import tensorflow as tf @tf.function def graph(): a = tf.constant(1) # 定义一个常量张量(Tensor) b = tf.constant(1) c = a + b return c c_ = graph() print(c_.numpy())
占位符(Placeholder)与 feed_dict
import tensorflow.compat.v1 as tf tf.disable_eager_execution() a = tf.placeholder(dtype=tf.int32) # 定义一个占位符Tensor b = tf.placeholder(dtype=tf.int32) c = a + b a_ = int(input("a = ")) # 从终端读入一个整数并放入变量a_ b_ = int(input("b = ")) sess = tf.Session() c_ = sess.run(c, feed_dict={a: a_, b: b_}) # feed_dict参数传入为了计算c所需要的张量的值 print("a + b = %d" % c_)
import tensorflow as tf @tf.function def graph(a, b): c = a + b return c a_ = int(input("a = ")) b_ = int(input("b = ")) c_ = graph(a_, b_) print("a + b = %d" % c_)
我们可以看出:
-
tf.placeholder()相当于tf.function的函数参数; -
sess.run()的feed_dict参数相当于给被@tf.function修饰的函数传值。
变量(Variable)
import tensorflow.compat.v1 as tf tf.disable_eager_execution() a = tf.get_variable(name='a', shape=[]) initializer = tf.assign(a, 0.0) # tf.assign(x, y)返回一个“将张量y的值赋给变量x”的操作 plus_one_op = tf.assign(a, a + 1.0) sess = tf.Session() sess.run(initializer) for i in range(5): sess.run(plus_one_op) # 对变量a执行加一操作 print(sess.run(a)) # 输出此时变量a在当前会话的计算图中的值
import tensorflow.compat.v1 as tf tf.disable_eager_execution() a = tf.get_variable(name='a', shape=[], initializer=tf.zeros_initializer) # 指定初始化器为全0初始化 plus_one_op = tf.assign(a, a + 1.0) sess = tf.Session() sess.run(tf.global_variables_initializer()) # 初始化所有变量 for i in range(5): sess.run(plus_one_op) print(sess.run(a))
import tensorflow as tf a = tf.Variable(0.0) @tf.function def plus_one_op(): a.assign(a + 1.0) return a for i in range(5): plus_one_op() print(a.numpy())
矩阵及张量计算
import tensorflow.compat.v1 as tf tf.disable_eager_execution() A = tf.ones(shape=[2, 3]) # tf.ones(shape)定义了一个形状为shape的全1矩阵 B = tf.ones(shape=[3, 2]) C = tf.matmul(A, B) sess = tf.Session() C_ = sess.run(C) print(C_)
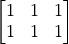 和
和 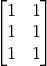
占位符和变量也同样可以为向量、矩阵乃至更高维的张量
基础示例:线性回归
ensorFlow 的图执行模式使用 符号式编程 来进行数值运算。
首先,我们需要将待计算的过程抽象为计算图,将输入、运算和输出都用符号化的节点来表达。
然后,我们将数据不断地送入输入节点,让数据沿着计算图进行计算和流动,最终到达我们需要的特定输出节点。
import tensorflow as tf # 定义数据流图 learning_rate_ = tf.placeholder(dtype=tf.float32) X_ = tf.placeholder(dtype=tf.float32, shape=[5]) y_ = tf.placeholder(dtype=tf.float32, shape=[5]) a = tf.get_variable('a', dtype=tf.float32, shape=[], initializer=tf.zeros_initializer) b = tf.get_variable('b', dtype=tf.float32, shape=[], initializer=tf.zeros_initializer) y_pred = a * X_ + b loss = tf.constant(0.5) * tf.reduce_sum(tf.square(y_pred - y_)) # 反向传播,手动计算变量(模型参数)的梯度 grad_a = tf.reduce_sum((y_pred - y_) * X_) grad_b = tf.reduce_sum(y_pred - y_) # 梯度下降法,手动更新参数 new_a = a - learning_rate_ * grad_a new_b = b - learning_rate_ * grad_b update_a = tf.assign(a, new_a) update_b = tf.assign(b, new_b) train_op = [update_a, update_b] # 数据流图定义到此结束 # 注意,直到目前,我们都没有进行任何实质的数据计算,仅仅是定义了一个数据图 num_epoch = 10000 learning_rate = 1e-3 with tf.Session() as sess: # 初始化变量a和b tf.global_variables_initializer().run() # 循环将数据送入上面建立的数据流图中进行计算和更新变量 for e in range(num_epoch): sess.run(train_op, feed_dict={X_: X, y_: y, learning_rate_: learning_rate}) print(sess.run([a, b]))
自动求导机制
在上面的两个示例中,我们都是手工计算获得损失函数关于各参数的偏导数。但当模型和损失函数都变得十分复杂时(尤其是深度学习模型),这种手动求导的工程量就难以接受了。因此,在图执行模式中,TensorFlow 同样提供了 自动求导机制 。类似于即时执行模式下的 tape.grad(ys, xs) ,可以利用 TensorFlow 的求导操作 tf.gradients(ys, xs) 求出损失函数 loss 关于 a , b 的偏导数。由此,我们可以将上节中的两行手工计算导数的代码
# 反向传播,手动计算变量(模型参数)的梯度
grad_a = tf.reduce_sum((y_pred - y_) * X_) grad_b = tf.reduce_sum(y_pred - y_)
替换为
grad_a, grad_b = tf.gradients(loss, [a, b])
计算结果将不会改变。
优化器
TensorFlow 在图执行模式下也附带有多种 优化器 (optimizer),可以将求导和梯度更新一并完成。我们可以将上节的代码
# 反向传播,手动计算变量(模型参数)的梯度
grad_a = tf.reduce_sum((y_pred - y_) * X_) grad_b = tf.reduce_sum(y_pred - y_) # 梯度下降法,手动更新参数 new_a = a - learning_rate_ * grad_a new_b = b - learning_rate_ * grad_b update_a = tf.assign(a, new_a) update_b = tf.assign(b, new_b) train_op = [update_a, update_b]
整体替换为
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate_) grad = optimizer.compute_gradients(loss) train_op = optimizer.apply_gradients(grad)
这里,我们先实例化了一个 TensorFlow 中的梯度下降优化器 tf.train.GradientDescentOptimizer() 并设置学习率。然后利用其 compute_gradients(loss) 方法求出 loss 对所有变量(参数)的梯度。最后通过 apply_gradients(grad) 方法,根据前面算出的梯度来梯度下降更新变量(参数)。
以上三行代码等价于下面一行代码:
train_op = tf.train.GradientDescentOptimizer(learning_rate=learning_rate_).minimize(loss)
最后的简化代码:
learning_rate_ = tf.placeholder(dtype=tf.float32) X_ = tf.placeholder(dtype=tf.float32, shape=[5]) y_ = tf.placeholder(dtype=tf.float32, shape=[5]) a = tf.get_variable('a', dtype=tf.float32, shape=[], initializer=tf.zeros_initializer) b = tf.get_variable('b', dtype=tf.float32, shape=[], initializer=tf.zeros_initializer) y_pred = a * X_ + b loss = tf.constant(0.5) * tf.reduce_sum(tf.square(y_pred - y_)) # 反向传播,利用TensorFlow的梯度下降优化器自动计算并更新变量(模型参数)的梯度 train_op = tf.train.GradientDescentOptimizer(learning_rate=learning_rate_).minimize(loss) num_epoch = 10000 learning_rate = 1e-3 with tf.Session() as sess: tf.global_variables_initializer().run() for e in range(num_epoch): sess.run(train_op, feed_dict={X_: X, y_: y, learning_rate_: learning_rate}) print(sess.run([a, b]))
使用 Docker 部署 TensorFlow 环境
Docker 是轻量级的容器(Container)环境,通过将程序放在虚拟的 “容器” 或者说 “保护层” 中运行,既避免了配置各种库、依赖和环境变量的麻烦,又克服了虚拟机资源占用多、启动慢的缺点。使用 Docker 部署 TensorFlow 的步骤如下:
wget -qO- https://get.docker.com/ | sh
如果当前的用户非 root 用户,可以执行 sudo usermod -aG docker your-user 命令将当前用户加入 docker 用户组。重新登录后即可直接运行 Docker。
Linux 下通过以下命令启动 Docker 服务:
sudo service docker start
-
拉取 TensorFlow 映像。Docker 将应用程序及其依赖打包在映像文件中,通过映像文件生成容器。使用
docker image pull命令拉取适合自己需求的 TensorFlow 映像,例如:
docker image pull tensorflow/tensorflow:latest-py3 # 最新稳定版本TensorFlow(Python 3.5,CPU版) docker image pull tensorflow/tensorflow:latest-gpu-py3 # 最新稳定版本TensorFlow(Python 3.5,GPU版)
更多映像版本可参考 TensorFlow 官方文档 。
小技巧
在国内,推荐使用 DaoCloud 的 Docker 映像镜像 ,将显著提高下载速度。
-
基于拉取的映像文件,创建并启动 TensorFlow 容器。使用
docker container run命令创建一个新的 TensorFlow 容器并启动。
CPU 版本的 TensorFlow:
docker container run -it tensorflow/tensorflow:latest-py3 bash
提示
docker container run 命令的部分选项如下:
-
-it让 docker 运行的容器能够在终端进行交互,具体而言:-
-i(--interactive):允许与容器内的标准输入 (STDIN) 进行交互。 -
-t(--tty):在新容器中指定一个伪终端。
-
-
--rm:当容器中的进程运行完毕后自动删除容器。 -
tensorflow/tensorflow:latest-py3:新容器基于的映像。如果本地不存在指定的映像,会自动从公有仓库下载。 -
bash在容器中运行的命令(进程)。Bash 是大多数 Linux 系统的默认 Shell。
GPU 版本的 TensorFlow:
若需在 TensorFlow Docker 容器中开启 GPU 支持,需要具有一块 NVIDIA 显卡并已正确安装驱动程序(详见 “TensorFlow 安装” 一章 )。同时需要安装 nvidia-docker 。依照官方文档中的 quickstart 部分逐行输入命令即可。
警告
当前 nvidia-docker 仅支持 Linux。
安装完毕后,在 docker container run 命令中添加 --runtime=nvidia 选项,并基于具有 GPU 支持的 TensorFlow Docker 映像启动容器即可,即:
docker container run -it --runtime=nvidia tensorflow/tensorflow:latest-gpu-py3 bash
Docker 常用命令
映像(image)相关操作:
docker image pull [image_name] # 从仓库中拉取映像[image_name]到本机 docker image ls # 列出所有本地映像 docker image rm [image_name] # 删除名为[image_name]的本地映像
容器(container)相关操作:
docker container run [image_name] [command] # 基于[image_name]映像建立并启动容器,并运行[command] docker container ls # 列出本机正在运行的容器 # (加入--all参数列出所有容器,包括已停止运行的容器) docker container rm [container_id] # 删除ID为[container_id]的容器
Docker 入门教程可参考 阮一峰的 Docker 入门教程 和 Docker Cheat Sheet 。
在云端使用TensorFlow
在Colab中使用TensorFlow
Google Colab 是谷歌的免费在线交互式 Python 运行环境,且提供 GPU 支持,使得机器学习开发者们无需在自己的电脑上安装环境,就能随时随地从云端访问和运行自己的机器学习代码。
进入 Colab(https://colab.research.google.com),新建一个 Python3 笔记本
如果需要使用 GPU,则点击菜单 “代码执行程序 - 更改运行时类型”,在 “硬件加速器” 一项中选择 “GPU”
我们在主界面输入一行代码,例如 import tensorflow as tf ,然后按 ctrl + enter 执行代码(如果直接按下 enter 是换行,可以一次输入多行代码并运行)。此时 Colab 会自动连接到云端的运行环境,并将状态显示在右上角。
运行完后,点击界面左上角的 “+ 代码”,此时界面上会新增一个输入框,我们输入 tf.__version__ ,再次按下 ctrl + enter 执行代码,以查看 Colab 默认的 TensorFlow 版本
在 Colab 中,可以使用 !pip install 或者 !apt-get install 来安装 Colab 中尚未安装的 Python 库或 Linux 软件包。比如在这里,我们希望使用 TensorFlow 2.0 beta1 版本,即点击左上角的 “+ 代码”,输入:
!pip install tensorflow-gpu==2.0.0-beta1
按下 ctrl + enter 执行
可以使用 tf.test.is_gpu_available 函数来查看当前环境的 GPU 是否可用
可以通过 !nvidia-smi 查看当前的 GPU 信息
在Google Cloud Platform(GCP)中使用TensorFlow
建立具有 GPU 的虚拟机实例,只需要进入 Compute Engine 的 VM 实例(https://console.cloud.google.com/compute/instances),并在创建实例的时候选择 GPU 类型和数量即可。
使用 AI Platform 中的 Notebook 建立带 GPU 的在线 JupyterLab 环境
如果你不希望繁杂的配置,希望迅速获得一个开箱即用的在线交互式 Python 环境,可以使用 GCP 的 AI Platform 中的 Notebook。其预安装了 JupyterLab,可以理解为 Colab 的付费升级版,具备更多功能且限制较少。
进入 https://console.cloud.google.com/mlengine/notebooks ,点击 “新建实例 -TensorFlow 2.0-With 1 NVIDIA Tesla K80”
在阿里云上使用 GPU 实例运行 Tensorflow
访问 https://cn.aliyun.com/product/ecs/gpu ,点击购买
根据需要选择合适的镜像
如果选择 “公共镜像”,可以根据提示选择提前预装 GPU 驱动,可以避免后续安装驱动的麻烦。
然后,通过 ssh 连接上我们选购的服务器,并使用 nvidia-smi 查看 GPU 信息
部署自己的交互式Python开发环境JupyterLab
希望获得本地或云端强大的计算能力,又希望获得 Jupyter Notebook 或 Colab 中方便的在线 Python 交互式运行环境,可以自己为的本地服务器或云服务器安装 JupyterLab。JupyterLab 可以理解成升级版的 Jupyter Notebook/Colab,提供多标签页支持,在线终端和文件管理等一系列方便的功能,接近于一个在线的 Python IDE。
在已经部署 Python 环境后,使用以下命令安装 JupyterLab:
pip install jupyterlab
然后使用以下命令运行 JupyterLab:
jupyter lab --ip=0.0.0.0
然后根据输出的提示,使用浏览器访问 http://服务器地址:8888 ,并使用输出中提供的 token 直接登录(或设置密码后登录)即可。
可以使用 --port 参数指定端口号。
部分云服务(如 GCP)的实例默认不开放大多数网络端口。如果使用默认端口号,需要在防火墙设置中打开端口(例如 GCP 需要在 “虚拟机实例详情 - 网络接口 - 查看详情” 中新建防火墙规则,开放对应端口并应用到当前实例)。
如果需要在终端退出后仍然持续运行 JupyterLab,可以使用 nohup 命令及 & 放入后台运行,即:
nohup jupyter lab --ip=0.0.0.0 &
程序输出可以在当前目录下的 nohup.txt 找到。
为了在 JupyterLab 的 Notebook 中使用自己的 Conda 环境,需要使用以下命令:
conda activate 环境名(比如在GCP章节建立的tf2.0-beta-gpu)
conda install ipykernel
ipython kernel install --name 环境名 --user
然后重新启动 JupyterLab,即可在 Kernel 选项和启动器中建立 Notebook 的选项中找到自己的 Conda 环境。
TensorFlow 性能优化
尽量减少 operation 的个数,尽量多用矩阵或者张量运算而不是 for 循环,这样可以让后端更有空间对你的模型计算进行并行优化,计算机做矩阵张量运算是有很高效的方法的(这点和 MATLAB 很像)。
相对于模型的训练而言,有时候预处理反而是一件更为耗时的工作,搞不好训练只花 1 秒结果准备数据花了 5 秒,这时候你再怎么提高模型性能都没辙,优化预处理的步骤以及调整 pipeline 才是关键。这方面 tf.data 或许可以帮到你的忙,可以参考这篇文章。 https://www.tensorflow.org/guide/performance/datasets
模型本身的类型也会对性能有影响,一个非常不严谨的大致印象是加速效率 CNN>RNN>RL。CNN 相对比较好 GPU 加速,RNN 因为存在时间依赖的序列结构,很多运算必须顺序进行,因此 GPU 带来的性能提升相对较少。RL(增强学习)不仅存在时间依赖的序列结构,还要频繁和环境交互,GPU 带来的提升就更为有限。由于 CPU 和 GPU 之间的切换本身需要耗费资源,有些时候使用 GPU 进行强化学习反而性能明显次于 CPU,尤其是模型本身较小而交互特别频繁的场景(比如非联合动作的多智能体强化学习)。
总之,模型运行得慢,不见得一定是机器性能不够好的缘故,在购买高性能硬件的时候可以多思考一下自己有没有充分使用现有硬件的性能,或者借 / 租一台高性能机器(如 GCP)看看性能到底能提升多少。(当然如果只是想找个买新机器的借口的话当我没说)
参考资料与推荐阅读
如果你是一名在校大学生,具有较好的数学基础,可以从以下教材入手,作为学习机器学习的起点:
如果你希望更具实践性的内容,推荐以下书籍:
-
Aurélien Géron. 机器学习实战:基于 Scikit-Learn 和 TensorFlow . 机械工业出版社,2018.
-
郑泽宇,梁博文,and 顾思宇. TensorFlow:实战 Google 深度学习框架(第 2 版) . 电子工业出版社,2018.
如果你对大学的知识已经生疏,或者还是高中生,推荐首先阅读以下教材:
-
汤晓鸥,and 陈玉琨. 人工智能基础(高中版) . 华东师范大学出版社,2018.
对于贝叶斯的视角,推荐以下入门书籍:
-
皮隆,辛愿,钟黎,and 欧阳婷. 贝叶斯方法:概率编程与贝叶斯推断 . 人民邮电出版社,2017.
如果你喜欢相对生动的视频讲解,可以参考以下公开课程:
-
台湾大学李宏毅教授的《机器学习》课程 ( 讲义点此 ,中文,讲解生动且更新及时)
-
谷歌的《机器学习速成课程》 (内容已全部汉化,注重实践)
-
Andrew Ng 的《机器学习》课程 (英文含字幕,经典课程,较偏理论,网络上可搜索到很多课程笔记)
相对的,一本不够适合的教材则可能会毁掉初学者的热情。对于缺乏基础的初学者,不 推荐以下书籍:
-
Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 深度学习 . 人民邮电出版社,2017.
-
又名 “花书”(源于封面),英文版 在线开放阅读 ,中译见 exacity/deeplearningbook-chinese 。这是一本深度学习领域的全面专著,但更像是一本工具书。
-
-
Bishop, Christopher M. Pattern Recognition and Machine Learning . Information Science and Statistics. New York: Springer, 2006.
-
又名 “PRML”(书名首字母缩写),目前已开放 免费下载 。以贝叶斯的视角为主,同时其难度可能很不适于缺乏数学基础的入门者。
-
术语中英对照表
-
张量 Tensor
-
变量 Variable
-
操作 Operation
-
优化器 Optimizer
-
层 Layer
-
导数(梯度) Gradient
-
损失函数 Loss Function
-
评估指标 Metrics
-
即时执行模式 Eager Execution
-
图执行模式 Graph Execution
-
计算图(数据流图) Dataflow Graph
-
多层感知机 Multilayer Perceptron, MLP
-
卷积神经网络 Convolutional Neural Network, CNN
-
循环神经网络 Recurrent Neural Network, RNN
-
强化学习 Reinforcement Learning, RL
-
深度强化学习 Deep Reinforcement Learning, DRL
-
多智能体强化学习 Multi-Agent Reinforcement Learning, MARL
-
批次 Batch
-
形状 Shape
-
容器 Container
-
推断 Inference
-
列表 List
-
字典 Dictionary, Dict
-
命名空间 Namespace
-
操作节点 OpNode
-
上下文 Context
-
上下文管理器 Context Manager
-
梯度带 GradientTape
-
监视 Watch