在研究OpenCV人脸识别算法时,了解到其中OpenCV特征脸法Eigenfaces是基于主成分分析法(principal component analysis,简称PCA),后来再了解到PCA不仅仅是在人脸识别算法中广泛使用,在其他需要数据降维时也大有用武之地。因此有必要对其原理做一次较为深入的研究。
1.小孩的成绩
小学的时候,课程很少,主要是语文和数学两门课,某一次期末考试后,小明他爸看了班级成绩单,如下表,他爸爸一眼就能看出来自己的儿子成绩最好
| 学生姓名 |
语文 |
数学 |
| 小明 |
85 |
93 |
| 小红 |
70 |
92 |
| 小亮 |
60 |
93 |
而能够一眼看出来是因为语文拉开了大家的分数。因为数学拉不开成绩,基本可以忽略,只需要关注语文成绩。到了高中时候,课程从2门课增加到7门课,某一次期末考试,小明他爸再一次看班级成绩单,如下:
| 学生姓名 |
语文 | 数学 | 几何 | 英语 | 化学 | 物理 | 生物 |
| 小明 |
88 | 66 | 55 | 66 | 84 | 82 | 76 |
| 小红 |
67 | 77 | 60 | 65 | 69 | 60 | 78 |
| 小亮 |
79 | 80 | 69 | 56 | 69 | 69 | 58 |
这个时候小明他爸很难一眼看出来自己的儿子成绩是不是班级第一,他只能用算平均成绩再进行排名。
小明他爸在评估自己儿子排名时,不论是小学时候的成绩还是高中时候的成绩,他都用了一个降维的思想,例如小学时候,忽略数学成绩,只看语文成绩,这是由2个指标降到1个指标,降维的过程带来了一点信息丢失,例如数学成绩虽然拉不开距离,但还是有微小的浮动,只不过这个微小的浮动对大局没有任何影响。高中成绩同理,由1个平均成绩代替7门课,降维的过程更暴力,同时也带来了更严重的信息的丢失,例如小明的几何是不及格的,但在平均成绩里没有体现。当时小明他爸正要奖励小明时,班主任打电话过来提醒要多补补几何课程,小明不仅仅奖励没了,还挨了一顿臭骂。
这个例子好像只提到降维,主成分呢?主成分可以理解为主要矛盾,小明他爸的主要矛盾是小明在班级里的排名,小学时候,用语文成绩即可知道小明的排名,语文成绩就是主成分,高中时候用平均成绩知道排名,那么平均成绩就是主成分。
主成分分析法实际上是将数据降维,进而筛选出主成分用于分析问题。最理想的降维过程是既实现降维,选出主成分,又能够尽量保留原信息。
2.数据降维
上面例子是关于降维的简单例子,例子里提到了降维的动机,并描述了降维的朴素思想,但这个例子尚不能提供具有操作方法。例如,我们知道平均成绩会把学生的个性信息丢失,那么我们怎么衡量信息丢失呢?如果不用平均成绩,我们应该怎么做才好?
为了量化的回答这些问题,必须依靠数学。
我们再看一个例子。
假设直角坐标系上有A,B和C三个点,坐标为A点(2,2),B点(2,1),C点(-2,1)。这些点在由x轴和y轴构成的二维平面上。现在尝试这几个点降维,使用1维信息来体现他们的位置。首先尝试用这些点投影到x轴,即直接用x分量体现A,B,C三个点的位置信息,三个点投影到x轴上时,我们会发现A点和B点是重合了,这表示降维后A和B的相对位置的信息丢失了,如果我们把点投影到y轴上,同样存在B点和C点重合的问题。

直接投影到坐标轴降维的效果都不太好,但二维平面那么多直线,不一定非得投影到坐标轴,我们再另外画一条直线,如下图所示,A,B,C三个点在其上投影得到A',B',C'三个点,这个时候,三个点位置不重合,一定程度上反映了原先A,B,C三个点的位置信息。现在的问题是,如果按照这个思路,我们可以画出无数条直线,那一条才是我们所需要的?要回答这个问题,先复习一下线性代数的知识

3.向量内积
为什么要提及向量内积?因为向量内积和投影。
我们来看向量内积是什么,向量内积是对这两个向量对应位一一相乘之后求和的操作,如下所示,对于向量a和向量b:
a和b的内积公式为:
从这个公式看,看不出和投影的关系,但向量内积还有几何意义,我们来看下向量内积的几何意义,也许能发现一些东西。
如图所示,a和b为两个向量,两个向量的夹角为θ,现在从向量b的末端点引一条和向量a相交的垂线,我们知道垂线和B的交点叫做a在b上的投影,投影长度长度为|b|cos(θ),其中|b|是向量b的模,也即b线段的标量长度。

这个公式有啥用途?这其实是向量内积另一种形式:
a⋅b=|a||b|cos(θ)
这个公式的推导过程如下:
首先看一下向量组成:

定义向量c=a-b
根据三角形余弦定理(这里a、b、c均为向量,下同)有:
根据关系c=a-b有:
因此:
a∙b=|a||b|cos(θ)
这个公式表示a与b的内积等于b到a的投影长度乘以a的模。再进一步,假设a的模为1,即让|a|=1,那么公式变成:
a⋅b=|b|cos(θ),也就是说,假设向量b的模为1,则a与b的内积值等于b向a所在直线投影的矢量长度。这也就是向量内积的几何意义,知道了这个意义,我们再回头看看图1直角坐标里的向量。例如向量A,向量A在x轴的投影其实就是向量A和沿着x轴的单位向量(因为单位向量模为1)的内积,同理在y轴的投影是向量A和沿着y轴的单位向量内积,换句话说,直角坐标系下的向量(x,y)实际上是由沿着x轴和沿着y轴单位向量的内积构成的,用内积公式表示为,其中
和
分别表示沿着x轴的单位向量和沿着y轴的单位向量。除了向量A,向量B和向量C都可以以这个形式表示,区别只是x和y值不同,换句话说,直角坐标系下的任何向量,都是由这两个单位向量线性组合构成,因此这两个向量被称为一组基底(bias)。
对于基的定义,百度百科的解释是:在线性代数中,基(也称为基底)是描述、刻画向量空间的基本工具。向量空间的基是它的一个特殊的子集,基的元素称为基向量。向量空间中任意一个元素,都可以唯一地表示成基向量的线性组合。这个解释看起来较为抽象,对此稍微再做更通俗的解释。
假设没有直角坐标,对于向量A,我们除了知道这是个向量外,没有更多信息。如果想向其他人说明这向量,只能指着向量A说,你看,这是一个向量。这个向量的长度是多少,方向是什么?如果没有一个基准,我们根本无从回答。为了确定向量信息,我们需要给出一个基准,对于向量A,我们可以选择在直角坐标确定其信息,例如描述向量A是可以通过“从原点开始,沿着x轴方向走2步,再沿着y轴方向走2步”来指定向量A的位置。
x轴和y轴上的单位向量只是二维空间中的一组基底,其实还有其他无数的基底,就像苹果这个东西,中文称之为“苹果”,英文称之为“Apple”,阿拉伯语又是另一个单词,东西一样,发音不一样。

当然也不是任何一组向量都可以称之为基底,一组向量需要满足两个条件才能称为基底,第一个是任何向量都可以表示为基底的线性组合,第二个是这种表示方法是唯一的。这两个条件其实可以合二为一,那就是构成基底的向量是线性无关的。所谓的线性无关就是构成基底中的任何向量都不能由其他基底中的其他向量线性组合构成。
例如三基色,三种基色(红,黄,蓝)是相互独立的,任何一种基色都不能有其它两种颜色合成,这三种颜色就是色彩空间的基底。

构成基底的这两个条件不算苛刻,因此一个向量空间内存在许多基底,也就是说,一个向量可以由许多不同的基底来描述,问题来了,向量如何在不同的基底之间转换。
继续看图1种向量B在直角坐标系中坐标是(2,1)。现在我们用另外一个基底来描述它,我们选择向量(1,1)T和(-1,1)作为基底,这两组向量穿过原点并和x轴和y轴形成45°角,可以理解成将直角坐标逆时针旋转45度。我们而令其模为1,只要让两个分量分别除以模就好了。这样上面的基可以变为,
。向量B在这个基底上的坐标其实就是由向量B分别在这组向量上的投影构成。既然是投影,那可以直接用向量内积公式:
于是我们得到了向量B在新基底下的坐标
上述过程实际上可以用矩阵相乘的形式简洁的表示这个变换:
其中矩阵的两行分别为两个基向量,乘以原向量,其结果刚好为新基底下的坐标。

这个公式可以推广到更一般的情况,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果。
其中是一个行向量,表示第i个基,
是一个列向量,表示第j个原始数据记录。R决定了变换后数据的维数,假如R小于N,那么将一个N维数据变换到更低维度的空间中去。这就是降维变换过程。向量B的例子还是在同一个空间中,因此转换之后还是2维,如果向一维的空间中,即直线上投影,那就是降维。
4.优化目标
我们知道了转换基的方法,也知道了降维的方法,又回到图2中例子,向量B要降维到直线上,那那一条直线才是最好的,或者说如何选择基才是最优的。所谓最优,就是降维过程中,又尽可能保留原有信息。我们看到,图2中三个向量投影到坐标轴存在点重合的问题,投影到蓝线上点倒是没有重合,基于这个问题,我们希望投影后的投影值尽可能分散。而点的分散程度,在数学上是有方差来描述的。方差用于衡量一组数据时离散程度。一组数据的方差可以看做是每个数据与均值的差的平方和的均值,即:

如果数据经过中心化处理,即原数据减去改组数据的平均值,该组数据的均值变为0,那么数据的方差可以直接用每个数据的平方和除以元素个数表示:
有了方差这个度量方式后,于是上面的降维问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。但是,方差只适用于一维的情况,也就是衡量一个维度内部数据的分散情况,例如3维xyz坐标降为2维xy坐标,x轴和y轴上的点分别用方差衡量分散情况,但是x轴和y轴之间的关系无法用方差衡量。
我们降维的目标是降维后尽可能保留更多的原始信息,我们希望降维后在每个维度上的数据越分散越好,那各个维度之间的关系应该怎么衡量比较合适?用相关性,如果各个维度之间有相关性,表示不是完全独立,那就存在重复的信息,正好数学上有协方差来衡量相关性。协方差可以通俗理解为两个变量变化过程是同向变化还是反向变化,例如变量A变大,变量B也跟着变大,那么他们的关系就是正相关性,协方差为正,意味着A追随B或者B追随A,如果变量A变大,变量B就变小,反过来也一样,那他们是负相关性,协方差为负,意味着A和B总是对着干,如果变量A变大或变小,对B完全没有影响,反过来也成立,那么他们就没有什么相关性,协方差为0,意味着A和B完全独立,相互屏蔽朋友圈,老死不相往来。理解了协方差,那么我们降维优化目标之二是令各个维度之间相关性为0,即协方差为0.为了让协方差为0,我们选择第二个基底时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
协方差公式如下:
其中,和
表示a和b的均值,如果a和b是已经过中心化处理后的数据(又一次提到中心化,关于中心化,见附录说明),则
和
为0,协方差公式变为更简洁的形式:
如果变量a和变量b相同,即Cov(a,a),
这个公式看起来很熟悉,没错,就是上文提到的方差公式,同一个变量的协方差等于其方差。需要注意的是,协方差也只能处理二维问题,对于维数大于2的情况,需要计算多个两两之间的协方差,例如对于3维度情况,要计算Cov(a,b),Cov(a,c),Cov(b,c),对于多维度的情况,我们使用矩阵来组织他们之间的协方差,协方差矩阵的定义如下:
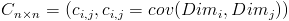
其中,分别表示第i和第j个维度的变量,例如有三维度{a,b,c},协方差矩阵如下:
对于协方差矩阵,我们注意到,矩阵对角线上是方差,其他位置元素是协方差。再回想一下我们的降维优化目标:将一组N维向量降为K维(0<K<N),目标是选择K个单位(模为1)正交基,优化目标是原始数据变换到这组基上后,新基底下数据的各维度两两之间协方差为0,而维度内方差则尽可能大。而协方差矩阵正好把方差和协方差整合到一起了,因此优化目标变成令协方差矩阵对角线上的方差尽可能大,而非对角线元素为0.
5.优化方法
我们已经把优化目标整合到了一个协方差矩阵,潜意识里已经告诉我们,接下来就是对矩阵进行各种线性代数运行来求解,实际上正是这样。
先来看3维的情况,3维数据的协方差矩阵代入方差和协方差公式如下:
协方差转换成这个形式之后,非对角元素是向量内积的结构(),我们知道原数据矩阵如下
原数据的转置矩阵如下:
原数据矩阵和原数据转置矩阵内积结果如下,
结果再乘以就是协方差矩阵啊,设我们有m个n维数据,将其按列排成n
m的矩阵X,则
构成
的协方差矩阵。有了这个关系,我们继续往下走。设原数据
对于的协方差矩阵为
,
是新基组成的矩阵,
是原数据在新基底下的值。我们降维的目标是令X在新基底下的值的协方差矩阵对角线上的方差最大,非对角线上的协方差为0.那新基底下的值的协方差矩阵
和原数据协方差矩阵
是否有什么关系?
我们刚刚简单推导了矩阵和其协方差矩阵的公式,现在直接套用一下,新基底下的值的协方差矩阵如下:
根据第二节向量内积提到了新基矩阵和原数据的内积正好是新基底下的值,描述这个关系的公式是:,把这个公式代入到新基底下数据的协方差矩阵:
现在优化目标变成是寻找一个矩阵P,使得对角化,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
问题变成矩阵对角化问题。
而是实对称矩阵,线性代数有定理,对此矩阵必有正交矩阵P,使得
,其中
是以
的n个特征值为对角元素的对角矩阵。
接下来的问题就是求的特征值和特征向量,具体解法参阅线性代数相关书籍。
6.总结
1)数据降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的;
2)降维的目标在减少需要分析的指标同时,尽量减少原指标包含信息的损失;
3)数据的分散程度使用方差衡量,数据之间的相关程度使用协方差衡量,降维优化目标是方差最大,而协方差为0;
4)数据的协方差矩阵整合了方差和协方差;
4)数据矩阵和数据转置矩阵可构成原数据的协方差矩阵;
5)降维优化实际上是线性代数中的协方差矩阵对角化;
5)数据处理之前,先进行去中心化,即每一位特征减去各自的平均值;
6)计算协方差矩阵
7)用特征值分解方法求协方差矩阵 的特征值与特征向量;
8)对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P;
9)将数据转换到k个特征向量构建的新空间中,即Y=PX。
附录1.数据中心化
数据的中心化是指原数据减去数据的平均值,经过中心化处理后,原数据的坐标平移至中心点(0,0),该组数据的均值变为0。
简单举例:譬如某公司员工共5人,5人的工资,分别为5000、6000、5500、3000、4000元,这5个数据作为一个独立的数据集,平均值为4700元,每个人的工资依次减去平均工资4700,得到300、1300、800、-1700、-700,新的5个数据其平均值等于0,这个过程就是数据的中心化。
附录2.特征值和特征向量
对m阶方阵A,若存在数λ,及非零向量(列向量)x,使得Ax = λx,则称λ为A的特征值,x为A的属于特征值λ的特征向量。
• 特征向量不唯一
• 特征向量非零
特征向量的几何意义是使得方阵A在同方向或者反方向上伸缩 λ倍。
参考
1.http://blog.codinglabs.org/articles/pca-tutorial.html
2.https://www.imooc.com/article/36272
3.https://blog.csdn.net/zhongkelee/article/details/44064401
4.http://web.xidian.edu.cn/qlhuang/files/20150705_224250.pdf
