文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
-
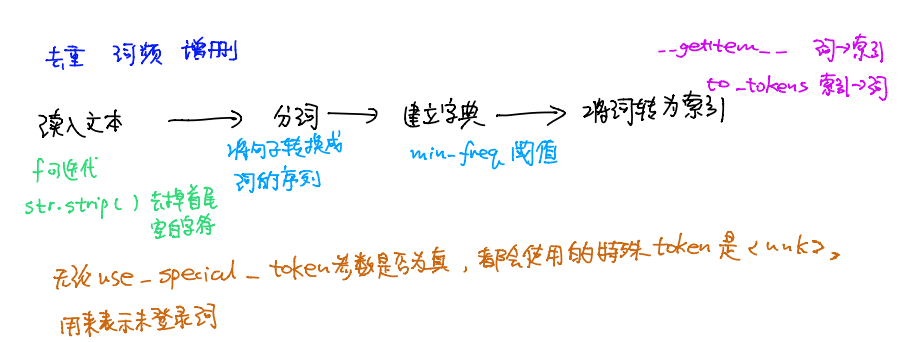
读入文本
-
分词
-
建立字典,将每个词映射到一个唯一的索引(index)
-
将文本从词的序列转换为索引的序列,方便输入模型
函数:
-
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
-
re.sub('a', 'b') 替换功能,将'a'替换成'b'
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
读入文本
分词
建立字典,将每个词映射到一个唯一的索引(index)
将文本从词的序列转换为索引的序列,方便输入模型
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
re.sub('a', 'b') 替换功能,将'a'替换成'b'