NLP——文本处理预处理
词袋模型(Bag of Words, BoW)
从字面意义上来看,文档包含词、短语、句子和段落等要素,在多数文本分类方法中,都将文本中出现的这些要素作为文本特征,而且随着要素级别的增高,其表达的语义越清晰,附带的信息也越丰富,但是特征组合的数目也会越大,因此,很少使用句子和段落作为特征。根据研究人员的实验,目前常见的特征项表示方法有:词、短语(Phrase)和 N-gram 项等。
词袋模型将一段文本作为一个个分离的词进行处理,通过不同类文本中可能出现词的差异对文本进行分类。必须指出的是对于文本分类,上下文对于其真正的类别有着强相关性。个人理解此类方法可能只是为了算法的简易性选择性地放弃了文本中的上下文信息,或者说只关注词频信息也能够获得符合要求的文本分类效果。
词袋模型的三部曲:分词(tokenizing),统计修订词特征值(counting)与标准化(normalizing)。
在词袋模型统计词频的时候,可以使用 sklearn 中的 CountVectorizer 来完成。
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)
corpus = [ 'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
X = vectorizer.fit_transform(corpus)
feature_name = vectorizer.get_feature_names()
print('============== X ===================')
print(X)
print('============== feature name =======')
print(feature_name)
print('============== X.toarray ==========')
print(X.toarray())
'''
# Output
============== X ===================
(0, 1) 1
(0, 2) 1
(0, 6) 1
(0, 3) 1
(0, 8) 1
(1, 5) 2
(1, 1) 1
(1, 6) 1
(1, 3) 1
(1, 8) 1
(2, 4) 1
(2, 7) 1
(2, 0) 1
(2, 6) 1
(3, 1) 1
(3, 2) 1
(3, 6) 1
(3, 3) 1
(3, 8) 1
============== feature name =======
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
============== X.toarray ==========
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]
'''CountVectorizer 的 fit_transform 方法返回一个词频向量化矩阵,对应矩阵的第 i 行第 j 列表示第 i 个文本包含多少个第 j 个特征词。
TF-IDF处理
但是对于某些词,比如上述中的 is, the, 它们在文本中出现的频次很高,但是由于每类文本都具有大量的此类特征词,因此此类特征词对于文本分类的作用是很小的。如果一味追求词频可能将造成最后算法效果的下降。为评估或者说去除此类问题的发生,通常引入 TF-IDF 来对词频进行调整。
词频(Term Frequency,TF):

逆向文件频率(Inverse Document Frequency,IDF):
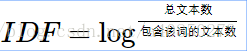
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
可以在使用上述方法之后,再对结果进行调整。
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus = [ 'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
vectorizer=CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
print('============== tfidf ===================')
print(tfidf)
'''
# Output
============== tfidf ===================
(0, 8) 0.438776742859
(0, 3) 0.438776742859
(0, 6) 0.358728738248
(0, 2) 0.541976569726
(0, 1) 0.438776742859
(1, 8) 0.272301467523
(1, 3) 0.272301467523
(1, 6) 0.222624292325
(1, 1) 0.272301467523
(1, 5) 0.853225736145
(2, 6) 0.28847674875
(2, 0) 0.552805319991
(2, 7) 0.552805319991
(2, 4) 0.552805319991
(3, 8) 0.438776742859
(3, 3) 0.438776742859
(3, 6) 0.358728738248
(3, 2) 0.541976569726
(3, 1) 0.438776742859
'''当然也可以直接使用 TfidfVectorizer 直接得到最后的结果。
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [ 'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
tfidf_vectorizer = TfidfVectorizer()
tfidf = tfidf_vectorizer.fit_transform(corpus)
print('============== tfidf ===================')
print(tfidf)
'''
# Output
============== tfidf ===================
(0, 8) 0.438776742859
(0, 3) 0.438776742859
(0, 6) 0.358728738248
(0, 2) 0.541976569726
(0, 1) 0.438776742859
(1, 8) 0.272301467523
(1, 3) 0.272301467523
(1, 6) 0.222624292325
(1, 1) 0.272301467523
(1, 5) 0.853225736145
(2, 6) 0.28847674875
(2, 0) 0.552805319991
(2, 7) 0.552805319991
(2, 4) 0.552805319991
(3, 8) 0.438776742859
(3, 3) 0.438776742859
(3, 6) 0.358728738248
(3, 2) 0.541976569726
(3, 1) 0.438776742859
'''