文章目录
根据上节课的流程,本节先讲前面四个东西。
Word Segmentation
常见工具
Jieba分词https://github.com/fxsjy/jieba
SnowNLP https://github.com/isnowfy/snownlp
LTP http://www.tp-cloud.com/
HanNLP https://github.com/hankcs/HanLP/
其中jieba最常用
下面是使用例子:
#encoding=utf-8
import jieba存基于jeba的分词
seg_list=jieba.cut("贪心学院专注于人工智能教育",cut_all=False)
print("Default Mode:"+"/".join(seg_list))
jieba.add word(“贪心学院")seg_list=jieba.cut("贪心学院专注于人工智能教育",cut_all=False)
print("Default Mode:"+"/".join(seg_list))
结果:
Default Mode:贪心/学院/专注/于/人工智能/教育
Default Mode:贪心学院/专注/于/人工智能/教育
Segmentation Method 1:Max Matching(最大匹配)
前向最大匹配(forward-max matching)
例子:我们经常有意见分歧
词典:[“我们”,“经常”,“有”,“有意见”,“意见”,“分歧”]
第一步:
先要设定一个变量maxlen=5,因此刚开始的窗口大小为5:
【我们经常有】意见分歧
由于词典没有这个词,所以把窗口减小
【我们经常】有意见分歧×
【我们经】常有意见分歧×
【我们】经常有意见分歧√
找到了一个匹配的词:我们
第二步:
【经常有意见】分歧×
【经常有意】见分歧×
【经常有】意见分歧×
【经常】有意见分歧√
找到了一个匹配的词:经常
一直循环下去,知道全部找完。
后最大匹配(backward-max matching)
例子:我们经常有意见分歧
词典:[“我们”,“经常”,“有”,“有意见”,“意见”,“分歧”]
这个和前向相反,稍微说一下:
第一步:
先要设定一个变量maxlen=5,因此刚开始的窗口大小为5:
我们经常【有意见分歧】×
我们经常有【意见分歧】×
我们经常有意【见分歧】×
我们经常有意见【分歧】√
找到了一个匹配的词:分歧
第二步:
我们【经常有意见】分歧×
我们【经【常有意见】分歧×
我们【经常【有意见】分歧√
找到了一个匹配的词:有意见
后面就不说了。
Max Matching(最大匹配)的缺点
属于贪心算法,只能得到局部最优解
效率不高
不能考虑歧义
没有细分,例如上面的【有意见】应该分成【有】【意见】
Segmentation Method 2:Incorporate Semantic(考虑语义)
例子:经常有意见分歧
词典:[“有”,“有意见”,“意见”,“分歧”,“见”,“意”]
把整个考虑语义的算法看成一个模块,吃进去句子分词的形式,吐出来该形式的概率,概率越大,说明越像人话,例如:
【经常】【有意见】【分歧】经过模块得到0.3
【经常】【有】【意见】【分歧】经过模块得到0.6
说明第二种分词要比第一种好。
整个算法步骤:
1、读取语句;
2、生成所有的分割组合;
3、判断概率最大的分割组合。(这事情是有专门的模块或者说工具可以帮我们来解决,这个工具就是language model)
关于LM如何怎么计算概率,之前的课程有说了,就是马尔科夫假设。
缺点
复杂度太高,就是那个第二步太多组合。。。
要解决这个问题,就是用经典的动态规划算法维特比算法。
这个算法就是把方法2中的第一步和第二步结合起来考虑 。
例子:“经常有意见分歧”
词典:[“经常”,“经”,“有”,“有意见”,“意见”,“分歧”,“见”,“意”,“见分歧”,“分”]
概率:[0.1,0.05,0.1,0.1,0.2,0.2,0.05,0.05,0.05,0.1]
-log(x):[2.3,3,2.3,2.3,1.6,1.6,3,3,3,2.3]
这里log加负号是为了转换为求最小值。
解决方案:
先画这么一个图
下图中的数字就是单个字在上面对应的概率,如果对应的字没有概率我们就假设:

看完单个字,我们来看两个字的:

然后看3个字的
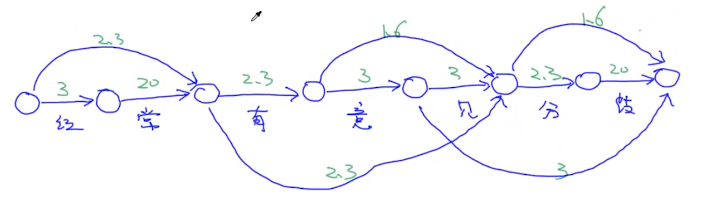
词典里面没有四个字符的。。。画图就完毕了
把左边看做开始,把右边看做结束
那么从开始到结束有很多个路径,那么路径长度就是一个有向带权图。
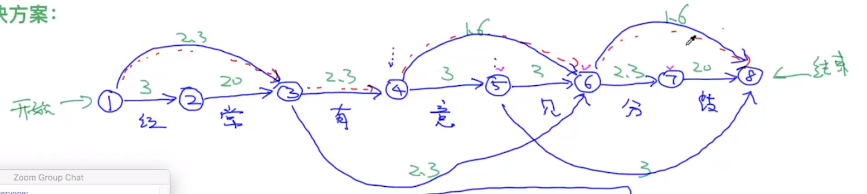
然后找一条最短的路径,求这个最短路径有很多方法,这里用维特比。
用
表示从节点1到8的最短路径
用
表示从节点1到7的最短路径
以此类推。。。
现在要求
,
有三个可能:
从上面三个找最小的那个
:只有一种可能,从
过来。
有三个可能:从3,4,5过来。
本来可以用递归来实现,但是递归效率不好,就先把计算结果保存到数组中:
| f(1) | f(2) | f(3) | f(4) | f(5) | f(6) | f(7) | f(8) |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 2.3 | 4.6 | 7.6 | 4.6 | 7.9 | 6.2 |
| 1 | 1 | 1 | 3 | 4 | 3 | 6 | 6 |
下面一行是上个节点的序号,然后反推出路径是:1、3、6、8。
Word Segmentation Summary知识点总结:
-基于匹配规则的方法:最大匹配
-基于概率统计方法(LM,HMM,CRF)
-分词可以认为是已经解决的问题
需要掌握什么?
-可以自行实现基于最大匹配和Unigram LM的方法
Spell Correction (拼写纠错)
概念
(用户输入(input)用户输入(correction)
天起---------------------------------天气
theris------------------------------------theirs
机器学系-------------------------------机器学习
拼写错误有两种:
1、错别字
2、不是错别字,语法错I go home,应该是I am going home
第一种情况可以直接从词库进行判断,当输入的词不在词库里面,那么就可以判定是错别字。
第二种情况可以用语言模型来判断,当某个位置上的上下文概率很低,那么就可以判断这里出现了语法错误。
Find the words with smallest edit distance
我们把单词与替换词之间用一个概念来描述:编辑距离
可以理解为替换为目标词需要的操作的复杂度。
假设我们定义把错误词替换为目标词有下面三个操作:
1、insert
2、delete
3、replace
therr这个词到there的编辑距离为一个操作(replace操作):
therr这个词到thesis的编辑距离为三个操作(replace+replace+insert)
当然如果编辑距离相同,就需要考虑上下文等因素来进行排序。
计算编辑距离的目的是得到候选(candidates)词,但是这个计算要涉及到词典里面所有词,明显是很低效的。其时间复杂度为:
怎么办?
新方法

怎么来生成?由于操作是固定好的,三个:
1、insert
2、delete
3、replace
假如我们有一个单词appl
如果编辑距离为1,并选择replace操作,可以生成:
bppl/cppl/…
aapl/abpl/…
同样我们还可以用别的操作。
然后把生成得到的单词集合,进行过滤。
这里注意,为什么选择1/2的编辑距离?因为拼写错误大多数情况下都是产生编辑距离为1或2的错误。
过滤
问题定义
给定一个字符串
,我们要找出最有可能成为正确的字符串
,也就是
其中candidates是上一步生成的候选集合,根据贝叶斯公式:
贝叶斯公式的推导:
联合概率有:
公式(1)中,s是给定的,所以
是一个常量,所以可以等价为:
现在c代表正确的输入,s代表用户的输入
正确:apple
用户1:app
用户2:appl
用户3:appl
用户4:app
用户5:appla
用户6:appl
那么
,
代表对于一个正确的字符串c,用户输入成错误的s的几率。
实际上是字符串c的unigram,就是c在所有的文本中出现的几率(或者说出现次数/总词数)。
Stop Words Removal
对于NLP的应用,我们通常先把停用词、出现频率很低的词汇过滤掉,这其实类似于特征筛选的过程。
这里面涉及两大类词汇:
停用词:在英文里,比如“the”,“an",“their”这些都可以作为停用词来处理。但是,也需要考虑自己的应用场景(例如情感分析)
出现频率很低的词汇:出现频率特别低的词汇对分析作用不犬,所以一般也会去掉。把停用词、出现频率低的词过滤之后,即可以得到一个词典库。
Stemming:one way to normalize
词的标准化操作,尤其是对英文单词
下面意思都类似,怎么合并?希望它们回归为原型,但是由于还原操作是基于规则的,所以不一定还原为有效的单词。
went,go,going 还原为go
fly,flies还原为fli
deny,denied,denying还原为deni
fast,faster,fastest还原为fast
最常用Stemming的算法:PorterStemmer
除了这个方法,还有一种方法叫做:lemmatization,它在还原的时候一定是还原为原词的
具体可以参考:
https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
下面具体来看看步骤:
黑色是规则,绿色是例子




