文章目录
Word Representation
独热编码
这个很简单,稍微带过
词典:[我们,去,爬山,今天,你们,昨天,跑步]7个词,7个维度
每个单词的表示:
我们:(1,0,0,0,0,0,0)
爬山:(0,0,1,0,0,0,0)
跑步:(0,0,0,0,0,0,1)
昨天:(0,0,0,0,0,1,0)
Sentence Representation(boolean)
这里是Boolean Representation,后面还会有一种Count based Representation
词典:[我们,又,去,爬山,今天,你们,昨天,跑步]8个词
每个句子的表示
我们今天去爬山:(1,0,1,1,1,0,0,0)8维=词典大小
你们昨天跑步:(0,0,0,0,0,1,1,1)8维=词典大小
你们又去爬山又去跑步:(0,1,1,1,0,1,0,1)8维=词典大小
Sentence Representation(Count )
词典:[我们,又,去,爬山,今天,你们,昨天,跑步]8个词
每个句子的表示
我们今天去爬山:(1,0,1,1,1,0,0,0)8维=词典大小
你们昨天跑步:(0,0,0,0,0,1,1,1)8维=词典大小
你们又去爬山又去跑步:(0,2,2,1,0,1,0,1)8维=词典大小
Sentence Similarity
计算距离(欧式距离):
例如:
S1:“我们今天去爬山”=(1,0,1,1,0,0,0,0)
S2:"你们昨天跑步“=(0,0,0,0,0,1,1,1)
S3:“你们又去爬山又去跑步“=(0,2,2,1,0,1,0,1)
根据公式:
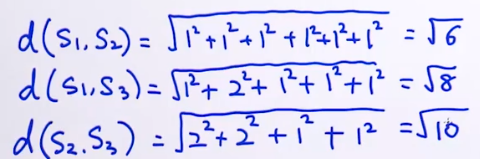
sim代表similarity,距离越小相似度越大
由于向量是有方向的,欧式距离没有考虑方向因素,因此就有了:
计算相似度(余弦相似度):
例如:
根据公式:
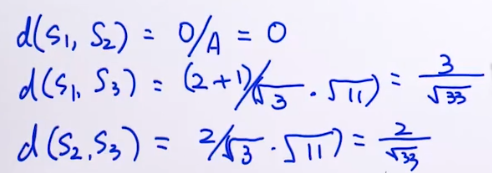
这里d越小,相似度越小,第一个
说明这两个句子意思也是相反的。
例子
句子1:He is going from Beijing to Shanghai
句子2:He denied my request,but he actually lied.
句子3:Mike lost the phone,and phone was in the car
用以上句子构建词库后,用count based representation来表示:
句子1:(0,0,1,0,0,0,1,1,1,0,1,0,0,0,0,0,0,1,0,1,0)
句子2:(1,0,0,1,0,1,0,0,2,0,0,1,0,0,1,0,1,0,0,0,0)
句子3:(0,1,0,0,1,0,0,0,0,1,0,0,1,1,0,2,0,0,2,0,1)
以第二个句子来看,he出现了两次,表示为2,但是句子中最重要的单词denied 由于只出现了一次,所以表示为1,这样是不合理的。
也就是说:并不是出现的越多就越重要,并不是出现的越少就越不重要!
如何解决这个问题?就是:
Tf-idf Representation
公式:
是文档d中w的词频,就是前面所提到的count based representation方法
表示单词的重要性:
:语料库中的文档总数
:词语(w)出现在多少个文档?
加log是防止
太大
例子:
句子1:今天 上 NLP 课程
句子2:今天 的 课程 有 意思
句子3:数据 课程 也 有 意思
抽取出来的词典=[今天,上,NLP,课程,的,有,意思,数据 ,也],9维。

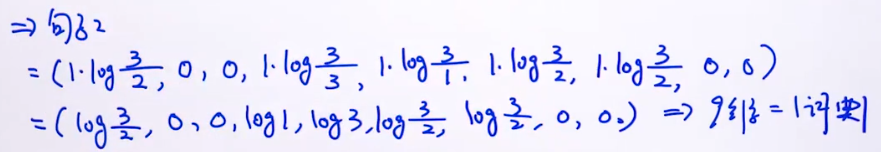

小结
boolean based representation
count based representation
tfidf based representation
都属于one-hot向量。
但是有这些个向量有缺点,例如:
下面哪些单词之间语义相似度更高?
我们,爬山,运动,昨天
我们:(0,1,0,0,0,0)
爬山:(0,0,1,0,0,0)
运动:(1,0,0,0,0,0)
昨天:(0,0,0,1,0,0)
1、欧式距离
d(我们,爬山)=
d(我们,运动)=
d(我们,昨天)=
d(运动,昨天)=
说明这个one-hot不适合表达语义相似度
2、余弦相似度
sim(我们,爬山)=0/1=0
sim(我们,运动)=0/1=0
sim(我们,昨天)=0/1=0
sim(运动,昨天)=0/1=0
说明这个one-hot不适合表达语义相似度
注意,这里的欧氏距离和余弦相似度是没有问题的,问题出在向量的表示方法上。
那么怎么来表示向量才能解决这个问题?那就是词向量!
