最近公共祖先
百科名片
- 最近公共祖先
- Lowest Common Ancestors
- LCA
简单引入
对于有根树T的两个结点u、v,最近公共祖先LCA(T,u,v)表示一个结点x,满足x是u、v的祖先且x的深度尽可能大。
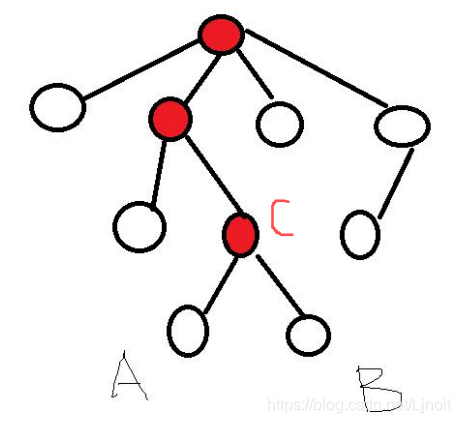
红色的都是是A和B的公共祖先,但只有最近的C才是最近公共祖先。
LCA问题是树上的一个经典问题,在很多方面有着广泛的应用,比如求LCP(最长公共前缀),接下来我们就来介绍他的几种算法。
LCA的算法
暴力枚举法
如果我们要求a和b的最近公共祖先,就沿着父亲的方向把a的所有祖先都标记
一下(类似并查集找父亲,但是没有路径压缩),然后在从b开始往上找祖先,
碰到第一个被标记的点,就是a和b的最近公共祖先。
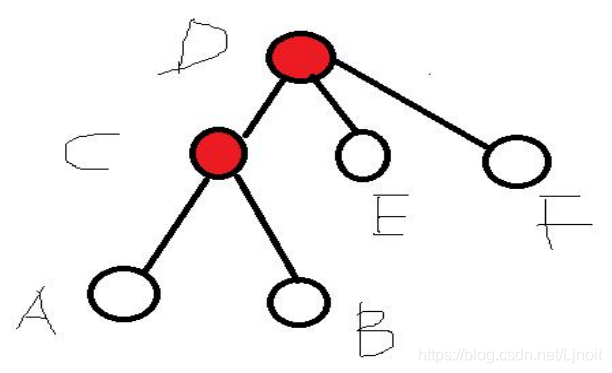
C是最近公共祖先。
求一个对点的LCA时间复杂度高达O(N)。
求m个点对的LCA时间复杂度高达O(mN)。
当m和n都高达10万的时候,超时了!!!
宝宝难以承受!!!!!
求m个点对的最近公共祖先是可以优化的,一般有两种:
1、离线算法(Tarjan离线算法):所谓的离线算法指的是把所有问题收集起来以后一起去算,最后一起回答。
2、在线算法(倍增算法):所谓的在线算法就是来一个点对,处理一个点对。
Tarjan离线算法
Robert Tarjan设计了求解的应用领域的许多问题的广泛有效的算法和数据结构。 他已发表了超过228篇理论文章(包括杂志,一些书中的一些章节文章等)。Robert Tarjan以在数据结构和图论上的开创性工作而闻名。 他的一些著名的算法包括 Tarjan最近共同祖先离线算法 ,Tarjan的强连通分量算法等。其中Hopcroft-Tarjan平面嵌入算法是第一个线性时间平面算法。Tarjan也开创了重要的数据结构如:斐波纳契堆和splay树(splay发明者还有Daniel Sleator)。另一项重大贡献是分析了并查集。他是第一个证明了计算反阿克曼函数的乐观时间复杂度的科学家。
简单的介绍一下tarjan算法:
tarjan算法是离线算法,它必须先将所有的要查询的点对存起来,然后在搜的时候输出结果。
tarjan算法很经典,因为算法的思想很巧妙,利用了并查集思想,在dfs下,将查询一步一步的搜出来。
基本思路:
1 任选一个节点为根节点,从根节点开始
2 遍历该点 u 的所有子节点 v ,并标记 v 已经被访问过
3 若 v 还有子节点,返回 2 ,否则下一步
4 合并 v 到 u 所在集合
5 寻找与当前点 u 有询问关系的点 e
6 若 e 已经被访问过,则可以确定 u、e 的最近公共祖先为 e 被合并到的父亲节点
- 对于我们已经保存好的查询,假设为(u,v),u为此时已经搜完的子树的根节
点,v的位置就只有两种可能,一种是在u的子树内,另一种就是在其之外。 - 对于在u的子树内的话,最近公共祖先肯定是可以直接得出为u。
- 对于在u的子树之外的v,我们已经将v搜过了,且已经知道了v的祖先,那么我们可以根据dfs的思想,v肯定是和u在一颗子树下的,而且这颗子树是使得他们能在一颗子树下面深度最深的。而这个子树的根节点刚好就是v的并查集所保存的祖先。所以对于这种情况的(u,v),它们的最近公共祖先就是v的并查集祖先。
下面给出伪代码:
void Tarjan(u) { // merge 和 find 为并查集合并函数和查找函数
for each(u,v) { // 遍历 u 的所有子节点 v
Tarjan(v); // 继续往下遍历
merge(u,v); // 合并 v 到 u 这一集合
标记 v 已被访问过;
}
for each(u,e) { // 遍历所有与 u 有查询关系的 e
if(e 被访问过)
u, e 的最近公共祖先为 find(e);
}
}
下面给出真代码:
int f[N],n,m,ans[N],check[N];
vector<int> a[N],b[N],id[N];
int find(int x) { return x==f[x] ? x : f[x]=find(f[x]); }
void tarjan(int x) {
f[x]=x;
check[x]=1;
for(int i=0; i<a[x].size(); i++) {
int v=a[x][i];
if(!check[v]) {
tarjan(v);
f[v]=x;
}
}
for(int i=0; i<b[x].size(); i++) {
int v=b[x][i];
if(!check[v]) continue;
ans[id[x][i]]=find(v);
}
}
我们在深度优先遍历的时候,先遍历x节点的
左子树,当遍历到u的时候,发现v没有被遍历过,那么就不去管lca(u,v)这个问题,然后我们把已经遍历的x子树的所有节点都合并到他的父亲(即father指向父亲),然后当我们遍历到v的时候,发现u已经遍历过了,那么此时u在并查集里的father就是u和v的最近公共祖先.
时间复杂度:由于每个点只遍历一次,每个问题只枚举2次,所以时间复杂度是O(N+2Mα(N))。α(N)为并查集查询一次根所需要的时间。
倍增算法
首先一个小问题,给你两个点a和b,你如何快速的回答这两个点在树里面是否具有祖先和后代的关系。
暴力算法又是o(N),明显太浪费时间!
引入时间戳的概念:所谓的时间戳就是在给一棵树进行深度优先遍历的同时,记录下计入每个点的时候和离开每个点的时间。

如图所示,每个节点的左边是进入的时间,右边是离开的时间。
如果a是b的祖先,只要满足 (in[a]<=in[b]) and (out[b]<=out[a])
也就是我们只需要一次深搜,接下来对于任何询问a和b是否有祖先关系的时候,我们只要O(1)的时间就能回答这个问题。
建立倍增数组:
定义f[i][j]为与节点i距离为2^j的祖先的编号。
明显的f[i][0]就是每个点直接的父亲。
另有递推关系:f[i][j]=f[f[i][j-1],j-1]。
于是我们只需要在nlogn的时间内就可以求出f数组的值。
如果f[i][j]不存在,我们就令f[i][j]=根,方便我们计算
接下来如何求a和b的最近公共祖先呢?
1、如果a是b的祖先,那么输出a
2、如果b是a的祖先,那么输出b
3、for i:=20 downto 0 do
if f[a][i]不是b的祖先,那么令 a=f[a][i];
循环结束的时候,f[a][0]就是最近公共祖先。
int lca(int x,int y) {
if(ancestor(x,y)) return x;
if(ancestor(y,x)) return y;
for(int i=20; i>=0; i--)
if(!ancestor(f[x][i],y))
x=f[x][i];
return f[x][0];
}
例题:
CodeVS1036 商务旅行(可惜CodeVS崩溃了)
题目描述
某首都城市的商人要经常到各城镇去做生意,他们按自己的路线去做,目的是为了更好的节约时间。
假设有N个城镇,首都编号为1,商人从首都出发,其他各城镇之间都有道路连接,任意两个城镇之间如果有直连道路,在他们之间行驶需要花费单位时间。该国公路网络发达,从首都出发能到达任意一个城镇,并且公路网络不会存在环。
你的任务是帮助该商人计算一下他的最短旅行时间。
输入描述
输入文件中的第一行有一个整数N,1<=n<=30 000,为城镇的数目。下面N-1行,每行由两个整数a 和b (1<=a, b<=n; a<>b)组成,表示城镇a和城镇b有公路连接。在第N+1行为一个整数M,下面的M行,每行有该商人需要顺次经过的各城镇编号。M<=30000
输出描述
在输出文件中输出该商人旅行的最短时间。
样例输入
5
1 2
1 5
3 5
4 5
4
1
3
2
5
样例输出
7
代码
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cmath>
#include <cstring>
#include <algorithm>
#define RI register int
#define re(i,a,b) for(RI i=a; i<=b; i++)
#define ms(i,a) memset(a,i,sizeof(a))
using namespace std;
typedef long long ll;
int const N=30005;
struct edge{
int to,nt;
} e[N<<1];
int n,m,cnt,sum,ans;
int h[N],vis[N],tin[N],tout[N],dep[N];
int f[N][15];
int ast(int x,int y) {
return tin[x]<=tin[y] && tout[y]<=tout[x];
}
int lca(int x,int y) {
if(ast(x,y)) return x;
if(ast(y,x)) return y;
for(int i=14; i>=0; i--)
if(!ast(f[x][i],y)) x=f[x][i];
return f[x][0];
}
void add(int a,int b) {
e[++cnt].to=b;
e[cnt].nt=h[a];
h[a]=cnt;
}
void dfs(int x,int fa,int d){
tin[x]=++sum;
f[x][0]=fa;
dep[x]=d;
for(int i=h[x]; i; i=e[i].nt) {
int v=e[i].to;
if(v==fa) continue;
dfs(v,x,d+1);
}
tout[x]=++sum;
}
int main() {
scanf("%d",&n);
re(i,1,n-1) {
int x,y;
scanf("%d%d",&x,&y);
add(x,y);
add(y,x);
}
dfs(1,1,0);
re(j,1,14) re(i,1,n)
f[i][j]=f[f[i][j-1]][j-1];
scanf("%d",&m);
int k=1;
re(i,1,m) {
int x;
scanf("%d",&x);
int t=lca(k,x);
ans+=dep[k]+dep[x]-2*dep[t];
k=x;
}
printf("%d\n",ans);
return 0;
}
