正则表达式及re模块
引用re模块
- 打开pycharm,使用命令import re即可。
import re
匹配规则
1.先介绍一个匹配函数,match()函数从字符串开头匹配
2. 匹配某个字符串
text = "hello"
demo = re.match("he",text)
print(type(demo))
print(demo.group())

3.点匹配任意字符。
text = "h"
demo = re.match(".",text)
print(demo.group())
成功打印h

4.\d匹配任意的数字。
text = "1"
demo = re.match("\d",text)
print(demo.group())
成功输出结果1

5.\D匹配任意非数字。
text = "1"
demo = re.match("\D",text)
print(demo.group())

这时候匹配数字就报错了。
6.\s:匹配空白字符(\n,\r,\t,空格)
7.\S 匹配任意非空白字符
8.\w 匹配的是a-z和A-Z以及数字和下划线
9.\W匹配与\w相反
[]组合的方式,只要满足括号中的字符,就可以匹配。
前面讲的也可以用[]组合的方式表示出来
-
\d:[0-9]
-
\D:[^0-9]
-
\w:[0-9a-zA-Z_]
-
\W:[^0-9a-zA-Z]
特殊字符: -
*匹配0个或多个
-
+匹配1个或多个字符
-
?匹配一个或0个
-
^开头匹配(还有在组合中表示除了)
例:
表示匹配除0-9以外的字符。
text = "a"
demo = re.match("[^0-9]",text)
print(demo.group())
表示匹配0-9开头的字符
text = "a"
demo = re.match("^[0-9]",text)
print(demo.group())
- $以…结尾
- {n}——前面的原子恰好出现n次
- {n,}——前面的原子至少出现n次
- {n,m}——前面的原子至少出现n次,至多出现m次
- |——模式选择符,可以设置多个模式,匹配时可以从中选择任意一个模式匹配
小案例
- 匹配11位电话号码
以1为开头;
第二位可为3,4,5,7,8,中的任意一位;
text = '13867929147'
demo = re.match('1[34578]\d{9}',text)
print(demo.group())
- 匹配邮箱
@前面可以是数字和字母以及下划线
@后面点前面是数字或者字母
点后面是字母
text = "[email protected]"
demo = re.match('\w+@[a-z0-9]+\.[a-z]+',text)
print(demo.group())
匹配成功
- 匹配url
text = 'https://editor.csdn.net/md?articleId=104169826'
demo = re.match('(http|https|ftp)://[^\s]+',text)
print(demo.group())
成功匹配
4.身份证匹配
出生年月限制在1900-2020年 、1-12月、 1-31号
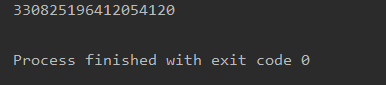
text = "330825196412054120"
demo = re.match('\d{6}(19\d{2}|20([01]\d|20))(0\d|1[0-2])([0-2]\d|3[01])\d{3}(x|X|\d)',text)
print(demo.group())
结果如下:
贪婪模式与非贪婪模式
举例:
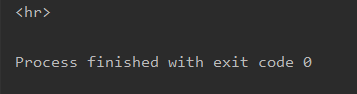
text = "<hr>nihao<hr>"#想匹配第一个<>中的内容
demo = re.match('<.+>',text)
print(demo.group())
并不是想要的结果(’.‘是除换行符以外的任意字符都可以匹配,而’+‘号是一次或多个字符,所以会尽可能多的字符)

但在+号加上?后会尽可能少的去匹配,到不满足条件’>'就停止
转义字符和原生字符
- python里的转义字符:’\’ 原生字符:r
- 正则表达式里面也有转义字符:“\”
下面我们直接用案例来说明 ——匹配“\c”
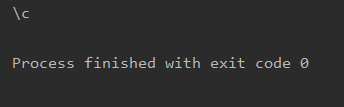
text = '\c'
demo = re.match('\\\\c',text)
print(demo.group())
结果正确
这里为什么要四个"\“呢?
在python语法里面”\\\\“转义为”\\"
在正则表达式的语法中"\\“再次经过转义”"
所以匹配的结果为"\c"
还有一种方法,用原生字符’r’
text = '\c'
demo = re.match(r'\\c',text)
print(demo.group())

因为原生字符’r’取消了python语法转义的那一步
正则表达式的函数
- match():从字符串的开头位置匹配,找到了返回match对象,找不到会返回None
可以看见match()函数需要两个参数(第三个默认),pattern:匹配模式;string:要传入的字符串

- search():和match()比较相似,但可以从字符串任意位置匹配。返回的也是match对象
text = 'hello'
demo = re.search('lo',text)
print(demo)
匹配结果:

- findall():搜索整个字符串,返回字符串中所有正确匹配项组成的列表,即列表中每个元素都能跟正则表达式匹配
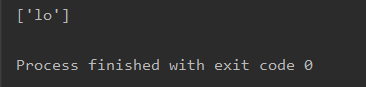
text = 'hello'
demo = re.findall('lo',text)
print(demo)
结果如下:
- sub():用于字符串的修改和替换,类似于replace()

一般只写前三个参数pattern:表示匹配的字符串 repl:表示要替换的字符串(如果去掉的话可以为空)
text = 'hello1221245664'
demo = re.sub('\d','',text)
print(demo)
结果如下:
- Compile():将正则表达式字符串编译成正则表达式对象,以便在后面的匹配中复用
text = 'hello1221245664'
pattern = re.compile('\d')
demo = re.sub(pattern,'',text)
print(demo)
结果如下:

- group():用来提出分组截获的字符串,在匹配模式中用()即可,表示分组
group()和group(0)可以输出整个匹配的字符串
group(1)输出分组第一个括号匹配到的字符串
group(2)输出分组第二个括号匹配到的字符串
如果分组只有三个括号,那么输入group(4)就会报错
groups()以元组方式返回所有分组中匹配到的字符串
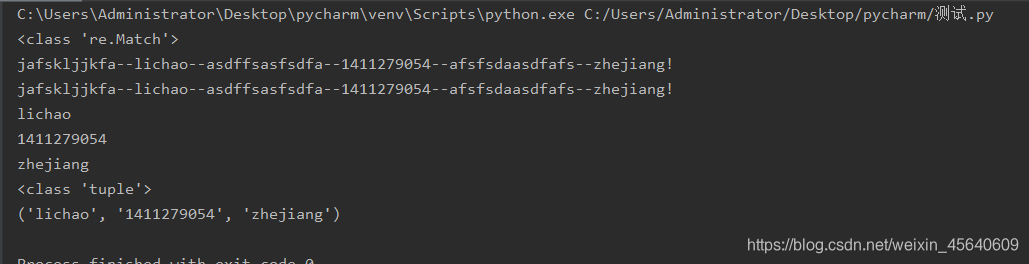
import re
demo = 'jafskljjkfa--lichao--asdffsasfsdfa--1411279054--afsfsdaasdfafs--zhejiang!'
result = re.match('.*?--(.*?)--.*?--(.*?)--.*?--(.*?)!',demo)
print(type(result))
print(result.group(0))
print(result.group())
print(result.group(1))
print(result.group(2))
print(result.group(3))
print(type(result.groups()))
print(result.groups())
输出结果如下: