最近在windows环境中用python2.7抓网页信息,保存到excel中,遇到了一些中文字符问题。研究了好久,才有一些心得。
先说一下gbk和utf8的区别,因为我遇到的问题都是它们2个造成的:
1.utf8和gbk区别
- UTF-8:Unicode TransformationFormat-8bit,。是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8编码的文字可以在各国支持UTF8字符集的浏览器上显示。如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,他们无需下载IE的中文语言支持包。
- GBK是中国国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大。
从上面解释可以明白,GBK和GB2312基本是一回事情。
2.GBK/GB2312与UTF8之间转换
gbk/gb2312和uft8之间都必须通过Unicode编码才能相互转换:
- GBK/GB2312 --> Unicode --> UTF8
- UTF8 --> Unicode --> GBK/GB2312
3.Unicode编码
好了,上面又出现了一个编码Unicode。
懂计算机的应该都知道,计算机最早只有ASCII码,它是用一个字节(8bit, 0-255)中的127个字母表示大小写字母,数字和一些符号,主要用来表示现代英语和西欧语言。
其他国家民族语言编码都是用2个字节来表示的,比如:中国的BG2312。但是这些编码之间互相不兼容,如果给你一串二进制数,想要解码,就必须知道它的编码方式,不然就会出现我们有时候看到的乱码 。
为了统一,Unicode编码出现了,它把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF(十六进制),有110多万,每个字符都有一个唯一的Unicode编号,这个编号一般写成16进制,在前面加上U+。例如:“马”的Unicode是U+9A6C。Unicode就相当于一张表,建立了字符与编号之间的联系。
但是Unicode码只是一种编码的规范,它只规定了每个字符的数字编号是多少,没有定义在计算机中怎么对其存储。
而utf-8、utf-16、utf-32都是 Unicode编码的具体实现,
其中utf-8占用一到四个字节,utf-16占用二或四个字节,utf-32占用四个字节。例如:utf-32中,“马”字是1001 1010 0110 1100。
4.python的编码方式
为python的诞生比Unicode标准发布的时间还要早,所以最早的python只支持ASCII编码,普通的字符串’ABC’在python内部都是ASCII编码的。
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
以后如果遇到以下报错
UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xbd in position
我们可以修改python默认的编码方式。在python的Lib\site-packages文件夹下新建一个sitecustomize.py,其中代码为
# encoding=utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
在idle中保存py文件时候,如果没有指定执行编码方式,会跳以下界面出来。
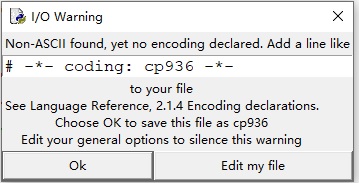
它会在py文件第一行增加cp936编码。
这是因为我使用的是中文windows系统。进入dos窗口,输入:chcp,显示界面如下
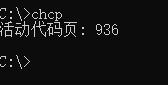
活动代码页为:936,它对于的编码格式为GBK。
如果要想改为uft8,那就这样
# -*- coding:utf-8 -*-
5.python中的print
这里说的是print中文问题。
如果第一行编码是cp936,执行编码方式为gbk,那就没有问题,中文都可以print出来。
但是如果第一行是utf8,那就有问题了,会打印出乱码。改成下面这样就解决了。
print str.decode("utf-8").encode("gbk")
意思是调用decode(“utf-8”),用utf8解码,然后再调用encode(“gbk”),用gbk编码,这样就可以正常print中文了。
6.读取网页的编码
在网页的开头都会有以下代码
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
这个表示的是这个网页的编码方式。常用的就是gb2312和utf8。
搞清楚这个很重要,因为我开始时候没注意,结果代码一直执行出错。
a = urllib.urlopen(url)#打开网址
html = a.read().decode('utf-8')#读取源代码,编码方式为utf-8
7.输出excel
这个是让我觉得最不可思议地方。
我抓取的页面是gb2312编码,py文件第一行指明是cp936编码,但是执行到输出excel时候遇到问题了。
一开始我用的是openpyxl操作excel,它报错,只能接收utf8。然后我尝试改用pandas,结果它其实也是调用的openpyxl。
我尝试把数据改为utf8,str.decode('utf8',保存时候不再报错了,但是excel打开都是乱码。
后来实在没有办法,只好从头到底全部改为utf8编码,print时候转码打印,终于才可以在excel中正常打开。
如果能找到openpyxl接收gbk方式保存的方法那就完美了。
