前言:
目录
ASCII 字符的点阵显示
要在 LCD 中显示一个 ASCII 字符,即英文字母这些字符,首先是要找到字符对应的点阵。
在 Linux 内核源码中有这个文件:lib\fonts\font_8x16.c, 里面以数组形式保存各个字符的点阵,比如:

数组里的数字是如何表示点阵的?以字符 A 为例
上图左侧有 16 行数值,每行 1 个字节。每一个节对应右侧一行中 8 个像素: 像素从右边数起,bit0 对应第 0 个像素,bit1 对应第 1 个像素,……,bit7 对 应第 7 个像素。某位的值为 1 时,表示对应的像素要被点亮;值为 0 时表示对应 的像素要熄灭。
所以要显示某个字符时,根据它的 ASCII 码在 fontdata_8x16 数组中找到它的点阵,然后取出这 16 个字节去描画 16 行像素。
比如字符 A 的 ASCII 值是 0x41,那么从 fontdata_8x16[0x41*16]开始取其点阵数据。
核心函数是
void lcd_put_ascii(int x, int y, unsigned char c)
它在 LCD 的(x,y)位置处显示字符 c,代码如下图所示:

1.获取点阵
对于字符 c,char c,它的点阵获取方法如下:
4693 unsigned char *dots = (unsigned char *)&fontdata_8x16[c*16];2.描点
因为有十六行,所以首先要有一个循环 16 次的大循环,然后每一行里有 8 位,那么在每一个大循环里也需要一个循环 8 次的小循环。小循环里的判断单行 的描点情况,如果是 1,就填充白色,如果是 0 就填充黑色,如此一来,就可以显示出黑色底,白色轮廓的英文字母。
4697 for (i = 0; i < 16; i++)
4698 {
4699 byte = dots[i];
4700 for (b = 7; b >= 0; b--)
4701 {
4702 if (byte & (1<<b))
4703 {
4704 /* show */
4705 lcd_put_pixel(x+7-b, y+i, 0xffffff); /* 白 */
4706 }
4707 else
4708 {
4709 /* hide */
4710 lcd_put_pixel(x+7-b, y+i, 0); /* 黑 */
4711 }
4712 }
4713 }3.main 函数
main 函数中首先要打开 LCD 设备,获取 Framebuffer 参数,实现 lcd_put_pixel 函数;
然后调用 lcd_put_ascii 即可绘制字符
4716 int main(int argc, char **argv)
4717 {
4718 fd_fb = open("/dev/fb0", O_RDWR);
4719 if (fd_fb < 0)
4720 {
4721 printf("can't open /dev/fb0\n");
4722 return -1;
4723 }
4724 if (ioctl(fd_fb, FBIOGET_VSCREENINFO, &var))
4725 {
4726 printf("can't get var\n");
4727 return -1;
4728 }
4729
4730 line_width = var.xres * var.bits_per_pixel / 8;
4731 pixel_width = var.bits_per_pixel / 8;
4732 screen_size = var.xres * var.yres * var.bits_per_pixel / 8;
4733 fbmem = (unsigned char *)mmap(NULL , screen_size, PROT_READ | PROT_WRITE, MAP
_SHARED, fd_fb, 0);
4734 if (fbmem == (unsigned char *)-1)
4735 {
4736 printf("can't mmap\n");
4737 return -1;
4738 }
4739
4740 /* 清屏: 全部设为黑色 */
4741 memset(fbmem, 0, screen_size);
4742
4743 lcd_put_ascii(var.xres/2, var.yres/2, 'A'); /*在屏幕中间显示 8*16 的字母 A*/
4744
4745 munmap(fbmem , screen_size);
4746 close(fd_fb);
4747
4748 return 0;
4749 }
47504.编译 c 文件 show_ascii.c
交叉编译:不同的板子,编译工具的前缀可能不一样,这是使用的是IMX6ULL
arm-buildroot-linux-gnueabihf-gcc -o show_ascii show_ascii.c
把 show_ascii 程序通过 NFS 挂载放到板子上,执行命令:./show_ascii。如果实验成功,我们将看到屏幕中间会显示出一个白色的字母‘A’。
中文字符的点阵显示
1.指定编码格式
使用点阵字库时,中文字符的显示原理跟 ASCII 字符是一样的。要注意的地 方在于中文的编码:在 C 源文件中它的编码方式是 GB2312 还是 UTF-8?编译出 的可执行程序,其中的汉字编码方式是 GB2312 还是 UTF-8?
注意:一般不会使用 UTF-16 的编码方式,在这种方式下 ASCII 字符也是用 2 字 节来表示,而其中一个字节是 0,但是在 C 语言中 0 表示字符串的结束符,会引起误会。
我们编写 C 程序时,可以使用 ANSI 编码,或是 UTF-8 编码;在编译程序时, 可以使用以下的选项告诉编译器:
-finput-charset=GB2312
-finput-charset=UTF-8
如果不指定“-finput-charset”,GCC 就会默认 C 程序的编码方式为 UTF-8,即使你是以 ANSI 格式保存,也会被当作 UTF-8 来对待。
对于编译出来的可执行程序,可以指定它里面的字符是以什么方式编码,可以使用以下的选项编译器:
-fexec-charset=GB2312
-fexec-charset=UTF-8
如果不指定“-fexec-charset”,GCC 就会默认编译出的可执行程序中字符 的编码方式为 UTF-8。 如果“-finput-charset”与“-fexec-charset”不一样,编译器会进行格式转换
2.编码格式实验
下面做实验。
test_charset_ansi.c、test_charset_utf8.c 的编码格式分别为 ANSI、 UTF-8,它们的程序代码是一样的,如下:
01 #include <stdio.h>
02 #include <string.h>
03
04 int main(int argc, char **argv)
05 {
06 char *str = "A 中";
07 int i;
08
09 printf("str's len = %d\n", (int)strlen(str));
10 printf("Hex code: ");
11 for (i = 0; i < strlen(str); i++)
12 {
13 printf("%02x ", (unsigned char)str[i]);
14 }
15 printf("\n");
16 return 0;
17 }默认编码
实验如下:
不指定“-finput-charset”与“-fexec-charset”时,input-charset 和 exec-charset 默认都是 UTF-8,不会进行编码转换。即使 C 文件是 ANSI, 也会被认为是 UTF-8,所以不会导致编码转换。
GB2312 转为 UTF-8
实验如下:
从上面的输出信息可以看出来,GB2312 的“0xd6 0xd0”可以转换为 UTF-8 的“0xe4 0xb8 0xad”。而如果把原本就是 UTF-8 格式的 test_charset_utf8.c 当作 GB2312 格式,会引起错误。
UTF-8 转为 GB2312
实验如下:
从 上 面 的 输 出 信 息 可 以 看 出 来 , 如 果 把 原 本 就 是 GB2312 格式的 test_charset_ansi.c 当作 UTF-8 格式,会引起错误。而 UTF-8 格式的“中”编 码值为“0xe4 0xb8 0xad”,可以转换为 GB2312 的“0xd6 0xd0”。
在代码中使用汉字这类非 ASCII 码时,要特别留意编码格式。
汉字区位码
我们从网上搜到 HZK16 这个文件,它是常用汉字的 16*16 点阵字库。HZK16 里每个汉字使用 32 字节来描述,如图所示:
跟 ASCII 字库一样,每个字节中每一位用来表示一个像素,位值等于 1 时表示对 应像素被点亮,位值等于 0 时表示对应像素被熄灭。
HZK16 中是以 GB2312 编码值来查找点阵的,以“中”字为例,它的编码值 是“0xd6 0xd0”,其中的 0xd6 表示“区码”,表示在哪一个区:第“0xd6 - 0xa1” 区;其中的 0xd0 表示“位码”,表示它是这个区里的哪一个字符:第“0xd0 - 0xa1”个。每一个区有 94 个汉字。区位码从 0xa1 而不是从 0 开始,是为了兼 容 ASCII 码。
所以,我们要显示的“中”字,它的 GB2312 编码是 d6d0,它是 HZK16 里 第“(0xd6-0xa1)*94+(0xd0-0xa1)”个字符。
3.汉字点阵显示实验
打开汉字库文件

第 4787 行打开当前目录的字库文件:HZK16。
第 4793 行获得文件的状态信息,里面含有文件长度,这在后面的 mmap 中 用到。
第 4798 行使用 mmap 映射文件,以后就可以像访问内存一样读取文件内容; mmap 的返回结果保存在 hzkmem 中,它将作为字库的基地址
编写显示汉字的函数
核心函数是 void lcd_put_chinese(int x, int y, unsigned char *str) ,它在 LCD 的(x,y)位置处显示汉字字符 str,str[0]中保存区码、str[1] 中保存位码。
代码如下图所示:
代码分解如下:
第 4734 行确定该汉字属于哪个区;
第 4735 行确实它是该区中哪一个汉字。
第 4736 行确实它的字库地址:每个区中有 94 个汉字,每个汉字在字库中占据 32 字节。
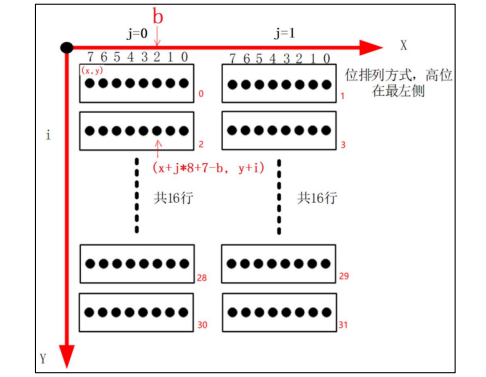
需要根据下图来理解第 4740 行开始的循环:
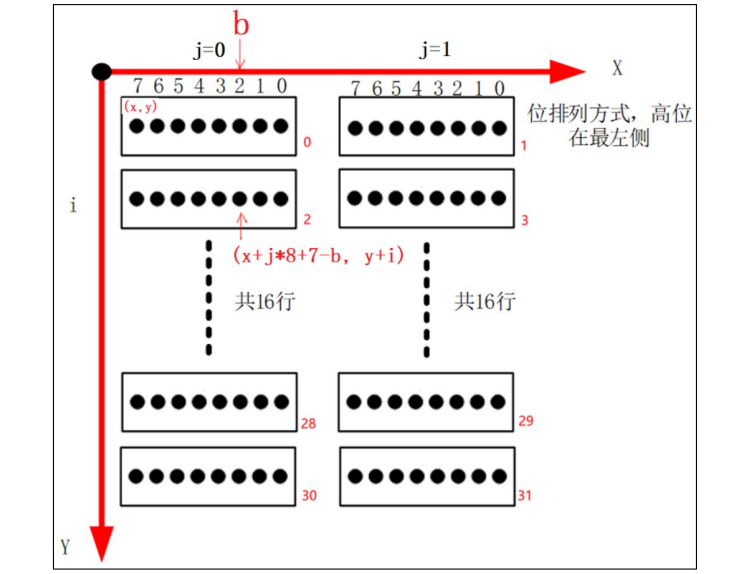
上图是汉字点阵排布的示意图,总共有十六行,因此需要一个循环 16 次的大循环(第 4740 行)。 考虑到一行有两个字节,在大循环中加入一个 2 次的循环用于区分是哪个字 节(第 4741 行)。
最后使用第 3 个循环来处理一个字节中的 8 位(第 4744 行)。
对于每一位,它等于 1 时对应的像素被设置为白色,它等于 0 时对应的像素被设置为黑色。需要注意的是根据 x、y、i、j、b 来计算像素坐标
使用 lcd_put_chinese 函数
程序文件:show_font.c
编译程序
编译命令:
arm-buildroot-linux-gnueabihf-gcc -o show_chinese show_chinese.c
注意:不同的板子,编译工具的前缀可能不一样。
注意:使用上述命令时 show_chinese.c 的编码格式必须是 ANSI(GB2312),否则编译时需要指定“-fexec-charset=GB2312”。
把 show_chinese 程序放到板子上,执行命令:./show_chinese。如果实验成功,我们将看到屏幕中间会显示出一个白色的字母“A”和“中”。