1、消费者和消费者群组(摘自Kafka权威指南)

主题T有4个分区,群组中只有一个消费者,则该消费者将收到主题T1全部4个分区的消息。
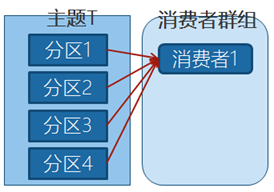
在群组中增加一个消费者2,那么每个消费者将分别从两个分区接收消息,上图中就表现为消费者1接收分区1和分区3的消息,消费者2接收分区2和分区4的消息。
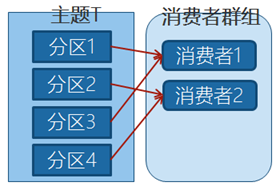
在群组中有4个消费者,那么每个消费者将分别从1个分区接收消息。
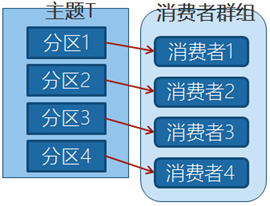
当我们增加更多的消费者,超过了主题的分区数量,就会有一部分的消费者被闲置,不会接收到任何消息。
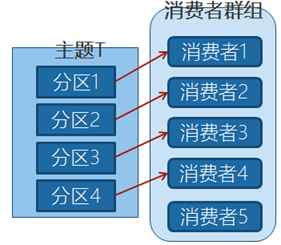
如果新增-一个只包含一个消费者的群组G2,那么这个消费者将从主题T1_上接收所有的消息,与群组G1之间互不影响。群组G2可以增加更多的消费者,每个消费者可以消费若千个分区,就像群组G1那样。

2、消费者群组和分区再均衡
群组里的消费者共同读取主题的分区。一个新的悄费者加入群组时,它读取的是原本由其他消费者读取的消息。当一个消费者被关闭或发生崩愤时,它就离开群组,原本由它读取的分区将由群组里的其他消费者来读取。在主题发生变化时 比如管理员添加了新的分区,会发生分区重分配。
分区的所有权从 个消费者转移到另 个消费者,这样的行为被称为再均衡。再均衡非常重要, 它为 肖费者群组带来了高可用性和伸缩性(我们可以放心地添加或移除梢费者),不过在正常情况下,我们并不希望发生这样的行为。在再均衡期间,消费者无法读取消息,造成整个群组 小段时间的不可用。
3、创建消费者
消费者必要属性:servers地址、key、value的反序列化,因为是消费者群,所以加入group.id 表示当前消费者在哪一个群里面

订阅消息:

4、轮询
消息轮询是消费者 API 的核心,通过 个简单的轮询向服务器请求数据。一旦消费者订阅了主题,轮询就 处理所有的细节,包括群组协调、分区再均衡、发送心跳和获取数据,发者只需要使用 组简单的 API 来处理从分区返回的数据(可以参考代码HelloKafkaConsumer)。

5、消费者配置
ConsumerConfig配置文件
enable.auto.commit
如果 enable.auto.comnit被设为 true,消费者会自动把从poll()方法接收到的最大偏移量提交上去。提交时间间隔由auto.commit.interval.ms控制,默认值是5s。
fetch.min.bytes
每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回。缺省为1个字节。多消费者下,可以设大这个值,以降低broker的工作负载
fetch.wait.max.ms
如果没有足够的数据能够满足fetch.min.bytes,则此项配置是指在应答fetch请求之前,server会阻塞的最大时间。缺省为500个毫秒。和上面的fetch.min.bytes结合起来,要么满足数据的大小,要么满足时间,就看哪个条件先满足。
max.partition.fetch.bytes
指定了服务器从每个分区里返回给消费者的最大字节数,默认1MB。假设一个主题有20个分区和5个消费者,那么每个消费者至少要有4MB的可用内存来接收记录,而且一旦有消费者崩溃,这个内存还需更大。注意,这个参数要比服务器的message.max.bytes更大,否则消费者可能无法读取消息。
session.timeout.ms
如果consumer在这段时间内没有发送心跳信息,则它会被认为挂掉了。默认3秒。
auto.offset.reset
消费者在读取一个没有偏移量的分区或者偏移量无效的情况下,如何处理。默认值是latest,从最新的记录开始读取,另一个值是earliest,表示消费者从起始位置读取分区的记录。
6、提交和偏移量
每次调用 poll () 方法,它总是返回由生产者写入 Kafka 但还没有被消费者读取过的记录我们因此可以追踪到哪些记录是被群组里的哪个消费者读取的。之前已经讨论过, Kafka不会像其 JMS 队列那样需要得到消费者的确认,,这是 Kafka 个独特之处。相反,消费者可以使用 Kafka 来追踪消息在分区里的位置(偏移量)。
6.1、消息丢失(提交的偏移量大于客户处理的最后一个消息偏移量)
当poll拉下来的数据index[4-11],当处理到index[5]时到了commit时间,提交了偏移量11。这时发生了再均衡,及index[6-11]数据丢失。

6.2、消息重复(握交的偏移量小于害户端处理的最后一个消息的偏穆量)
poll拉下来的数据[3-11],还没有到commit的时间,这时发生了再均衡,index[3-10]的数据虽然已经被处理了,但是还没有提交。

7、消息群组的demo
7.1、建立一个分区为2的主题
./kafka-topics.sh --create --zookeeper 192.168.92.39:2181 --replication-factor 1 --partitions 2 --topic consumer-group-test
./kafka-topics.sh --describe --zookeeper 192.168.92.39:2181 --topic consumer-group-test

7.2、 Const:
public class KafkaConsts {
/*==================入门程序=========================*/
public final static String HELLO_TOPIC = "hello.topic";
public final static String HELLO_KEY = "helloKey";
/*=====================线程========================*/
public final static String THREAD_POLL_TOPIC = "thread.pool.topic";
public final static String THREAD_POLL_KEY = "threadPoolKey";
/*=====================vo========================*/
public final static String VO_TOPIC = "vo.topic";
public final static String VO_KEY = "voKey";
/*=====================customer-group========================*/
public final static String CUSTOMER_GROUP_TOPIC = "consumer-group-test";
public final static String CUSTOMER_GROUP_KEY = "customerGroupKey";
public final static String CUSTOMER_GROUP = "customerGroup";
public final static String CUSTOMER_ASYNC_TOPIC = "consumer.async.topic";
public final static String CUSTOMER_ASYNC_GROUP = "consumerAsyncGroup";
public final static String CUSTOMER_ASYNC_KEY = "consumerAsyncKey";
/*=====================rebalance========================*/
public final static String REBALANCE_TOPIC = "rebalance.topic";
public final static String REBALANCE_TOPIC_GROUP = "rebalanceGroup";
public final static String REBALANCE_TOPIC_KEY = "rebalanceKey";
}
7.3、生产者
public class GroupProducer {
public static void main(String[] args) {
//1、获取生产者
KafkaProducer<String, String> producer =
new KafkaProducer<>(KafkaCommonConfig.getProducerProperties(StringSerializer.class, StringSerializer.class));
try {
//2、建立消息
String msg = "hello customer group";
//3、消费者,因为根据key计算出在哪个分区,所以key是需要变化的
for (int i = 1; i <= 50; i++) {
ProducerRecord<String, String> record =
new ProducerRecord<>(KafkaConsts.CUSTOMER_GROUP_TOPIC, KafkaConsts.CUSTOMER_GROUP_KEY + i, msg);
producer.send(record);
}
} finally {
producer.close();
}
}
}
7.4、消费者
把消费者A复制2份,分别为消费者B,消费者C
public class GroupCustomerA {
public static void main(String[] args) {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(KafkaCommonConfig.getCustomerProperties
(KafkaConsts.CUSTOMER_GROUP, StringDeserializer.class, StringDeserializer.class));
try {
consumer.subscribe(Collections.singletonList(KafkaConsts.CUSTOMER_GROUP_TOPIC));
//4、拉取消息
while (true) {
//4.1、500ms拉取一次
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
//4.2、读取消息
for (ConsumerRecord<String, String> record : records) {
System.out.print("主题:" + record.topic());
System.out.print(",分区:" + record.partition());
System.out.print(",偏移量:" + record.offset());
System.out.print(",key:" + record.key());
System.out.print(",value:" + record.value());
System.out.println();
}
}
} finally {
consumer.close();
}
}
}

7.5、启动消费者,生产者。
A和B分摊了消息,C没有收到消息



8、提交方式
8.1、自动提交
最简单的提交方式是让消费者自动提交偏移量。 如果 enable.auto.comnit被设为 true,消费者会自动把从poll()方法接收到的最大偏移量提交上去。提交时间间隔由auto.commit.interval.ms控制,默认值是5s。自动提交是在轮询里进行的,消费者每次在进行轮询时会检査是否该提交偏移量了,如果是,那么就会提交从上一次轮询返回的偏移量。
消息丢失:如果auto.commit.enable=true,当consumer fetch了一些数据但还没有完全处理掉的时候,刚好到commit interval出发了提交offset操作,接着consumer 挂掉了。这时已经fetch的数据还没有处理完成但已经被commit掉,因此没有机会再次被处理,数据丢失。
8.2、消费者手动提交
把auto.commit. offset设为 false,自行决定何时提交偏移量。使用 commitsync()提交偏移量最简单也最可靠。这个方法会提交由poll()方法返回的最新偏移量,提交成功后马上返回,如果提交失败就抛出异常。
生成者:.
public class CommitProducer {
public static void main(String[] args) {
//1、生产者
KafkaProducer<String, String> producer =
new KafkaProducer<>(KafkaCommonConfig.getProducerProperties(StringSerializer.class, StringSerializer.class));
try {
for (int i = 1; i <= 5; i++) {
//2、建立消息
String msg = "hello customer";
ProducerRecord<String, String> record =
new ProducerRecord<>(KafkaConsts.CUSTOMER_ASYNC_TOPIC, KafkaConsts.CUSTOMER_ASYNC_KEY, msg);
//3、发送
producer.send(record);
}
} finally {
producer.close();
}
}
}
8.2、消费者同步提交当前偏移量:
大部分开发者通过控制偏移量提交时间来消除丢失消息的可 性,井在发生再均衡 减少重复消息的数量。消费者 PI 提供了另一种提交偏移量的方式 开发者可 要的时候提交当前偏移盘,而不是基于时间间隔。把enable.auto.commit 设为 false ,让应用程序决定 时提交偏移量。如果发生了再均衡,从最近一批消息到发生再均衡之间的所有消息都将被重复处理。
public class CommitCustomer {
public static void main(String[] args) {
//1、消费者属性
Properties properties
= KafkaCommonConfig.getCustomerProperties(KafkaConsts.CUSTOMER_ASYNC_GROUP, StringDeserializer.class, StringDeserializer.class);
//2、取消自动提交
properties.put("enable.auto.commit", false);
//3、创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
try {
while (true) {
//4、监听
consumer.subscribe(Collections.singletonList(KafkaConsts.CUSTOMER_ASYNC_TOPIC));
//4.1、500ms拉取一次
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
for (ConsumerRecord<String, String> record : records) {
//打印
System.out.println("主题:" + record.topic());
System.out.println("分区:" + record.partition());
System.out.println("偏移量:" + record.offset());
System.out.println("key:" + record.key());
System.out.println("value:" + record.value());
System.out.println("####################################");
//TODO do our work
}
//4.2、提交
consumer.commitSync();
}
} catch (Exception e) {
//TODO 如果报错,记录下来
e.printStackTrace();
}finally {
consumer.close();
}
}
}
8.3、消费者异步提交
手动提交有一个不足之处,在broker对提交请求作出回应之前,应用程序会一直阻塞,这样会限制应用程序的吞吐量。我们可以通过降低提交频率来提升吞吐量,但如果发生了再均衡,会增加重复消息的数量。仅仅修改提交代码。
consumer.commitSync();
commitAsync也支持回调,在 broker 作出响应时会执行回调。回调经常被用于记录提交错误或生成度量指标,
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
//TODO 记录错误信息和偏移量
}
});
8.4、同步异步结合

public class CommitAsync {
public static void main(String[] args) {
//1、消费者属性
Properties properties
= KafkaCommonConfig.getCustomerProperties(KafkaConsts.CUSTOMER_ASYNC_GROUP, StringDeserializer.class, StringDeserializer.class);
//2、取消自动提交
properties.put("enable.auto.commit", false);
//3、创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
try {
while (true) {
//4、监听
consumer.subscribe(Collections.singletonList(KafkaConsts.CUSTOMER_ASYNC_TOPIC));
//4.1、500ms拉取一次
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
for (ConsumerRecord<String, String> record : records) {
//打印
System.out.println("主题:" + record.topic());
System.out.println("分区:" + record.partition());
System.out.println("偏移量:" + record.offset());
System.out.println("key:" + record.key());
System.out.println("value:" + record.value());
System.out.println("####################################");
//do our work
}
//4.2、如果一切正常,那么使用异步提交,提高吞吐量
consumer.commitAsync();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//在关闭消费者之前,使用同步阻塞方式提交当前偏移量
consumer.commitSync();
} finally {
consumer.close();
}
}
}
}
8.5、特定提交
如果poll()方法返回一大批数据,为了避免因再均衡引起的重复处理整批消息,想要在批次中间提交偏移量该怎么办?这种情况无法通过调用 commitSync()或 commitAsync()来实现,因为它们只会提交最后一个偏移量,而此时该批次里的消息还没有处理完。


demo:
生产者:
public class CommitProducer {
public static void main(String[] args) {
//1、获取生产者
KafkaProducer<String, String> producer =
new KafkaProducer<>(KafkaCommonConfig.getProducerProperties(StringSerializer.class, StringSerializer.class));
try {
//2、建立消息
String msg = "hello customer";
for (int i=1;i<=50;i++){
ProducerRecord<String, String> record =
new ProducerRecord<>(KafkaConsts.CUSTOMER_ASYNC_TOPIC, KafkaConsts.CUSTOMER_ASYNC_KEY, msg);
//3、发送
producer.send(record);
}
} finally {
producer.close();
}
}
}
消费者:
public class CommitAsync {
public static void main(String[] args) {
//1、消费者属性
Properties properties
= KafkaCommonConfig.getCustomerProperties(KafkaConsts.CUSTOMER_ASYNC_GROUP, StringDeserializer.class, StringDeserializer.class);
//2、取消自动提交
properties.put("enable.auto.commit", false);
//3、定义批量提交的Map
Map<TopicPartition, OffsetAndMetadata> currOffsets = new HashMap<>();
int countIndex = 0;
//4、创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
try {
while (true) {
//4、监听
consumer.subscribe(Collections.singletonList(KafkaConsts.CUSTOMER_ASYNC_TOPIC));
//4.1、500ms拉取一次
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
for (ConsumerRecord<String, String> record : records) {
//打印
System.out.print("主题:" + record.topic());
System.out.print(",分区:" + record.partition());
System.out.print(",偏移量:" + record.offset());
System.out.print(",key:" + record.key());
System.out.println(",value:" + record.value());
//do our work
//4.2、在读取每条记录之后,使用期望处理的下一个消息的偏移量更新map里的偏移量
currOffsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, "no meta"));
//4.3、5条提交一次
if (++countIndex % 5 == 0) {
consumer.commitAsync(currOffsets, null);
System.out.println("################发生提交####################");
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}
}
}

9、在均衡监听器
在提交偏移量中提到过,消费者在退出和进行分区再均衡之前,会做一些清理工作你会在消费者失去对 一个分区的所有权之前提交最后一个已处理记录的偏移量。
在均衡监听器,在调用订阅(subscribe)时传入一个ConsumerRebalanceListener实例:
/**
* @Description 在均衡监听器
*/
public class HandleRebalance implements ConsumerRebalanceListener {
/**
* 主题分区,偏移量
*/
private Map<TopicPartition, OffsetAndMetadata> currentOffsets;
/**
* 消费者
*/
private KafkaConsumer<String, String> consumer;
public HandleRebalance(Map<TopicPartition, OffsetAndMetadata> currOffsets,
KafkaConsumer<String, String> consumer) {
this.currentOffsets = currOffsets;
this.consumer = consumer;
}
/**
* 方怯会在再均衡开始之前和消费者停止读取消息之后被调用。如果在这里提交偏移量,
* 下一个接管分区的消费者就知道该从哪里开始读取了。
*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
String id = Thread.currentThread().getId() + "";
System.out.println(id + "-onPartitionsRevoked参数值为:" + partitions);
System.out.println("分区偏移量表中:" + currentOffsets);
consumer.commitSync(currentOffsets);
System.out.println("#############################");
}
/**
* 方法会在重新分配分区之后和消费者开始读取消息之前被调用。
*/
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
final String id = Thread.currentThread().getId() + "";
System.out.println(id + "-再均衡完成,onPartitionsAssigned参数值为:" + partitions);
System.out.println("分区偏移量表中:" + currentOffsets);
System.out.println("#############################");
}
}
9.1、建立分区
./kafka-topics.sh --create --zookeeper 192.168.43.38:2181 --replication-factor 1 --partitions 2 --topic rebalance.topic
./kafka-topics.sh --describe --zookeeper 192.168.43.38:2181 --topic rebalance.topic

9.2、生产者
public class Provider {
public static void main(String[] args) {
//1、获取生产者
KafkaProducer<String, String> producer =
new KafkaProducer<>(KafkaCommonConfig.getProducerProperties(StringSerializer.class, StringSerializer.class));
try {
//2、建立消息
for (int i = 1; i <= 1000; i++) {
String msg = "hello kafka future";
ProducerRecord<String, String> record =
new ProducerRecord<>(KafkaConsts.REBALANCE_TOPIC, KafkaConsts.REBALANCE_TOPIC_KEY + i, msg);
producer.send(record);
Thread.sleep(200);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
}
}
9.3、消费者
public class Customer {
private static CountDownLatch countDownLatch = new CountDownLatch(1);
static class workerHandler implements Runnable {
//消费者实例
private KafkaConsumer<String, String> consumer;
//主题分区,偏移量
private Map<TopicPartition, OffsetAndMetadata> currOffsets;
public workerHandler() {
//1、配置消费者
Properties properties =
KafkaCommonConfig.getCustomerProperties(KafkaConsts.REBALANCE_TOPIC_GROUP, StringDeserializer.class, StringDeserializer.class);
//2、关闭自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
//3、新建消费者 ,偏移量
this.consumer = new KafkaConsumer<>(properties);
this.currOffsets = new HashMap<>();
//4、订阅、再均衡监听器
consumer.subscribe(Collections.singletonList(KafkaConsts.REBALANCE_TOPIC),
new HandleRebalance(currOffsets, consumer));
}
@Override
public void run() {
try {
while (true) {
//50ms拉取一次
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.print("主题:" + record.topic()+",");
System.out.print("分区:" + record.partition()+",");
System.out.print("偏移量:" + record.offset()+",");
System.out.print("key:" + record.key()+",");
System.out.print("value:" + record.value());
System.out.println("");
//创建主题分区
TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(record.offset() + 1);
currOffsets.put(topicPartition, offsetAndMetadata);
}
consumer.commitAsync(currOffsets, null);
}
} catch (Exception e) {
//TODO 记录异常
} finally {
try {
consumer.commitSync(currOffsets);
} finally {
consumer.close();
}
}
}
}
public static void main(String[] args) {
Thread t1 = new Thread(new workerHandler());
Thread t2 = new Thread(new workerHandler());
t1.start();
t2.start();
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.interrupt();
System.out.println("t2 停止");
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
运行消费者,运行生成者:



