上节课我们一起学习了MapReduce大的框架及原理,单看理论的话很容易懵圈,这节我们便一起学习一个MapReduce的简单例子,通过例子来理解原理从来都是最好的学习方法。
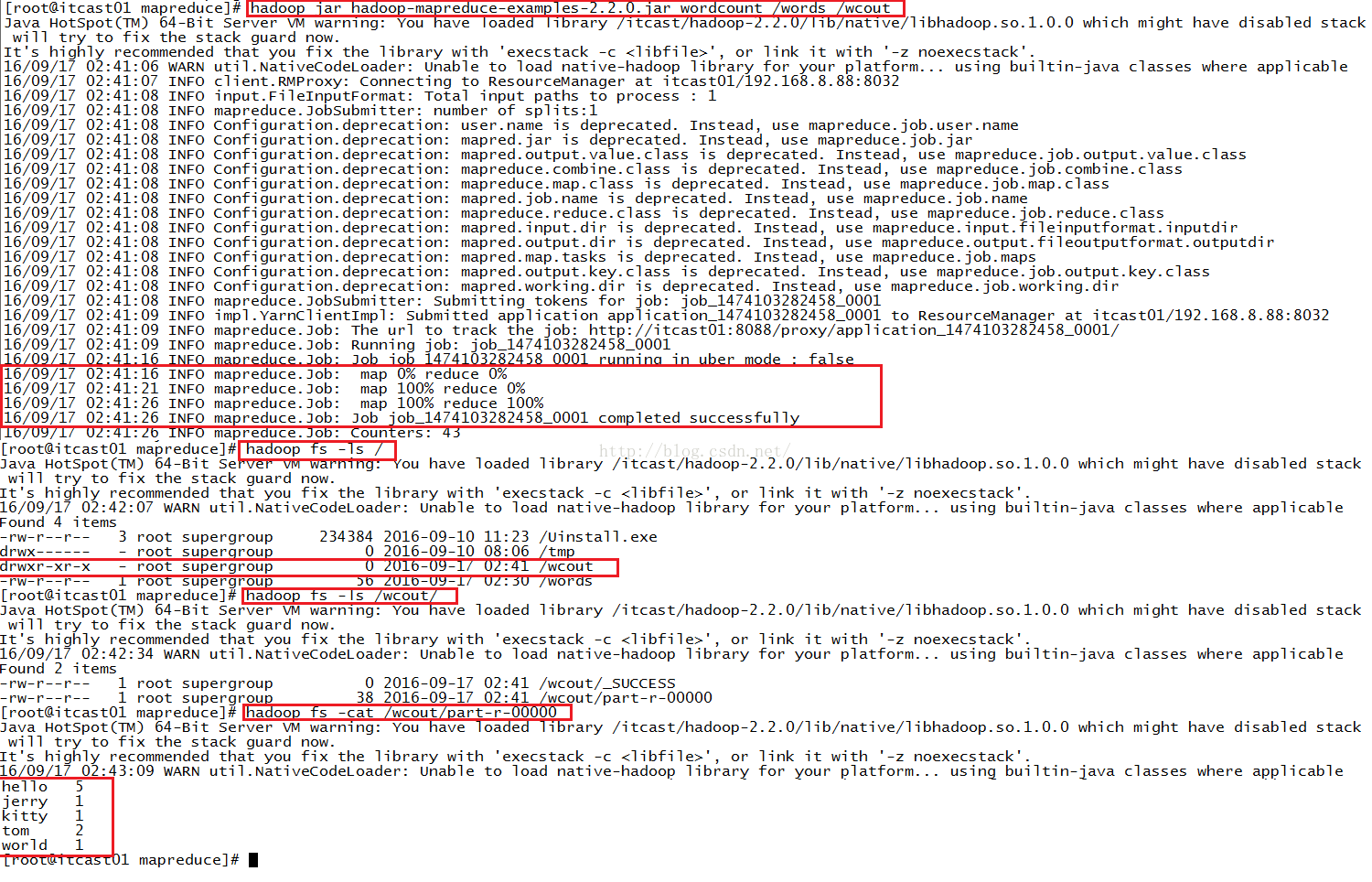
首先我们来简单操作一个入门级的例子,就是统计一下某个文件当中的每个单词出现的次数。我们在mapreduce目录下有一个words文件,如下图红色圈住的内容,在words文件当中我们看到如下图所示的内容(查看命令是more words),为了不让原来的操作影响我们本次操作的结果,我把我HDFS系统根目录下原来的words文件和结果文件都删除掉了(您的HDFS系统的根目录下默认是没有这两个文件的,没有就不用进行删除操作),删除的命令是:hadoop fs -rm -r /words、hadoop fs -rm -r /wcout。等删除完之后我们再来查看一下HDFS系统根目录下的文件列表,发现没有words文件和wcout文件,如下图。

接下来我们便把words文件上传到HDFS系统根目录下,上传的命令是:hadoop fs -put words /words(注意路径,由于我在本地words所在的路径下操作的,因此直接写的就是words,如果在别的目录下执行上传命令一定要注意words文件所在的位置)。上传完之后我们来看一下HDFS系统根目录下当前的文件列表,发现多了一个words文件,如下图所示。

接下来我们该执行wordcount命令了,如下图所示,执行的命令是:hadoop jar hadoop-examples-2.2.0.jar wordcount /words /wcout,其中hadoop-examples-2.2.0.jar是Hadoop给我们自带的很多例子的jar包,我们用到了其中的wordcount的命令,/words文件代表输入,/wcout文件代表输出,两个文件都在HDFS系统根目录下。执行成功之后我们再来看一下HDFS系统根目录下的文件列表,发现多了一个wcout文件,如下图所示。我们再进入这个wcout文件夹当中看里面都有哪些东西,查看的命令是:hadoop fs -ls /wcout/,我们发现它的里面有两个文件,其中/wcout/part-r-00000这个文件中保存了我们计算的结果。我们再具体看看这个part-r-00000文件当中的具体内容是什么,我们使用命令hadoop fs -cat /wcout/part-r-00000,发现这个文件里面记录着每个单词出现的次数,如下图所示。我们发现我们这个例子完全正确。
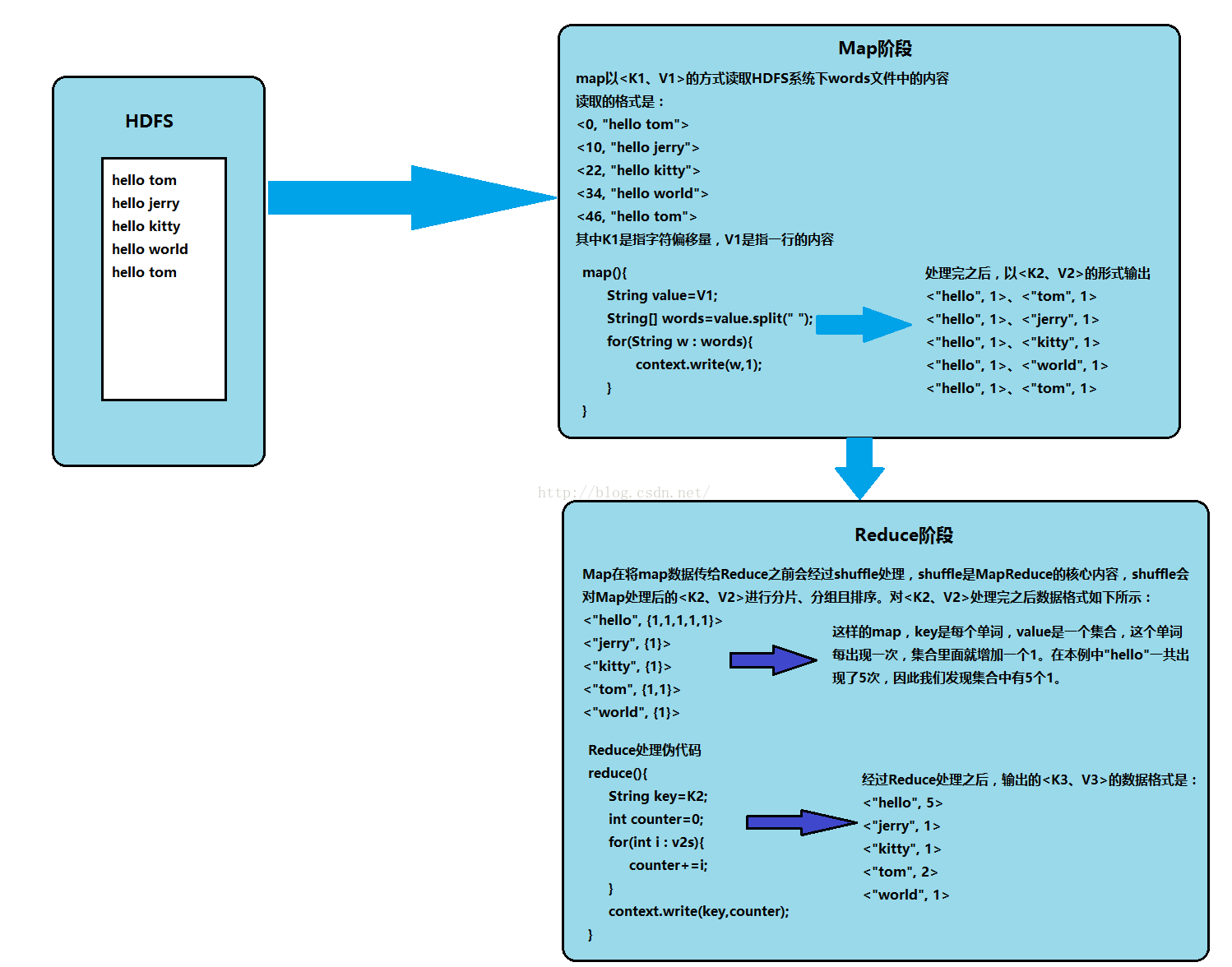
上面我们手工操作了一遍关于统计单词数量的例子,下面我们来通过图例的形式来看一下运行流程(如下图所示)。
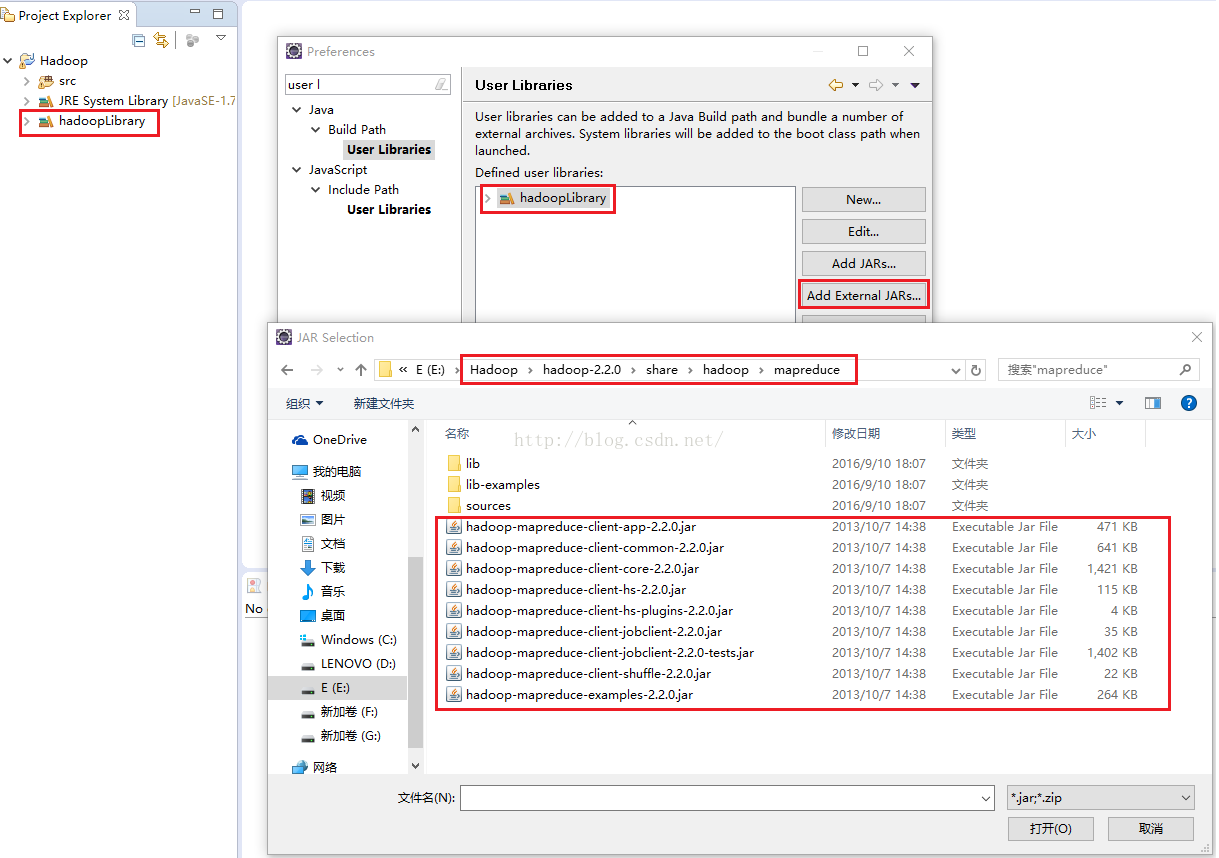
接下来我们便正式开始用代码来跑一下这个例子,首先我们需要导入MapReduce所需要的jar包,当然在之前我们已经导入了hadoop所需的jar包和common的jar包,具体请参考:http://blog.csdn.net/u012453843/article/details/52487499这节课。如下图所示。
导入jar包后,我们开始写代码,首先我粘出来我们自己实现的Mapper类
package com.myhadoop.mr;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 定义一个Mapper类,该类继承自Hadoop的Mapper类,Mapper类有4个泛型,分别代表
* KEYIN(K1)、VALUEIN(V1)、KEYOUT(K2)、VALEOUT(V2),其中<K1,V1>的数据如:
* <0, "hello tom">,<K2,V2>的数据如:<"hello", 1>。Mapper的这4个泛型一定要实现
* 序列化,这样方便快速传输。Hadoop所用的序列化与jdk所用的序列化是不一样的,因为
* jdk的序列化机制非常冗余(需要保存类之间的关系等),因此Hadoop实现了自己的一套序
* 列化机制,其中数值型的数据可以用LongWritable来序列化,字符串型的数据可以用Text
* 来序列化。我们发现K1是数值类型,因此它的序列化泛型是LongWritable,V1是字符串因
* 此它的序列化泛型是Text,K2是字符串类型,因此它的序列化泛型是Text,V2是数值类型
* 因此它的序列化泛型是LongWritable。
*
* @author
*
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
//需要重写map方法
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
//接收数据V1
String line = value.toString();
//切分数据
String[] words = line.split(" ");
//循环输出word
for(String word : words){
//由于word是String类型数据,没有序列化,因此在写出去之前先序列化。
//1是int类型,没有序列化,因此要序列化。
context.write(new Text(word), new LongWritable(1));
}
}
}
package com.myhadoop.mr;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WCReduce extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> v2s,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//定义一个counter用来统计某个单词出现的次数是多少
long counter=0;
//其实v2s当中存储的都是一个个被序列化好了的1
for(LongWritable i : v2s){
counter+=i.get();//跟我们熟悉的counter++是一个意思
}
//输出<K3、V3>,比如<"hello", 5>
context.write(key, new LongWritable(counter));
}
}
最后我粘出程序的入口类WordCount的代码
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
//我们已经自定义好了Mapper和RedUC而现在我们要做的就是把MapReduce作业提交上去
//现在我们把MapReduce作业抽象成Job对象了
Job job = Job.getInstance(new Configuration());
//注意:一定要将main方法所在的类设置进来。
job.setJarByClass(WordCount.class);
//接下来我们设置一下Job的Mapper相关属性
job.setMapperClass(WCMapper.class);//设置Mapper类
job.setMapOutputKeyClass(Text.class);//设置K2的类型
job.setMapOutputValueClass(LongWritable.class);//设置V2的类型
//接下来我们得告诉程序我们应该去哪里读取文件。需要注意的是Path是指在Hadoop的HDFS系统上的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));//这里我们采用变量的形式传进来地址
//接下来我们来设置一下Job的Reducer相关属性
job.setReducerClass(WCReduce.class);//设置Reducer类
job.setOutputKeyClass(Text.class);//设置K3的类型
job.setOutputValueClass(LongWritable.class);//设置V3的类型
//接下来我们得告诉程序应该把结果信息写到什么位置。注意:这里的Path依然是指文件在Hadoop的HDFS系统
//上的路径。
FileOutputFormat.setOutputPath(job, new Path(args[1]));//我们依然采用变量的形式传进来输出地址。
job.waitForCompletion(true);//把作业提交并且等待执行完成,参数为true的话,会打印进度和详情。
}
}
写完了代码我们就该打包我们写的程序了,打包的过程如下,首先在Hadoop项目上右键,在下拉菜单中点击“Export”
点击“Export”后进入如下图所示的界面,我们点击展开Java目录,我们选择JAR file,然后点击“Next”

点击“Next”之后我们进入如下图所示界面,我们勾选上Hadoop前面的复选框,点击“Browser”,我们选择把即将生成的jar包存放到Windows的哪个目录下,这里我把它放到了F盘根目录下,命名完毕之后点击“保存”,如下图所示。
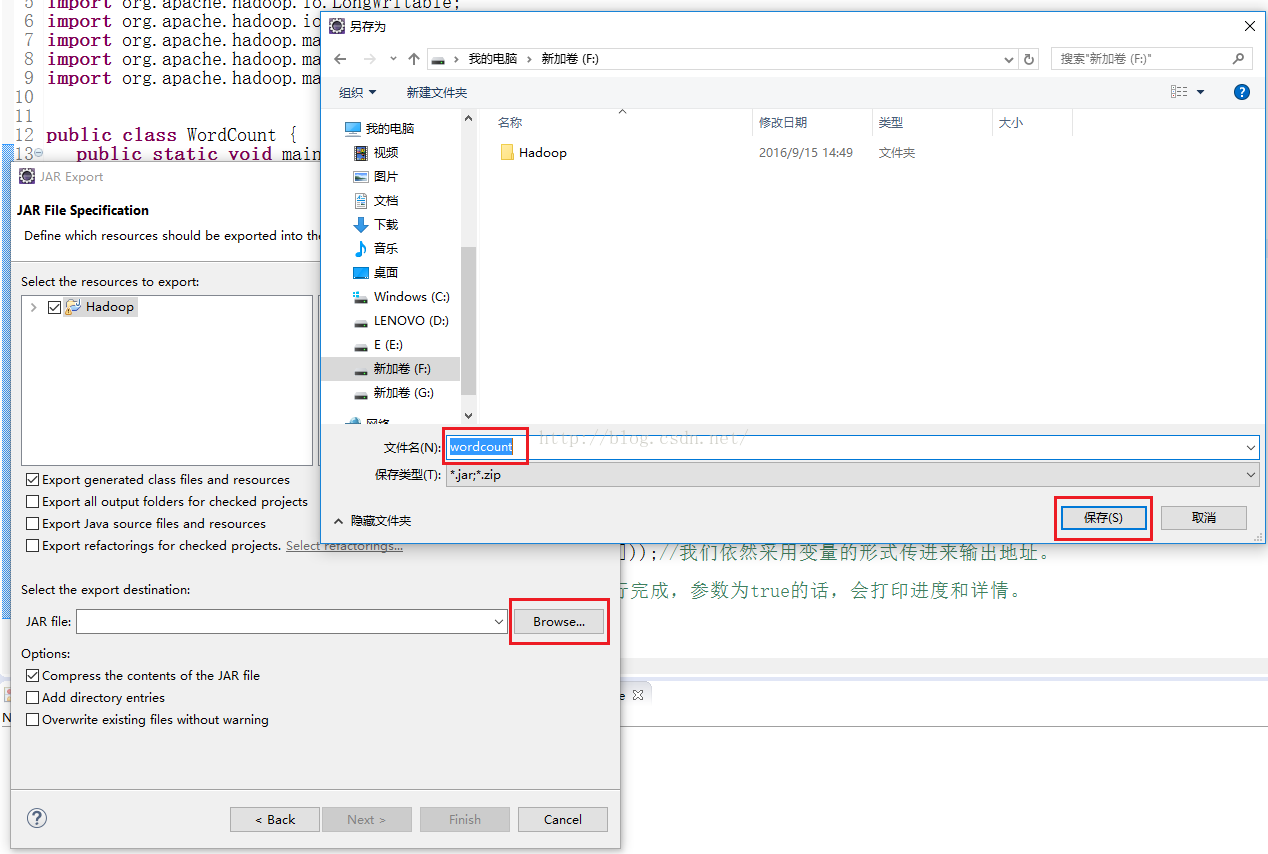
命名完毕后我们回到如下图所示的界面,我们直接点击“Finish”即可。
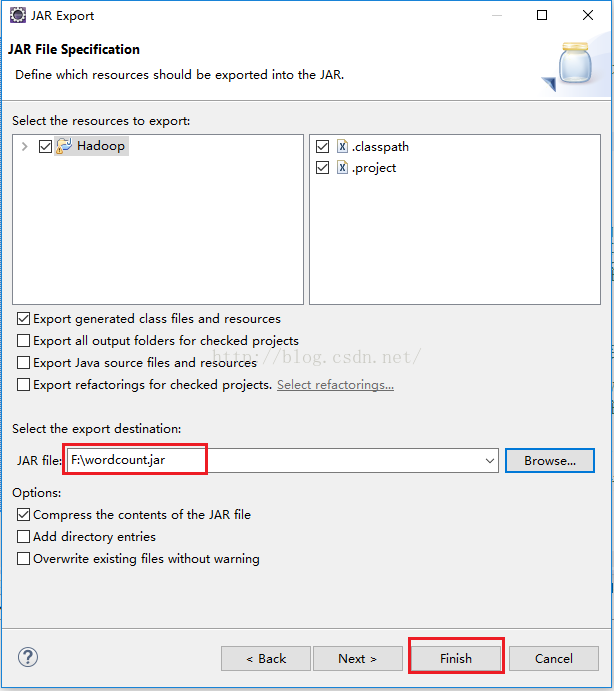
我们刚才生成的jar包有没有成功呢?我们到F盘根目录下看看,如下图所示,我们发现确实有wordcount.jar这个文件
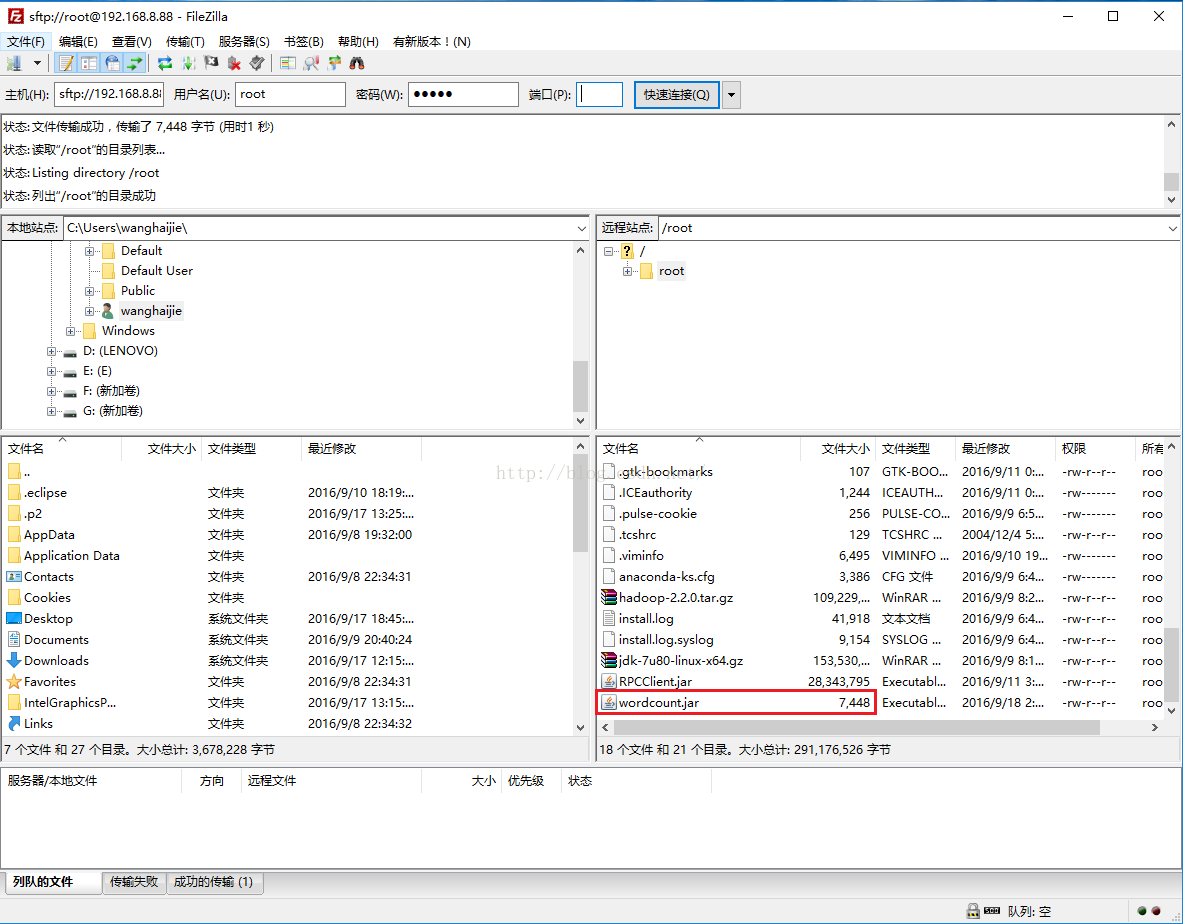
因为Windows系统上没有运行该jar包的相关环境,因此我们需要把该jar文件上传到Linux系统上,这里我们通过使用FileZilla工具把它上传到root根目录下,如下图所示,如果不会使用FileZilla工具请参考:http://blog.csdn.net/u012453843/article/details/52422736这节课进行学习。
上传到root根目录下后我们再来通过命令的方式查看一下,如下图所示,发现在root根目录下确实有wordcount.jar这个文件。

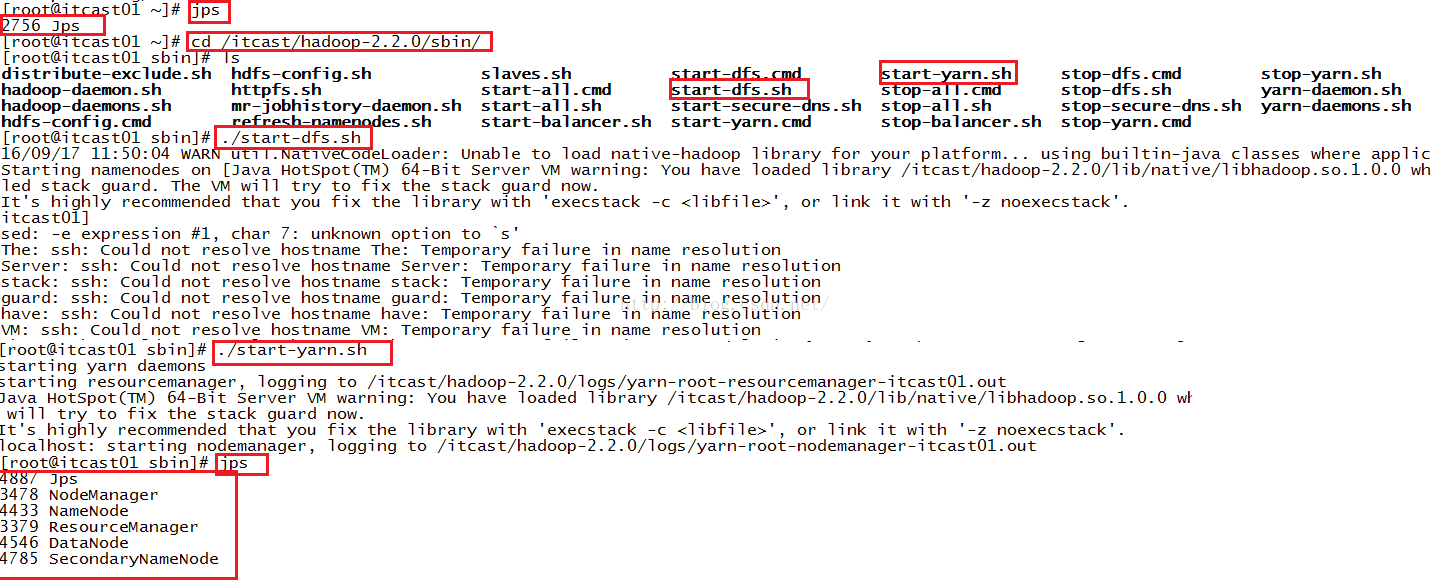
接下来我们需要查看一下,HDFS和Yarn服务是否已经启动,我们使用命令jps来查看进程快照,发现只有2756这一个进程,说明还没启动hdfs和yarn,因此我们需要启动它们,我们进入到/itcast/hadoop-2.2.0/sbin/目录下,该目录下有启动hdfs和yarn的脚本,我们使用命令./start-dfs.sh和./start-yarn.sh来分别启动hdfs和yarn进程,启动完毕之后我们再次使用命令jps来查看进程快照,发现这时进程包括Jps、NodeManager、NameNode、ResourceManager、DataNode、SecondaryNameNode,这说明服务都启动成功了,如下图所示。
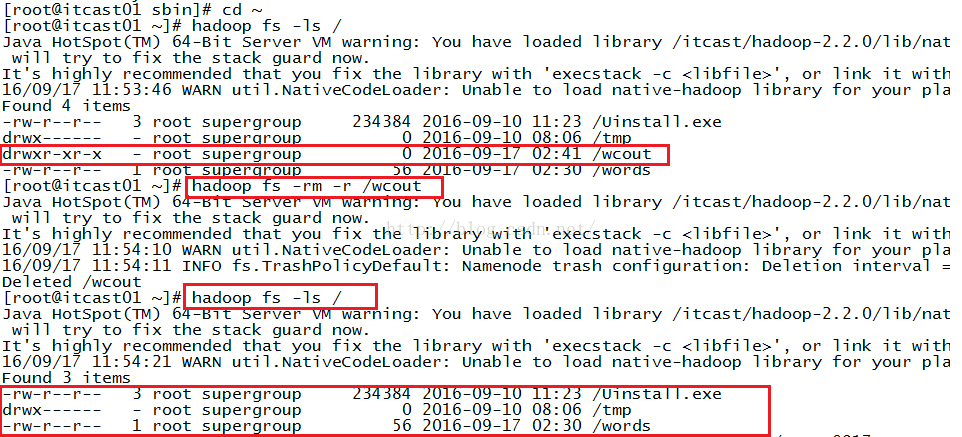
接下来我们来看一下在HDFS系统根目录下是否已经有我们以前生成的结果文件,我们使用命令:hadoop fs -ls /来查看,发现这个根目录下确实有一个wcout文件,我们为了避免它给我们造成干扰,我们先把它删掉,删除使用的命令是hadoop fs -rm -r /wcout,删除完之后我们再查看一下是否还存在wcout这个文件,发现这个文件已经被成功删除了!如下图所示
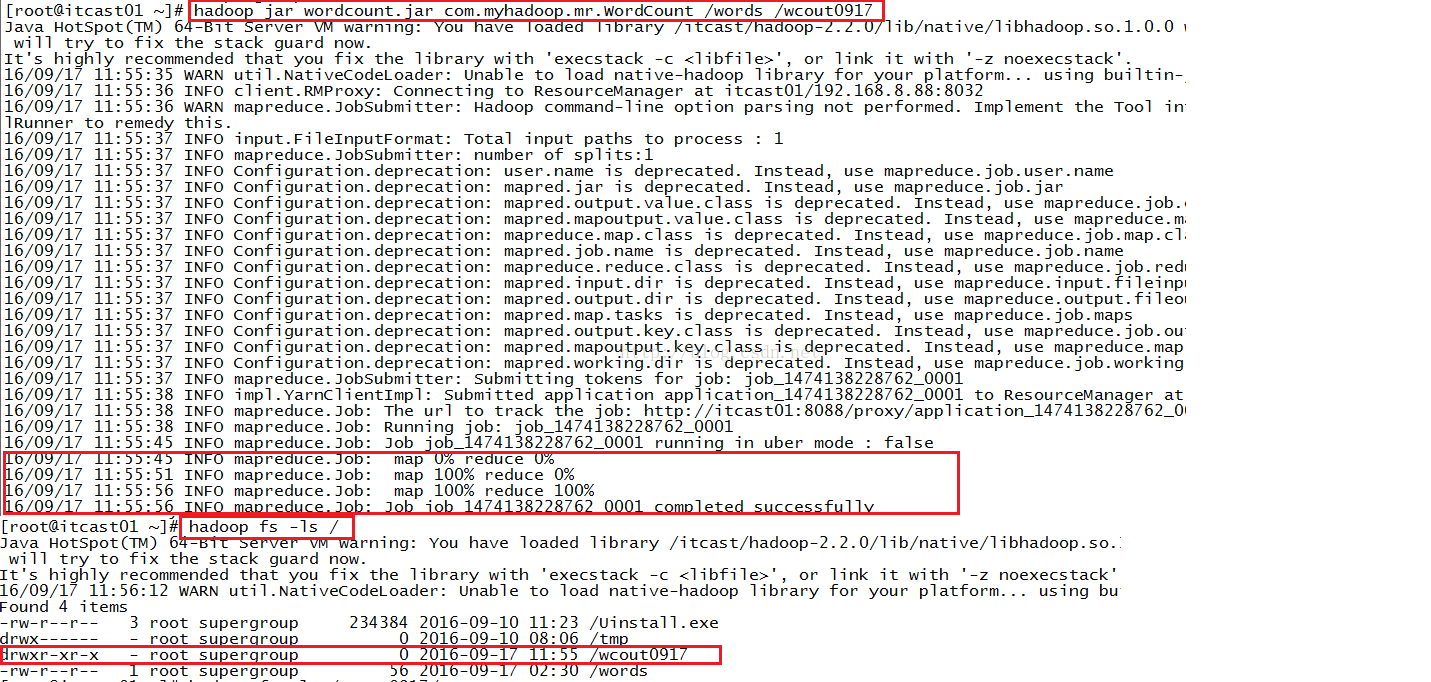
接下来我们开始执行我们刚才打包的jar文件了,我们使用命令:hadoop jar wordcount.jar com.myhadoop.mr.WordCount /words /wcout0917,我来解释一下这条命令的意思,hadoop jar是专门用来执行jar包的,wordcount.jar就是我们打包的jar,com.myhadoop.mr.WordCount是包名加上Main方法所在的类名,告诉执行者Main方法所在的位置,/words是HDFS系统根目录下的一个文件,这个文件是我们要统计的文件,告诉程序应该从哪里读取数据,/wcout0917的意思是告诉程序要把执行结果放到HDFS系统根目录下的wcout0917这个文件夹里,wcout0917是我随意起的一个名字。执行完之后,我们通过命令hadoop fs -ls /来查看HDFS根目录下是否生成了我们刚才命名的wcout0917文件,经检查确实如此,如下图所示。
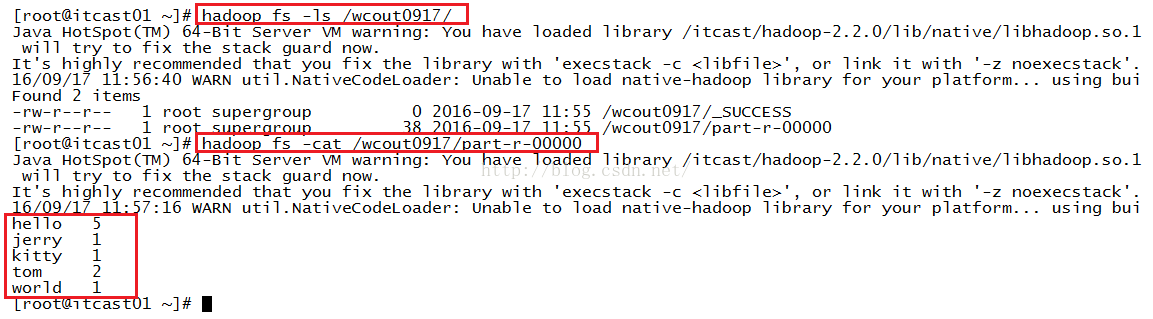
接着我们进入到/wcout0917这个文件夹下,看里面都有哪些文件,我们使用命令:hadoop fs -ls /wcout0917/来查看,发现有两个文件,我们进一步查看part-r-00000这个文件的内容,使用命令:hadoop fs -cat /wcout0917/part-r-00000,我们发现确实计算出了正确的结果!如下图所示。
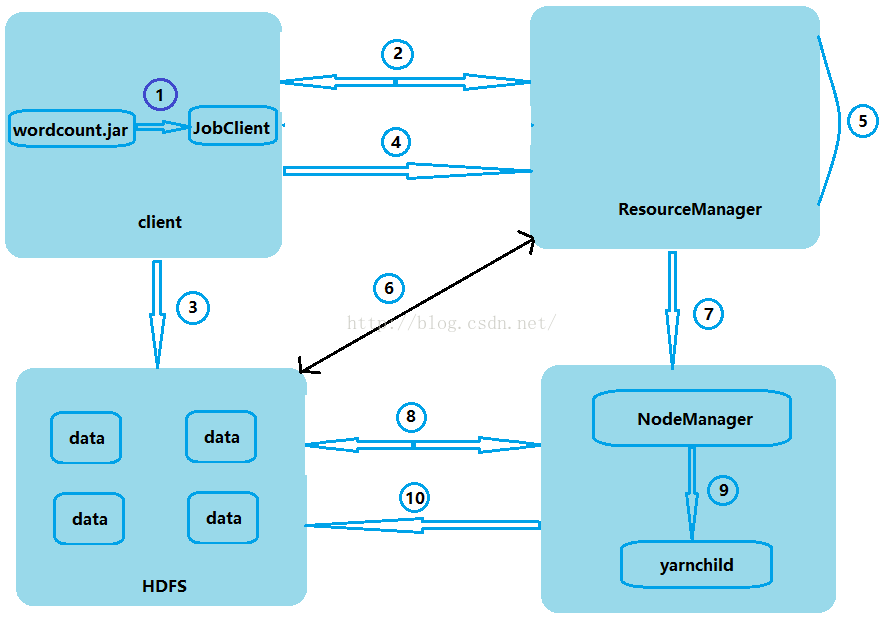
上面我们具体用代码操作了一个具体的小例子,那么我们接下来看一下工作原理图。
第1步:当我们执行hadoop jar wordcount.jar com.myhadoop.mr.WordCount /words /wcout0917这条命令时,会启动一个Job任务,该任务会被交给JobClient处理。
第2步:JobClient会通过RPC协议得到了ResourceManager的一个代理对象,然后开始与ResourceManager进行通信,JobClient会把JobID交给ResourceManager,ResourceManager会返回给JobClient一个地址的前缀,JobClient会把这个地址前缀拼接上JobID做为文件要存放的路径(拼接JobID的目的是为了防止地址重复)。
第3步:Client会使用FileSystem把数据写到HDFS系统上的这个拼接好的地址。
第4步:JobClient再把刚才数据存放的路径和JobID等描述信息传给ResourceManager,ResourceManager会把这些描述信息记录下来。
第5步:ResourceManager把接收的信息进行初始化并且把它们放到自己的任务调度器当中。
第6步:ResourceManager要看这个数据有多大,根据数据的大小来决定起多少个Mapper和多少个Reducer
第7步:NodeManager与ResourceManager通过心跳机制进行通信,NodeManager会向ResourceManager申请任务。
第8步:NodeManager申请到任务之后,便会到HDFS系统下载相应的jar包。
第9步:NodeManager下载完jar包之后,它会另外起一个java进程(yarnchild)来处理,在这个进程中有Mapper和Reducer
第10步:Reducer把数据都处理完之后,再把结果重新再写到HDFS系统上。
至此,本小节我们便一起学习完了。