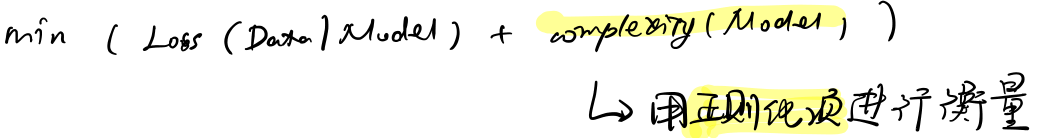简化正则化 Regularization for Simplicity
为了简化而进行的正则化。
正则化:降低模型的复杂度以减少过拟合的方法。
先理解正则化的意义:依据不要过于信赖样本的原则。
训练集具有独特扰动和特殊性。(类比学习语言的时候如果完全学习一个人的说话方式,则会不经意学到很多口癖)
正则化的方法有:
1、及时停止(难度较大,不易把握)
2、对模型复杂度进行惩罚(使模型不会无限制复杂化),采用L2正则化
L2正则化具体做法:
·复杂度(模型) = 权重的平方和
·减少非常大的权重
·对于线性概率,首选比较平缓的斜率
·贝叶斯先行概率:权重应以0为中心并且呈正态分布
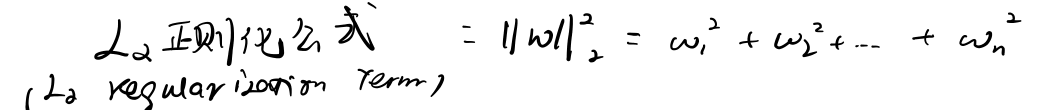
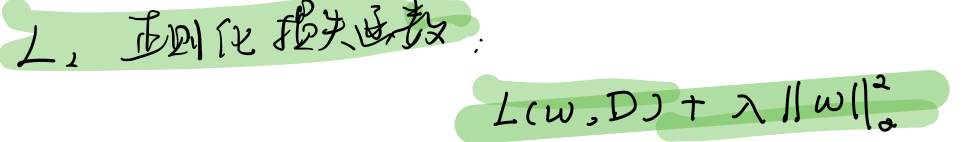
L:旨在减少训练误差
lambda:表示正则化率,是控制如何平衡权重的标量值,用来描述模型复杂度
deta:平衡复杂度
上下2次:权重标准化的平方
lambda * 正则化项 = lambda * complexity(Model) 来调整正则化项的整体影响
lambda值高则模型简单
lambda值低则模型复杂,lambda=0时完全取消正则化->训练的唯一目的只是最小化损失->同时过拟合风险达到最高
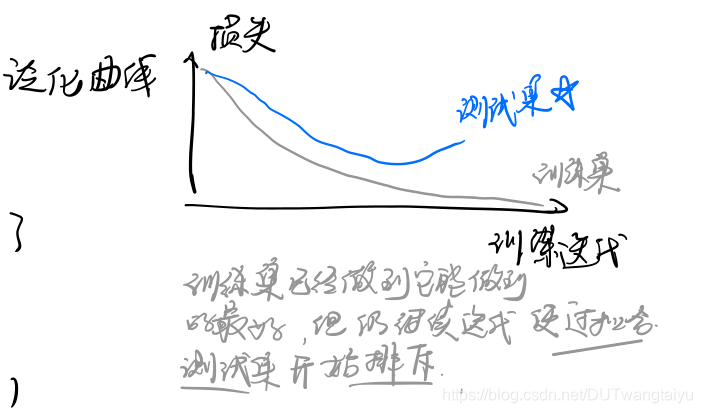
正则化适用情况:
训练数据不多,或者训练数据与测试数据有所不同,则可能需要利用交叉验证或使用单独的测试集进行调整。
目标:结构,风险最小化。