编译器中的实现细节
我们在总结Hive架构的时候,我们知道Hive中有一个Compiler组件,这个组件主要是解析字符串的SQL,然后生成执行计划,我们介绍文章主要是详细讲解Compiler中的细节以及生成的执行计划
我们从下面的HiveSQL语句开始:
use douban;
-- 创建一张临时表
CREATE TABLE `douban.movie_temp`(
`movieid` string,
`moviename` string,
`url` string)
STORED AS TEXTFILE;
然后使用HiveQL进行数据的引入:
– 将movie和movie_links中关联后的字段写到movie_temp中
insert overwrite table movie_temp
select a.movieId, a.moviename, b.url from movie a join movie_links b on a.movieId = b.movieId;
当Hive的编译器接收到上面的HiveQL后,做的第一件事就是将上面的字符串HiveQL解析成抽象语法树(AST),下图就是根据上面HiveQL中的关键字解析成的AST:

有了AST后,然后对AST进行语义分析,然后转换成Hive 内部查询结构(查询块),然后将每一个查询块转换成对应的操作(操作员),如下图:
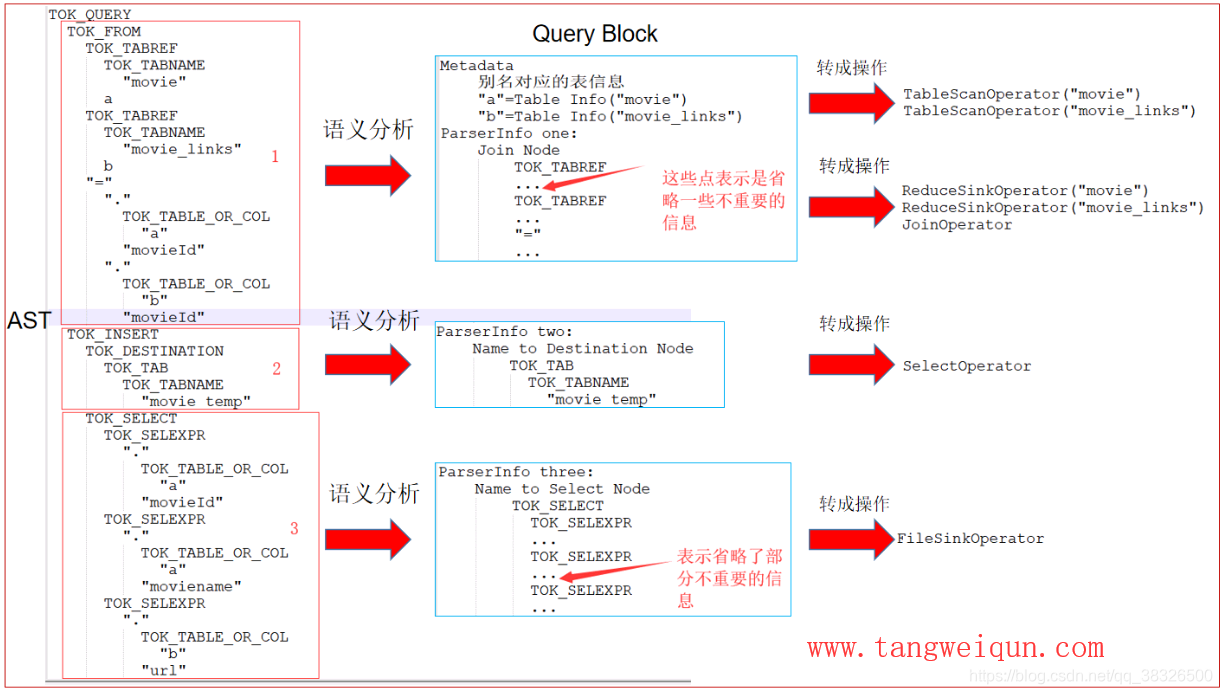
我们分别对最后的所有的Operator做一个解释:
TableScanOperator:扫描指定表的数据的操作
ReduceSinkOperator:将数据发送给reduce任务的操作
JoinOperator:两张表进行Join的操作
SelectOperator:查询指定细分的操作
FileSinkOperator:写文件的操作
有了对应的Operator后,然后Compiler合并所有的Operator按照执行顺序组成一棵操作树(Operator Tree),也就是我们常说的逻辑执行计划了,如下图:

TS是TableScanOperator的缩写,RS是ReduceSinkOperator的缩写,其他的缩写单词也是一样
生成的上面的逻辑执行计划不一定是最优的,说白了,如果是按照上面的执行计划生成的任务,然后执行的性能不是最好的,这个时候就需要优化器来给上面的逻辑执行计划进行优化了,我们这里以优化器中最常见的一种优化手段来Predicate PushDown(谓词下推)模拟,然后是,假设给上面的HiveQL加上一个过滤条件,SQL如下:
insert overwrite table movie_temp
select a.movieId, a.moviename, b.url from movie a join movie_links b on a.movieId = b.movieId where b.url like "%https%";
当编译器接收到这条HiveQL后,如果不做任何优化的话,那么生成的逻辑执行计划应该如下图:
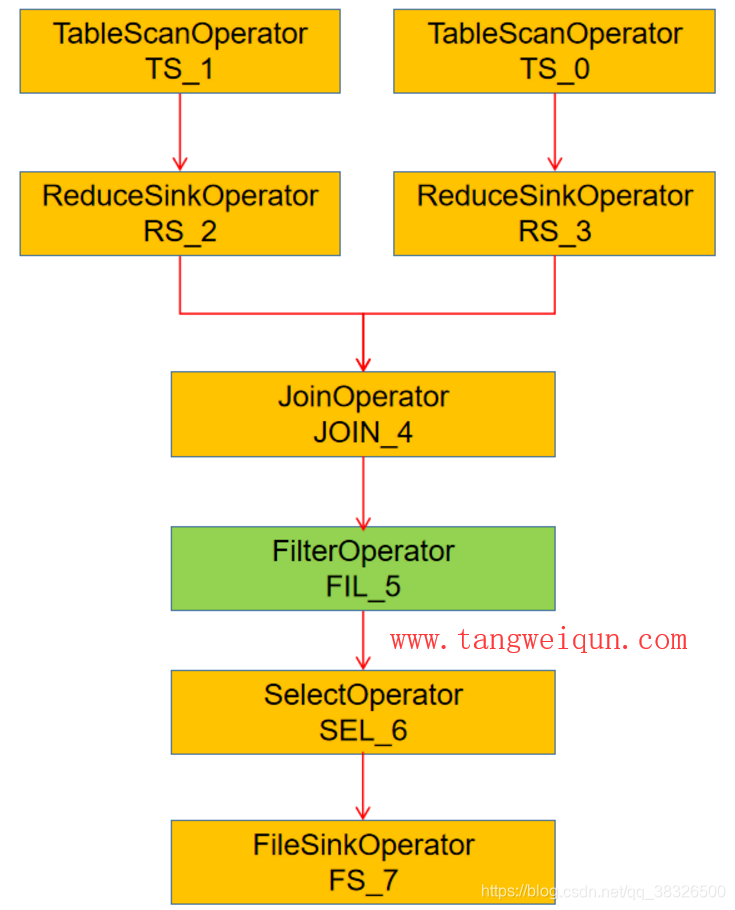
可以抛光,就是当执行完Join操作完后,再开始执行filter(即执行where条件过滤),但是这样不是最优的,那么当优化器给这个逻辑执行计划进行优化后的逻辑执行计划如下图:
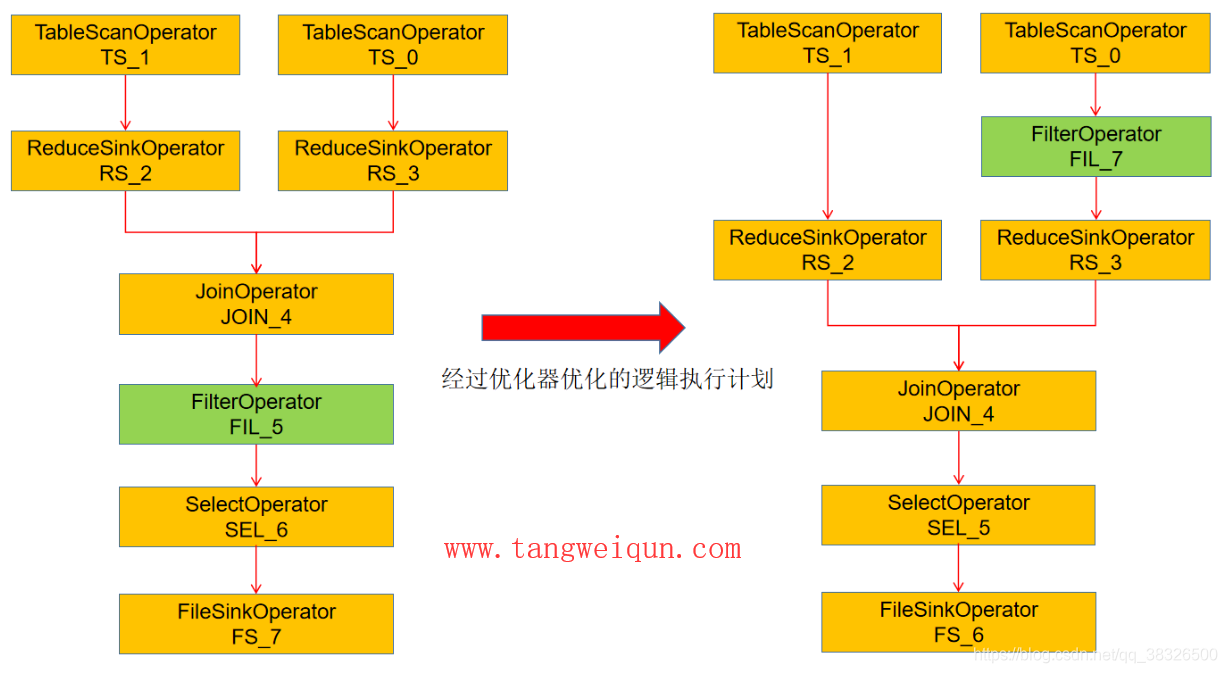
那么优化后的逻辑执行计划就是在Join之前就进行了过滤了,这样在Join的时候数据量就会减少,可以提高执行性能了,这个就是Predicate PushDown(谓词下推)的优化了。
优化后的逻辑执行计划会被转化成物理执行计划了,也就是真正的 Map / Reduce Task了,如下图:
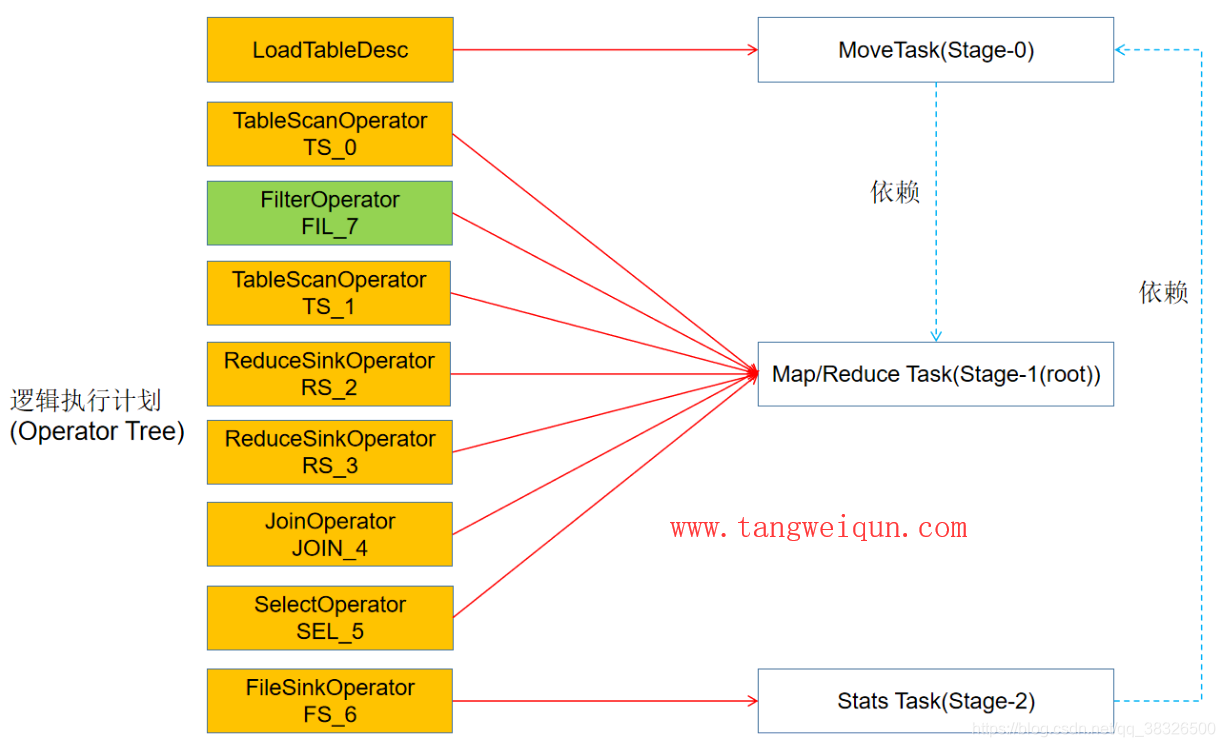
从上图,我们可以看到,Hive将上面的HiveQL生成的逻辑执行计划转换为3个stage的DAG,其中stage-1是根stage,stage-0依赖于stage1,stage-2依赖于stage-0。所以执行的顺序肯定是:stage-1 –> stage-0 –> stage-2
stage-1中就是地图/减少任务了,也就是执行上面HiveQL中的扫描表,然后过滤器,然后加入操作了,最后选择出想要的位移的值,这些操作都是在一个MapReduce工作中完成的,看下图就知道一些操作在Mapper完成,其中操作在Reducer操作:
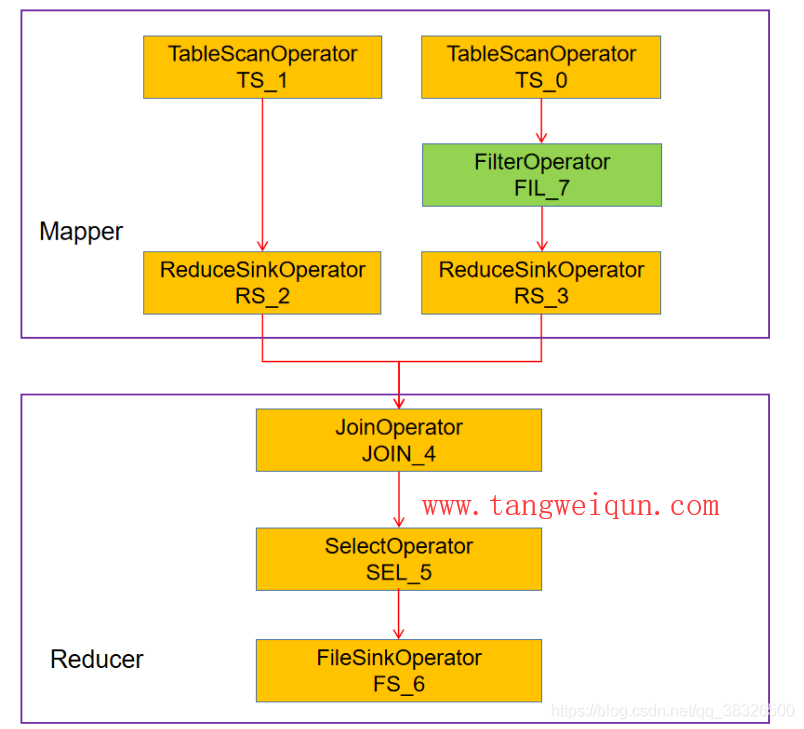
stage-0中就是一个MoveTask,这个任务就是将临时的结果文件Move到表INSERT OVERWRITE TABLE中的表中了
这个临时结果文件是stage-1产生的
stage-2只有Stats Task,这个任务就是更新相关表的统计信息
那么到现在为止,HiveQL对应的物理执行计划已经生成,这个时候可以调用相对应的执行引擎来执行上面的DAG。这样一个HiveQL的解析,转换,优化,执行的周期就结束了
总结一下
编译器的执行步骤为:

地图加入自动优化
在查看执行计划之前,我们还需要了解Hive在物理执行计划上的优化功能,有些优化在逻辑执行计划的层面上是优化不了的,需要在物理执行计划规模上来优化,从而我们经常见的Map Join
我们如果知道大表和小表进行Join的时候,我们当然可以指定使用Map Join,但是有的时候我们并不能确定Join的过程是不是大表Join小表,那这个时候可以让程序自动帮我们确定是不是大表Join小表,那这个时候程序肯定得知道两张表的大小这个信息吧,这个信息可能就需要在物理执行计划之中上来了,所以自动Map Join的优化是在物理执行计划之中进行的
例如,我们一直看的HiveQL:
insert overwrite table movie_temp
select a.movieId, a.moviename, b.url from movie a join movie_links b on a.movieId = b.movieId where b.url like "%https%";
将上面的HiveQL转成物理执行计划后,然后Hive会去自动检测两个张表对应的数据文件的大小,如果其中有一张表小于10M(可以通过)的话,则将这张表直接加载到内存中,作为一个本地的HashMap,就不需要进行Join了,直接从HashMap中拿数据就可以了,这样在Map端就可以完成Join了,就避免了shuffle了,这个就是Map Join。
当执行上面的HiveQL的时候,Hive发现movie_links表比较小,就会将movie_links放到HashMap中,然后在Map端就完成Join了,如下图:
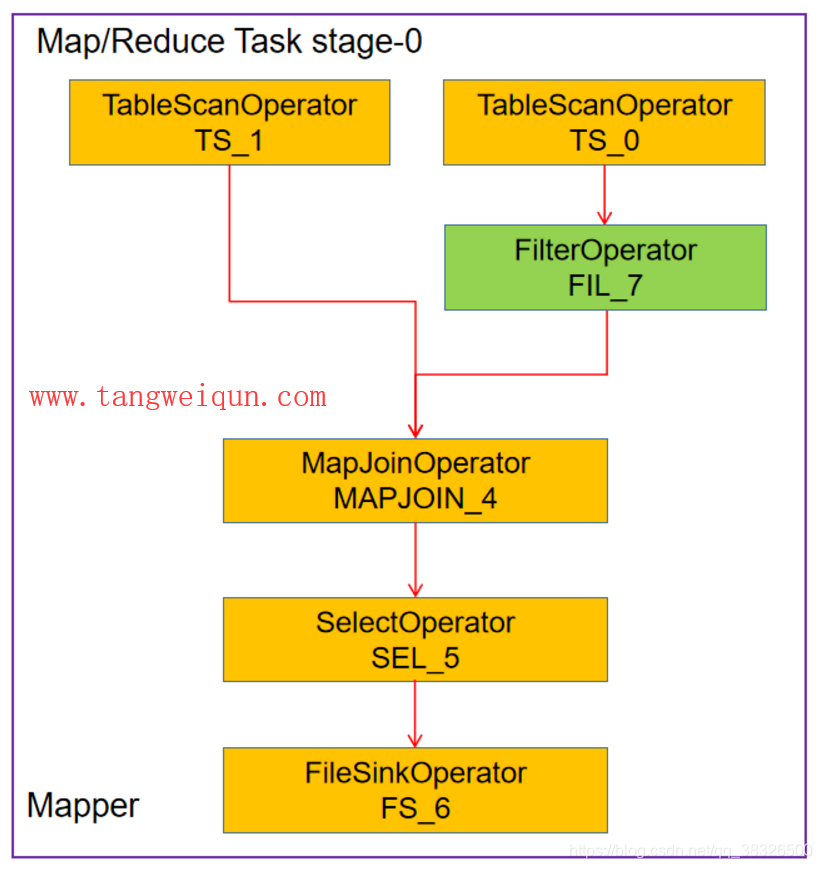
上面的Join虽然是在地图端完成,但是Hive会把上面的stage-0会分开两个stage,如下:
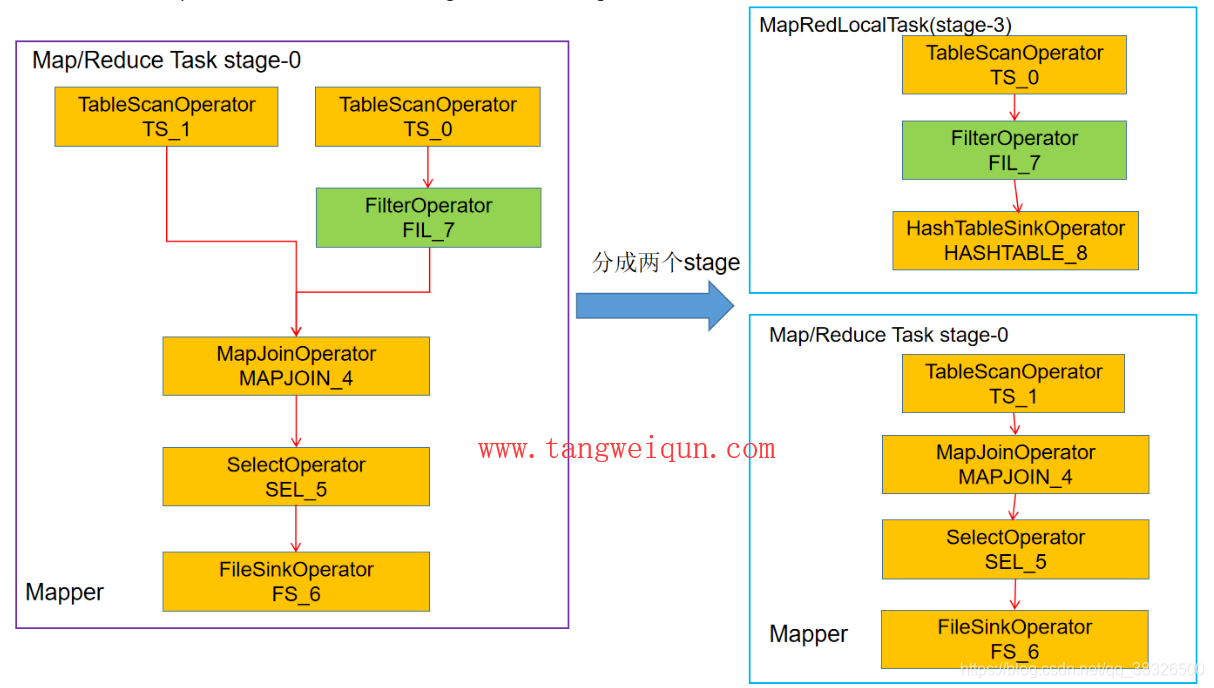
上图我们可以抛光,多了一个stage-3,这个阶段称为MapRedLocalTask,这个stage主要是完成将小表的数据加载进本地HashTable中的任务
stage-0主要就是完成扫描大表,然后从stage-3中找到对应的键的值完成join,上图右边的两个stage是物理执行计划中的两个阶段
总结一下:
Hive的地图Join的功能其实是自动打开的,是Hive在物理执行计划层面上做的一层优化
现在Compiler的执行步骤为:

执行计划的查看
在Hive命令中,我们可以通过EXPLAIN关键字来查看一个HiveQL的执行计划,执行下面的语句:
EXPLAIN insert overwrite table movie_temp
select a.movieId, a.moviename, b.url from movie a join movie_links b on a.movieId = b.movieId where b.url like "%https%";
得到的输出如下:
hive> explain insert overwrite table movie_temp
> select a.movieId, a.moviename, b.url from movie a join movie_links b on a.movieId = b.movieId where b.url like "%https%";
OK
STAGE DEPENDENCIES:
Stage-5 is a root stage
Stage-4 depends on stages: Stage-5
Stage-0 depends on stages: Stage-4
Stage-2 depends on stages: Stage-0
STAGE PLANS:
Stage: Stage-5
Map Reduce Local Work
Alias -> Map Local Tables:
$hdt$_1:b
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
$hdt$_1:b
TableScan
alias: b
Statistics: Num rows: 220 Data size: 10868 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((url like '%https%') and movieid is not null) (type: boolean)
Statistics: Num rows: 110 Data size: 5434 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: movieid (type: string), url (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 110 Data size: 5434 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 _col0 (type: string)
1 _col0 (type: string)
Stage: Stage-4
Map Reduce
Map Operator Tree:
TableScan
alias: a
Statistics: Num rows: 3568 Data size: 717256 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: movieid is not null (type: boolean)
Statistics: Num rows: 3568 Data size: 717256 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: movieid (type: string), moviename (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 3568 Data size: 717256 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: string)
1 _col0 (type: string)
outputColumnNames: _col0, _col1, _col3
Statistics: Num rows: 3924 Data size: 788981 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: string), _col1 (type: string), _col3 (type: string)
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 3924 Data size: 788981 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 3924 Data size: 788981 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
name: douban.movie_temp
Local Work:
Map Reduce Local Work
Stage: Stage-0
Move Operator
tables:
replace: true
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
name: douban.movie_temp
Stage: Stage-2
Stats-Aggr Operator
Time taken: 1.085 seconds, Fetched: 79 row(s)
我们从上往下来解释下:
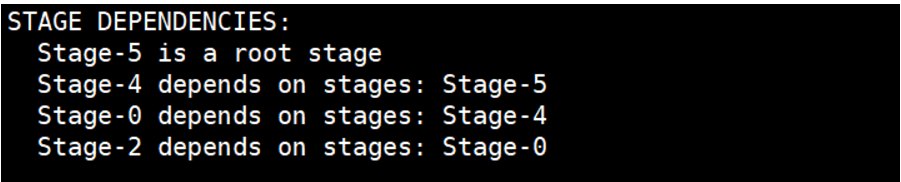
上图表示我们的HiveQL生成了一个4stage:stage-0,stage-2,stage-4,stage-5。其中stage-5是根stage。stage-4依赖于stage-5,stage-0依赖于stage -4,stage-2依赖于stage-0。所以他们的执行顺序是:stage-5 –> stage-4 –> stage-0 –> stage-2
接下来,我们来一次看下每一个阶段
第五阶段

第四阶段

上面本地需要完成的工作主要是指一些临时文件的清理工作等。
0阶段
第二阶段
这个阶段主要是进行统计信息的更新:

来自某位老师的指导大数据技术从业人员的福音
