设计背景
在数组中,我们可以根据索引快速取出某个位置元素的值(时间复杂度为O(1)级别),但是数组中每一个元素的索引是依据添加顺序决定的,该索引与元素本身也没有任何关联,当我们想再次查找某个元素的时候,只能将数组遍历一次才能找到我们需要的元素,相当的耗时(时间复杂度为O(n)级别)
树结构的诞生在很大程度上加快了搜索速度(例如二分搜索树在理想状态下的时间复杂度为O(logn)级别),但单从速度上讲依旧不及数组的索引取值。
我们希望设计一个函数,这个函数能通过每一个元素的特征来生成对应的索引值,然后将这个元素按它的索引值存进数组中,当我们需要从数组中取出该元素时,只需要利用这个函数再次计算该元素的索引值,这样就能快速的定位到该元素在数组中的位置了,在这种方案下设计的线性表就是著名的哈希表(Hash Table),而这种函数就被称为哈希函数(Hash Function),所生成的值便是哈希值(Hash)。
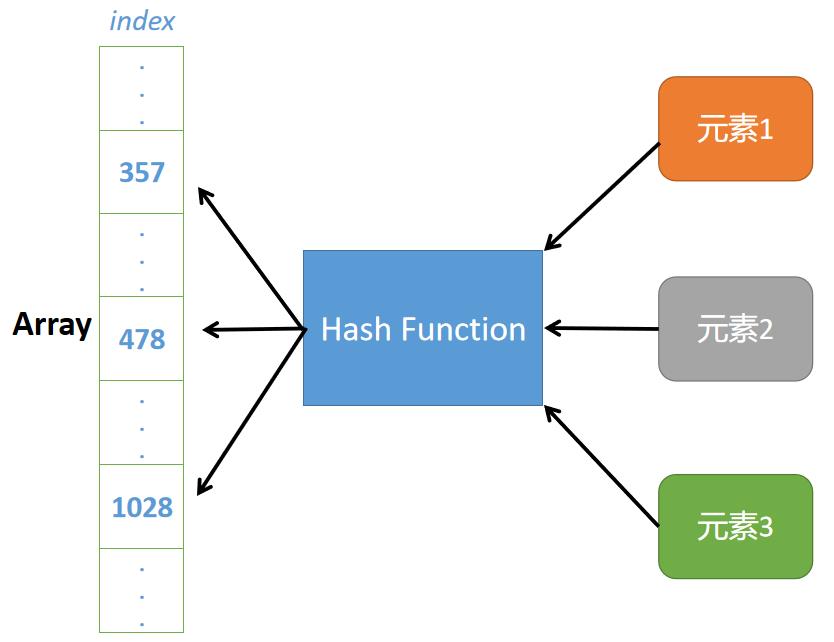
结构分析
【结构类型】线性结构
【底层实现】数组
【核心方法】
public void add(K key, V value); //向哈希表中添加元素
public V remove(K key); //从哈希表中移除元素
private void resize(int newM); //扩容和缩容
哈希函数
哈希表看似简单粗暴,似有一种秒杀全场的感觉,但设计哈希表所要面临的问题也是异常复杂的。
首先,哈希函数需要精良设计以尽可能的让每一个元素的哈希值分布更均匀、更高效;其次,哈希表所存储的元素有各种各样的类型,每一种类型所适应的方案也都不同;更进一步说,哈希索引所带来的间接影响就是庞大的数组容量问题。哈希函数的设计还需要牵涉其它学科的知识。
本文将举一个最简化的例子来演示哈希函数大致的运行过程:
public class Person {
/**
* 实例域:编号、性别、名字
*/
int id;
String sex;
String name;
/**
* 构造器:对实例域进行初始化
*
* @param id
* @param sex
* @param name
*/
public Person(int id, String sex, String name) {
this.id = id;
this.sex = sex;
this.name = name;
}
/**
* 覆写方法:哈希函数
*
* @return 哈希值
*/
@Override
public int hashCode() {
// 定义因数
int B = 32;
// 定义哈希值变量
int hash = 0;
// 将类中的属性转换成整形并累加
hash = hash * B + ((Integer) id).hashCode();
hash = hash * B + sex.hashCode();
hash = hash * B + name.hashCode();
return hash;
}
public static void main(String[] args) {
Person person1 = new Person(1, "男", "小张");
System.out.println(person1.hashCode());
Person person2 = new Person(2, "女", "小红");
System.out.println(person2.hashCode());
Person person3 = new Person(2, "女", "小红");
System.out.println(person3.hashCode());
}
}
主方法运行后输出:
1716177
1497811
1497811
因为我们设计的hashCode()中,并没有对有相同实例域值的不同对象进行区分,所以person2和person3所生成的哈希值相等。
哈希冲突
显而易见,不同的元素在同一套哈希函数下所生成的哈希值可能会相同,这种一个索引值对应多个元素的情况被称为哈希冲突。
解决哈希冲突的方法也有多种,最常用的一种方法就是分离链接法(Separate Chaining),分离链接法指在有重复元素的数组位置引用一个其它数据结构(例如链表、红黑树),将重复的元素都存入这个数据结构中。当用户以该索引号进行元素查找时,将会进入这个被链接的数据结构搜索。
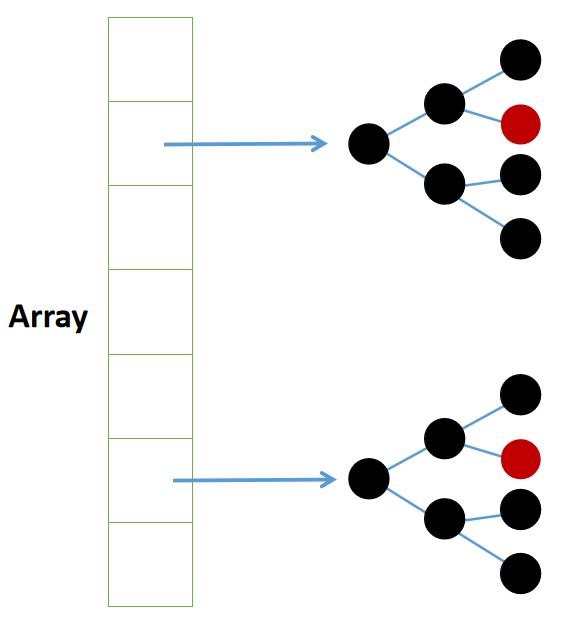
综上所知,虽然哈希表在理论上能够实现O(1)级别的查询,但正因有哈希函数、哈希冲突以及数组容量等不稳定性问题存在,哈希表在很多场景下并没有树结构实用,甚至在极端情况下还不及树结构的效率。
代码实现
该简易版实现采用链接TreeMap的方案(TreeMap的底层为红黑树)
import java.util.TreeMap;
public class HashTable<K extends Comparable<K>, V> {
// 根据哈希表优质素数,组建一个哈希表长度值的数组
private final int[] capacity = {53, 97, 193, 389, 769, 1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433, 1572869, 3145739, 6291469, 12582917,
25165843, 50331653, 100663319, 201326611, 402653189, 805306457, 1610612741};
// 定义容量容忍度的上限与下限
private static final int upperTol = 10;
private static final int lowerTol = 2;
// 定义capacity初始的下标
private int capacityIndex = 0;
/**
* 实例域:TreeMap数组、哈希表元素个数、哈希表总长度
*/
private TreeMap<K, V>[] hashTable;
private int size;
private int M;
/**
* 构造器:对实例域进行初始化
*/
public HashTable() {
M = capacity[capacityIndex];
size = 0;
hashTable = new TreeMap[M];
for (int i = 0; i < M; i++) {
hashTable[i] = new TreeMap<>();
}
}
/**
* 方法:添加元素
* @param key
* @param value
*/
public void add(K key, V value) {
// 根据key对应的索引,找到数组对应的位置
TreeMap<K, V> treeMap = hashTable[getHash(key)];
// 如果key已存在,直接更新value值即可
if (treeMap.containsKey(key)) {
treeMap.put(key, value);
} else { // 如果key不存在,直接添加
treeMap.put(key, value);
size++;
// 如果元素个数:表长已经超过最大容忍度,且capacity可用,则进行扩容操作
if (size >= upperTol * M && capacityIndex + 1 < capacity.length) {
capacityIndex++;
resize(capacity[capacityIndex]);
}
}
}
/**
* 方法:移除指定的元素
* @param key
* @return
*/
public V remove(K key) {
// 定义一个临时变量存储待删除元素的value
V value = null;
// 找到待删除元素在表中的索引
TreeMap<K, V> treeMap = hashTable[getHash(key)];
// 如果key存在,直接移除
if (treeMap.containsKey(key)) {
value = treeMap.remove(key);
size--;
// 如果元素个数:表长度小于最小容忍度,且capacity可用,则进行缩容操作
if (size < lowerTol * M && capacityIndex - 1 >= 0) {
capacityIndex--;
resize(capacity[capacityIndex]);
}
}
// 返回被删元素的value
return value;
}
/**
* 方法:扩容和缩容
* @param newM 新表的长度
*/
private void resize(int newM) {
// 实例一个新的TreeMap数组
TreeMap<K, V>[] newHashTable = new TreeMap[newM];
// 实例化新数组中的每一个TreeMap
for (int i = 0; i < newM; i++) {
newHashTable[i] = new TreeMap<>();
}
// 将旧表长度保存
int oldM = M;
// 更新表的长度变量
M = newM;
// 将旧数组中数据迁移至新数组
for (int i = 0; i < oldM; i++) {
TreeMap<K, V> treeMap = hashTable[i];
for (K key : treeMap.keySet()) {
newHashTable[getHash(key)].put(key, treeMap.get(key));
}
}
// 将旧表的引用指向新表
hashTable = newHashTable;
}
/**
* 方法:获取指定key对应的哈希索引
* @param key
* @return
*/
private int getHash(K key) {
return (key.hashCode() & 0x7fffffff) % M;
}
public int getSize() {
return size;
}
}
(附:在Java8之前,哈希表中每一个位置默认引用一个链表;在Java8之后,当哈希冲突达到一定程度后,链表将自动转换为红黑树)
