1.打开网页https://tophub.today/
2.按Ctrl+U 打开网页源代码

3.找到想要爬取的数据
4.
import requests import pandas as pd from bs4 import BeautifulSoup from pandas import DataFrame lst=[]#建立一个空列表 url='https://tophub.today/'#所抓取网页的网址 def get(url): try: headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}#伪装爬虫 url = requests.get(url,timeout = 30,headers=headers)#发送请求 url.raise_for_status() url.encoding='utf-8' return url.text except: return "产生异常" #创建一个放置数据的文件夹 def create(lst,html,num): soup=BeautifulSoup(html,'html.parser') a=soup.find_all('span',class_='t') b=soup.find_all('span',class_='e') print('{:^10}\t{:^30}\t{:^10}'.format('排名', '标题', '热度')) for i in range(num): print('{:^10}\t{:^30}\t{:^10}'.format(i+1, a[i+50].string, b[i+50].string))#打印出所爬取的内容 lst.append([i+1,a[i+50].string,b[i+50].string])#将爬取的数据放入列表中 html=get(url) create(lst,html,10) df=pd.DataFrame(lst,columns=['排名','标题','热度']) ZHHot='E:\新建文件夹\知乎热搜排行前十数据.xlsx' df.to_excel(ZHHot)
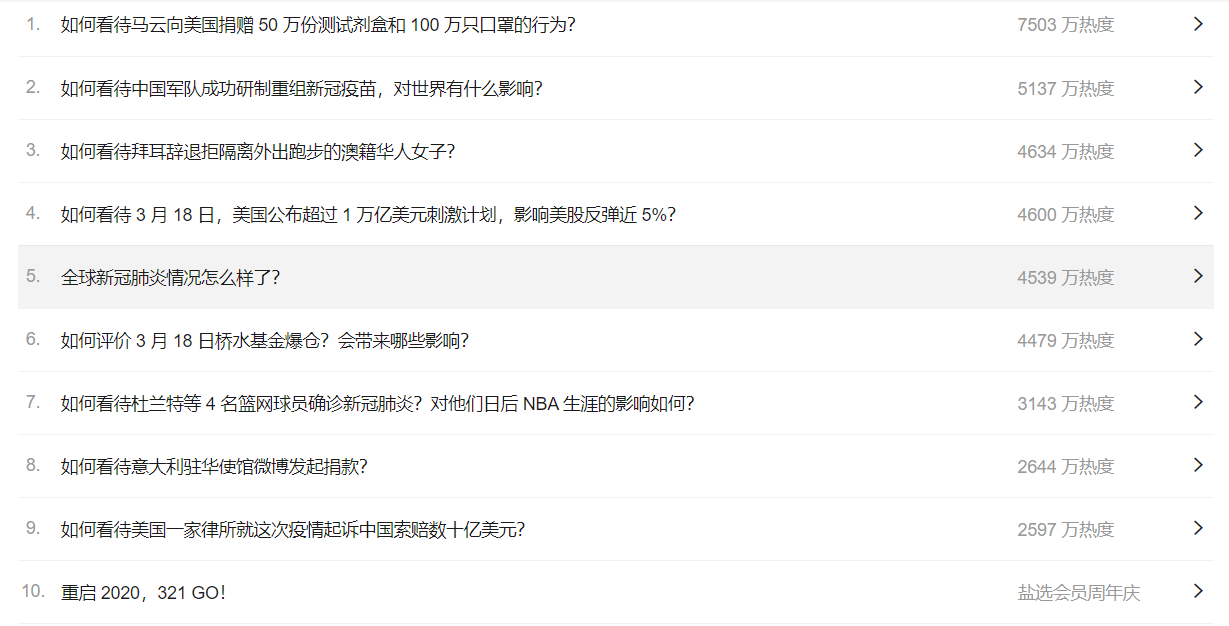
5.爬取的数据
