5.字符串问题
题1:判定字符是否唯一
实现一个算法,确定一个字符串 s 的所有字符是否全都不同。
示例 1:
输入: s = "leetcode"
输出: false
示例 2:
输入: s = "abc"
输出: true
限制:
0 <= len(s) <= 100
如果你不使用额外的数据结构,会很加分。
public static boolean isUnique(String astr) {
if(astr.length()==0){
return true;
}
int[] flag=new int[128];
for (int i = 0; i < astr.length(); i++) {
int n=(int)astr.charAt(i);
if(flag[n]>0){
return false;
}else {
flag[n]++;
}
}
return true;
}题2:字符串翻转
请实现一个算法,翻转一个给定的字符串.
测试样例:
"This is nowcoder"
返回:"redocwon si sihT"
public static String reverseString(String s){
int len=s.length();
char[] out=new char[len];
for (int i = 0; i < len; i++) {
out[len-i-1]=s.charAt(i);
}
return new String(out);
}
public static String reverseString1(String s) {
return new StringBuilder(s).reverse().toString();
}题3:变形词
变形词:两个串有相同的字符及数量组成 abc abc ,abc cba,aabcd bcada;
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1:输入: s = "anagram", t = "nagaram"
输出: true
示例 2:
输入: s = "rat", t = "car"
输出: false
说明:
你可以假设字符串只包含小写字母。
public static boolean isAnagram(String s, String t) {
if(s.length()!=t.length()){
return false;
}
char[] s1=s.toCharArray();
char[] t1=t.toCharArray();
Arrays.sort(s1);
Arrays.sort(t1);
return Arrays.equals(s1,t1);
}
public static boolean isAnagram1(String s, String t) {
int[] flag=new int[128];
if(s.length()!=t.length()){
return false;
}
for (int i = 0; i <s.length() ; i++) {
flag[(int)s.charAt(i)]++;
}
for (int i = 0; i < t.length(); i++) {
int a=(int)t.charAt(i);
flag[a]--;
if(flag[a]<0){
return false;
}
}
for (int a :flag) {
if(a!=0){
return false;
}
}
return true;
}
题4:替换%20
请编写一个方法,将字符串中的空格全部替换为“%20”。假定该字符串有足够的空间存放新增的字符,
并且知道字符串的真实长度(小于等于1000),同时保证字符串由大小写的英文字母组成。
给定一个string iniString 为原始的串,以及串的长度 int len, 返回替换后的string。
测试样例:
"Mr John Smith”,13
返回:"Mr%20John%20Smith"
”Hello World”,12
返回:”Hello%20%20World”
public static String replaceSpace(String s){
return s.replaceAll("\\s","%20");
}
public static String replaceSpace2(char[] s,int n){
int count=n;
for (int i = 0; i < n; i++) {
if(s[i]==' '){
count+=2;
}
}
int p1=n-1;
int p2=count-1;
while (p1>0){
if(s[p1]==' '){
s[p2--]='0';
s[p2--]='2';
s[p2--]='%';
}else {
s[p2--]=s[p1];
}
p1--;
}
return new String(s,0,count);
}System.out.println(replaceSpace("Mr John Smith"));
System.out.println(replaceSpace2("Mr John Smith000000000000000000000".toCharArray(), 13));
Mr%20John%20Smith
Mr%20John%20Smith题5:压缩字符串
字符串压缩。利用字符重复出现的次数,编写一种方法,实现基本的字符串压缩功能。比如,字符串aabcccccaaa会变为a2b1c5a3。若“压缩”后的字符串没有变短,则返回原先的字符串。你可以假设字符串中只包含大小写英文字母(a至z)。
示例1:
输入:"aabcccccaaa"
输出:"a2b1c5a3"
示例2:
输入:"abbccd"
输出:"abbccd"
解释:"abbccd"压缩后为"a1b2c2d1",比原字符串长度更长。
提示:
字符串长度在[0, 50000]范围内。
public static String compressString(String S) {
if (S.length()==0){
return "";
}
int last=0;
int count=1;
StringBuilder sb=new StringBuilder(S.charAt(0));
for (int i =1; i < S.length(); i++) {
if(S.charAt(i)==S.charAt(last)){
count++;
}else{
sb.append(S.charAt(last));
sb.append(count);
count=1;
}
last++;
}
sb.append(S.charAt(last));
sb.append(count);
if(sb.length()<S.length()){
return sb.toString();
}else{
return S;
}
}题6:两串的字符集相同
Map 存查取删
public static boolean check(String s,String t){//限制串的组成的字符时ASCII
int[] flag=new int[128];
for (int i = 0; i < s.length(); i++) {
flag[(int)s.charAt(i)]++;
}
for (int i = 0; i < t.length(); i++) {
if(flag[(int)t.charAt(i)]==0){
return false;
}
}
return true;
}
public static boolean check2(String s,String t){//不限制
Map<Character,Integer> map=new HashMap<Character, Integer>();
for (int i = 0; i < s.length(); i++) {
char c=s.charAt(i);
if(map.get(c)==null){
map.put(c,1);
}
}
for (int i = 0; i < t.length(); i++) {
char c=t.charAt(i);
if(map.get(c)==null){
return false;
}
}
return true;
}题7:是否为旋转词
给定两个字符串s1和s2,要求判定s2是否能够被通过s1作循环移位( rotate)得到的字符串包含。例如,给定s1= AABCD和s2=CDAA,返回true;给定s1= ABCD和S2= ACBD,返回false。
public static boolean checkRotate(String s1,String s2){
return new StringBuilder(s1).append(s1).toString().contains(s2);
}System.out.println(checkRotate("AABCD","CDAA"));
true题8:旋转单词顺序
输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。为简单起见,标点符号和普通字母一样处理。例如输入字符串"I am a student. ",则输出"student. a am I"。
示例 1:
输入: "the sky is blue"
输出: "blue is sky the"
示例 2:
输入: " hello world! "
输出: "world! hello"
解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
示例 3:
输入: "a good example"
输出: "example good a"
解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
public static String reverseWords(String s) {
String t=new StringBuilder(s).reverse().toString();
String[] words=t.split("\\s");
StringBuilder sb=new StringBuilder();
for (String word:words) {
if(word.length()!=0){//前后有空串的情况要去掉
sb.append(new StringBuilder(word).reverse().toString()+" ");
}
}
if(sb.length()==0){//sb为空再执行下面的-1会报错
return "";
}else {
return sb.deleteCharAt(sb.length() - 1).toString();//删除最后一次加的空格,再返回
}
}题9:去掉字符串中连接出现的次的0
public static String remove(String s,int k){
String regexp="0{"+k+"}";
return s.replaceAll(regexp,"");
}
public static String remove2(String s,int k){
StringBuilder sb=new StringBuilder();
int count=0;
for (int i = 0; i < s.length(); i++) {
char a=s.charAt(i);
if(a=='0'){
count++;
}else{
for (int j = 0; j < count%k; j++) {
sb.append('0');
}
sb.append(a);
count=0;
}
}
for (int j = 0; j < count%k; j++) {
sb.append('0');
}
return sb.toString();
}题10:回文串
public static boolean isPalindrome(String s){
return s.equals(new StringBuilder(s).reverse().toString());
}
public static void palindromeNum(){
//1221是一个非常特殊的数,它从左边读和从右边读是一样的,编程求所有这样的四位十进制数。
for (int i= 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
System.out.println(i*1000+j*100+j*10+i);
}
}
}题11:最短摘要
给定一段产品的英文描述,包含M个英文字母,每个英文单词以空格分隔,无其他标点符号;再给定N个英文单词关键字,请说明思路并编程实现方法String extractSummary(String description,String[] key words)
目标是找出此产品描述中包含N个关键字(每个关键词至少出现一次)的长度最短的子串,作为产品简介输出。
将问题可以划分成包含关键字那段,最后一个,先确定一个最小的包含最后一个的,对应pEnd++,然后固定pEnd,pBegin在满足isAllExisted不断右移,更新最小长度。pBegin右移到不满足isAllExisted时,pEnd右移,当满足isAllExisted时停下,pBegin在满足isAllExisted不断右移,更新最小长度
import java.util.*;
public class _最短摘要 {
public static boolean isAllExisted(Map<String, Integer> keywordCount) {
for (Integer i:keywordCount.values()) {
if(i==0)
return false;
}
return true;
}
public static String extractSummary(String description,String[] keywords){
String[] words=description.split(" ");
List<String> descriptions=new ArrayList<String>();
for (int i = 0; i <words.length ; i++) {//去处空格,放到descriptions中
if(words[i].length()!=0){
descriptions.add(words[i]);
}
}
Map<String,Integer> keywordCount=new HashMap<String, Integer>();
for (String s:keywords) {
keywordCount.put(s,0);
}
int N=descriptions.size();
int nTargetLen = N + 1;
int pBegin=0;
int pEnd=0;
int nAbstractBegin=0;
int nAbstractEnd=0;
while (true){
while (!isAllExisted(keywordCount)&&pEnd<N){
if(keywordCount.get(descriptions.get(pEnd))!=null){//pEnd如果是关键词就计数+1
int a=keywordCount.get(descriptions.get(pEnd));
a++;
keywordCount.put(descriptions.get(pEnd),a);
}
pEnd++;
}
while (isAllExisted(keywordCount)){
if(pEnd-pBegin<nTargetLen){//发现距离小的更新
nTargetLen=pEnd-pBegin;
nAbstractBegin=pBegin;
nAbstractEnd=pEnd-1;//由于上次循环多加了pEnd,忘记-1
}
if(keywordCount.get(descriptions.get(pBegin))!=null){//pBegin如果是关键词就计数-1
int a=keywordCount.get(descriptions.get(pBegin));
a--;
keywordCount.put(descriptions.get(pBegin),a);
}
pBegin++;
}
if(pEnd>=N){
break;
}
}
String summary=new String();//nAbstractBegin到nAbstractEnd返回
for (int i = nAbstractBegin; i <=nAbstractEnd ; i++) {
summary=summary+descriptions.get(i)+" ";
}
return summary;
}
public static void main(String[] args) {
String description=" hello software hello test world spring sun flower hello";
String[] keywords = {"hello","world"};
System.out.println(extractSummary(description,keywords));
}
}Rabin Karp
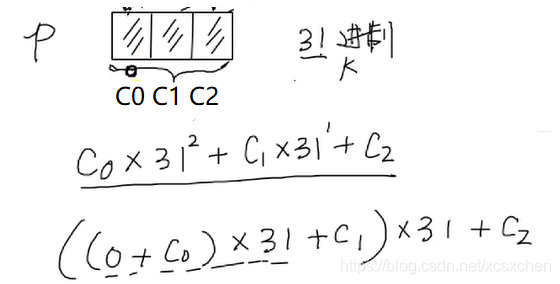
按照k进制,以char的值为系数,算出字符串对应的hash
static long hash(String str) {
long h = 0;
for (int i = 0; i < str.length(); ++i) {
h = seed * h + str.charAt(i);//上一次的哈希值h*31+这一次字符串
}
return h % Long.MAX_VALUE;
}在字符串匹配过程中,采用滚动Hash的方法,使算法复杂度为O(m+n),计算txt的子串的Hash时,不一一计算,而是借用上一次的Hash
public static int RabinKarp(String txt,String pat,int q){//q为质数,也叫种子
long patHash=0;
long txtHash=0;
for (int i = 0; i < pat.length(); i++) {
patHash=patHash*q+pat.charAt(i);
txtHash=txtHash*q+txt.charAt(i);
}
for (int i = 0; i <=txt.length()-pat.length(); i++) {
if(patHash==txtHash){
int j;//一般情况下,hash相同不需要在匹配一次,有概率hash相同字符不同
for (j = 0; j <pat.length() ; j++) {
if (txt.charAt(i+j) != pat.charAt(j))
break;
}
if(j==pat.length()){
return i;
}
}
if(i<txt.length()-pat.length()){//加条件,最后一次不在计算
char oldc=txt.charAt(i);
char newc=txt.charAt(i+pat.length());
int n=pat.length();
txtHash=txtHash*q+newc-(long)Math.pow(q,n)*oldc;//(上一次的hash值*q+新字符)-oldc的hash,注意在减去第一个的时候,不是减去pow(q,n-1)*oldc,因为前面多乘
txtHash=txtHash%Long.MAX_VALUE;
}
}
return -1;
}暴力字符匹配
public static int Index(String S,String T,int pos){//返回子串T在主串S中第pos个字符之后的位置。若不存在则函数值为-1
int i=pos,j=0;
while(i<S.length()&&j<T.length()){
if(S.charAt(i)==T.charAt(j)){//继续比较后继字符
i++;
j++;
}else {//指针后退,-j重新下一个开始匹配+1
i=i-j+1;
j=0;
}
}
if(j==T.length()){
return i-T.length();//i退回多走的距离
}
return -1;
}KMP
和暴力匹配相比,在失配时,i不变,j回退到next[j],如果回退的next[j]为-1,则i向后一个,j回到0,对应代码i++,j++
next数组只与模式相关,里面存储了前后缀哪里相同的信息,用来减少比较次数,i就不用回退了,不匹配时,可以不动了
public static int Index_KMP(String S,String T,int pos){//S为主串,T为模式串
int i=pos,j=0;
int next[]=new int[T.length()];
get_next4(T,next);
while(i<S.length()&&j<T.length()){
if(j==-1||S.charAt(i)==T.charAt(j)){
i++;
j++;
}else{
j=next[j];
}
}
if(j==T.length()){
return i-T.length();
}
return -1;
}
j的值为next[i],如果next[j]等于next[i] next[i+1]=j+1,不等的话,j往前回溯,继续找更短的+1,如果j为-1了,讲next[i+1]复制为0,意味着没有公共前后缀,在上个函数j=next[j]时回到0,
public static void get_next2(String T,int[] next) {
int i=0;
next[0]=-1;//第一个元素代表j往前回溯到头了,必须初始化为-1
int j=-1;
while(i<T.length()-1){//注意这里是第一次i为0,但是是在填next[1],所有填最后一个时i为T.length()-2
if(j==-1||T.charAt(i)==T.charAt(j)){
i++;
j++;
next[i]=j;//相当于next[i+1]=j+1
}else{
j=next[j];//j往前回溯
}
}
}改进版求next
在匹配函数j=next[j]时,j回退的位置值很可能失配时j的值相等,由于S.charAt(i)不等于T.charAt(j),所以回退的位置一定也不会与S.charAt(i)相等,造成无用匹配。

public static void get_next4(String T,int[] nextval) {
int i=0;
nextval[0]=-1;
int j=-1;
while(i<T.length()-1){
if(j==-1||T.charAt(i)==T.charAt(j)){
i++;
j++;
if(T.charAt(i)!=T.charAt(j)) {//要填T.charAt(i)!=回退T.charAt(j)
nextval[i]=j;//nextval[i]的就为j
}else {
nextval[i]=nextval[j];//nextval[i]为前一个的值
}
}else{
j=nextval[j];
}
}
}KMP例题
如题,给出两个字符串s1 和 s2,其中 s2 为 s_1s1 的子串,求出 s_2s2 在 s_1s1 中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组 next。
输入格式
第一行为一个字符串,即为 s_1s1。
第二行为一个字符串,即为 s_2s2
输出格式
若干行,每行包含一个整数,表示 s_2s2 在 s_1s1 中出现的位置
接下来 11 行,包括 |s2|∣s2∣ 个整数,表示前缀数组 next_inexti 的值。
输入 #1
ABABABC
ABA输出 #1
1
3
0 0 1
import java.util.Scanner;
public class Main {
private static int[] get_next(String s2) {
int[] next=new int[s2.length()+1];
int i=0,j=-1;
next[0]=-1;
while (i<s2.length()){
if(j==-1||s2.charAt(i)==s2.charAt(j)){
i++;
j++;
next[i]=j;
}else {
j=next[j];
}
}
return next;
}
private static int[] get_nextval(String s2) {
int[] nextval=new int[s2.length()+1];
int i=0,j=-1;
nextval[0]=-1;
while (i<s2.length()-1){
if(j==-1||s2.charAt(i)==s2.charAt(j)){
i++;
j++;
if(s2.charAt(i)!=s2.charAt(j)){
nextval[i]=j;
}else {
nextval[i]=nextval[j];
}
}else {
j=nextval[j];
}
}
return nextval;
}
private static void KMP(String s1, String s2) {
int next[]=get_next(s2);
int nextval[]=get_nextval(s2);
int i=0,j=0;
while(i<s1.length()){
if(j==s2.length()){
System.out.println(i-j+1);
j=nextval[s2.length()];
}
if(j==-1||s1.charAt(i)==s2.charAt(j)){
i++;
j++;
}else{
j=nextval[j];
}
}
if(j==s2.length()){
System.out.println(i-j+1);
}
for (int k = 1; k <next.length ; k++) {
System.out.print(next[k]+" ");
}
}
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
String s1=sc.next();
String s2=sc.next();
KMP(s1,s2);
}
}#include<iostream>
#include<string>
using namespace std;
void get_next(const string &s2,int next[]){
int i=0,j=-1;
next[0]=-1;
while (i<s2.length()){
if(j==-1||s2[i]==s2[j]){
i++;
j++;
next[i]=j;
}else {
j=next[j];
}
}
}
void KMP(const string s1,const string s2){
const int s1Len=s1.length();
const int s2Len=s2.length();
int next[s2Len+1];
get_next(s2,next);
int i=0,j=0;
while(i<s1.length()){
if(j==s2.length()){
cout<<i-j+1<<endl;
j=next[s2.length()];
}
if(j==-1||s1[i]==s2[j]){
i++;
j++;
}else{
j=next[j];
}
}
if(j==s2.length()){
cout<<i-j+1<<endl;
}
for (int k = 1; k <s2Len+1 ; k++) {
cout<<next[k]<<" ";
}
}
int main(){
string s1,s2;
cin>>s1>>s2;
KMP(s1,s2);
}后缀数组
什么是后缀数组
就是串的所有后缀子串的按字典序排序后,在数组中记录后缀的起始下标,
后缀数组就是:排名和原下标的映射 sa[0]=5,起始下标为5的后缀在所有后缀中字典序最小
rank数组:给定后缀的下标,返回其字典序,rk[5]=0; rk[sa[i]]=i;后缀数组有啥用
匹配==子串:一定是某个后缀的前缀==
怎么求后缀数组
3.1 把所有后缀放入数组,Arrays.sort();n²log(n)
3.2 倍增法
k=1,一个字符,排序,得到sa,rk
k=2,利用上一轮的rk快速比较两个后缀
k=4
k=8Suffix类
public static class Suff implements Comparable<Suff> {
public char c;//后缀内容
private String src;
public int index;//后缀的起始下标
public Suff(char c, int index, String src) {
this.c = c;
this.index = index;
this.src = src;
}
@Override
public int compareTo(Suff o2) {
return this.c - o2.c;
}
@Override
public String toString() {
return "Suff{"+"char='" + src.substring(index) + '\'' +", index=" + index +'}';
}
}获取sa数组
public static Suff[] getSa2(String src) {
int n = src.length();
Suff[] sa = new Suff[n];
for (int i = 0; i < n; i++) {
sa[i] = new Suff(src.charAt(i), i, src);//存单个字符,接下来排序
}
Arrays.sort(sa);
/**rk是下标到排名的映射*/
int[] rk = new int[n];//suffix array
rk[sa[0].index] = 1;
for (int i = 1; i < n; i++) {
rk[sa[i].index] = rk[sa[i - 1].index];
if (sa[i].c != sa[i - 1].c) rk[sa[i].index]++;
}
//倍增法
for (int k = 2; rk[sa[n - 1].index] < n; k *= 2) {
final int kk = k;
Arrays.sort(sa, (o1, o2) -> {
//不是基于字符串比较,而是利用之前的rank
int i = o1.index;
int j = o2.index;
if (rk[i] == rk[j]) {//如果第一关键字相同
if (i + kk / 2 >= n || j + kk / 2 >= n)
return -(i - j);//如果某个后缀不具有第二关键字,那肯定较小,索引靠后的更小
return rk[i + kk / 2] - rk[j + kk / 2];
} else {
return rk[i] - rk[j];
}
});
/*---排序 end---*/
// 更新rank
rk[sa[0].index] = 1;
for (int i = 1; i < n; i++) {
int i1 = sa[i].index;
int i2 = sa[i - 1].index;
rk[i1] = rk[i2];
try {
if (!src.substring(i1, i1 + kk).equals(src.substring(i2, i2 + kk)))
rk[i1]++;
} catch (Exception e) {
rk[i1]++;
}
}
}
return sa;
}获取高度数组
public static int[] getHeight(String src, Suff[] sa) {
// Suff[] sa =getSa2(src);
int strLength = src.length();
int[] rk = new int[strLength];
//将rank表示为不重复的排名即0~n-1
for (int i = 0; i < strLength; i++) {
rk[sa[i].index] = i;
}
int[] height = new int[strLength];
// 如果已经知道后缀数组中i与i+1的lcp为h,那么i代表的字符串与i+1代表的字符串去掉首字母后的lcp为h-1.
// 根据这个我们可以发现,如果知道i与后缀数组中在它后一个的lcp为k,那么它去掉首字母后的字符串与其在后缀数组中的后一个的lcp大于等于k-1.
// 例如对于字符串abcefabc,我们知道abcefabc与abc的lcp为3.
// 那么bcefabc与bc的lcp大于等于3-1.
// 利用这一点就可以O(n)求出高度数组。
int k = 0;
for (int i = 0; i < strLength; i++) {
int rk_i = rk[i];//i后缀的排名
if (rk_i == 0) {
height[0] = 0;
continue;
}
int rk_i_1 = rk_i - 1;
int j = sa[rk_i_1].index;//j是i串字典序靠前的串的下标
if (k > 0) k--;
for (; j + k < strLength && i + k < strLength; k++) {
if (src.charAt(j + k) != src.charAt(i + k))
break;
}
height[rk_i] = k;
}
return height;
}字符串匹配
public static int SuffixMatch(String s,String p) {//p为模式串
Suff[] sa = getSa2(s);//后缀数组
int l = 0;
int r = s.length() - 1;
//二分查找,nlog(m)
while (r >= l) {
int mid = l + ((r - l) >> 1);
//居中的后缀
Suff midSuff = sa[mid];
String suffStr = s.substring(midSuff.index);
int compareRes;
//将后缀和模式串比较,O(n)
if (suffStr.length() >= p.length())
compareRes = suffStr.substring(0, p.length()).compareTo(p);
else
compareRes = suffStr.compareTo(p);
//相等了,输出后缀的起始位置
if (compareRes == 0) {
return midSuff.index;
} else if (compareRes < 0) {
l = mid + 1;
} else {
r = mid - 1;
}
}
return -1;
}题1:hiho字符串
如果一个字符串恰好包含2个'h'、1个'i'和1个'o',我们就称这个字符串是hiho字符串。
例如"oihateher"、"hugeinputhugeoutput"都是hiho字符串。
现在给定一个只包含小写字母的字符串S,小Hi想知道S的所有子串中,最短的hiho字符串是哪个。
输入
字符串S
对于80%的数据,S的长度不超过1000
对于100%的数据,S的长度不超过100000
输出
找到S的所有子串中,最短的hiho字符串是哪个,输出该子串的长度。如果S的子串中没有hiho字符串,输出-1。
样例输入
happyhahaiohell样例输出
5import java.util.*;
public class Main {
public static boolean isAllExisted(Map<Character, Integer> keywordCount) {
if(keywordCount.get('h')>=2&&keywordCount.get('i')>=1&&keywordCount.get('o')>=1){
return true;
}
return false;
}
public static boolean isAllExisted2(Map<Character, Integer> keywordCount) {
if(keywordCount.get('h')==2&&keywordCount.get('i')==1&&keywordCount.get('o')==1){
return true;
}
return false;
}
public static int extractSummary(String description){
Map<Character,Integer> keywordCount=new HashMap<Character, Integer>();
keywordCount.put('h',0);
keywordCount.put('i',0);
keywordCount.put('o',0);
int N=description.length();
int nTargetLen = N + 1;
int pBegin=0;
int pEnd=0;
int nAbstractBegin=0;
int nAbstractEnd=0;
while (true){
while (!isAllExisted(keywordCount)&&pEnd<N){
if(keywordCount.get(description.charAt(pEnd))!=null){//pEnd如果是关键词就计数+1
int a=keywordCount.get(description.charAt(pEnd));
a++;
keywordCount.put(description.charAt(pEnd),a);
}
pEnd++;
}
while (isAllExisted(keywordCount)){
if(pEnd-pBegin<nTargetLen&&isAllExisted2(keywordCount)){//发现距离小的更新
nTargetLen=pEnd-pBegin;
nAbstractBegin=pBegin;
nAbstractEnd=pEnd-1;//由于上次循环多加了pEnd,忘记-1
}
if(keywordCount.get(description.charAt(pBegin))!=null){//pBegin如果是关键词就计数-1
int a=keywordCount.get(description.charAt(pBegin));
a--;
keywordCount.put(description.charAt(pBegin),a);
}
pBegin++;
}
if(pEnd>=N){
break;
}
}
if(nAbstractBegin==0&&nAbstractEnd==0){
return -1;
}
return nAbstractEnd-nAbstractBegin+1;
}
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
String description=sc.next();
System.out.println(extractSummary(description));
}
}
题2:next数组
For each prefix of a given string S with N characters (each character has an ASCII code between 97 and 126, inclusive), we want to know whether the prefix is a periodic string. That is, for each i (2 <= i <= N) we want to know the largest K > 1 (if there is one) such that the prefix of S with length i can be written as A K , that is A concatenated K times, for some string A. Of course, we also want to know the period K.
Input
The input file consists of several test cases. Each test case consists of two lines. The first one contains N (2 <= N <= 1 000 000) – the size of the string S. The second line contains the string S. The input file ends with a line, having the number zero on it.
Output
For each test case, output “Test case #” and the consecutive test case number on a single line; then, for each prefix with length i that has a period K > 1, output the prefix size i and the period K separated by a single space; the prefix sizes must be in increasing order. Print a blank line after each test case.
Sample Input
3
aaa
12
aabaabaabaab
0Sample Output
Test case #1
2 2
3 3
Test case #2
2 2
6 2
9 3
12 4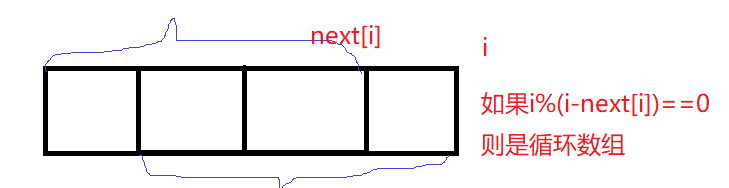
import java.util.*;
public class Main {
public static void getNext(String S){
int len=S.length();
int i=0,j=-1;
int[] next=new int[len+1];
next[0]=-1;
while(i<len){
if(j==-1||S.charAt(i)==S.charAt(j)){
i++;
j++;
next[i]=j;
}else{
j=next[j];
}
}
for ( i = 2; i < next.length; i++) {
int t = i - next[i];//重复的部份的个数
if (i % t == 0 && i / t > 1) {
System.out.println(i + " " + i / t);//总长度 断数
}
//aa a 两段
//aabaab aab 两段
//aabaabaab aab 三段
//aabaabaabaab aab 四段
}
}
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
int i=1;
while(true){
int num=sc.nextInt();
if(num==0){
break;
}
String S=sc.next();
System.out.println("Test case #"+i);
i++;
getNext(S);
System.out.println();
}
}
}题3:最长重复子串(可重叠或者说可交叉)
public static int maxRepeatSubString(String src) {
Suff[] sa = getSa2(src);
int[] height = getHeight(src, sa);
int maxHeight = 0;
int maxIndex = -1;
for (int i = 0; i < height.length; i++) {
if (height[i] > maxHeight) {
maxHeight = height[i];
maxIndex = i;
}
}
int index = sa[maxIndex].index;//转成原始下标
System.out.println(src.substring(index, index + maxHeight));
return maxHeight;
}题4:不可重叠的最长重复子串
/**
* 用len将height分组,小于组和大于等于组交替
* 在大于组中更新最大最小原始小标,大转小的时候检查上一个大于组是否满足不重叠
* 在小于组中,只需持续地将原始下标付给max和min,这样小转大的时候,可以保留小于组最后一个元素的下标
* @param height
* @param sa
* @param len
* @return
*/
private static boolean check(int[] height,Suff[] sa, int len) {
int minIndex = sa[0].index;
int maxIndex = sa[0].index;
for (int i = 1; i < height.length; i++) {
int index = sa[i].index;
if (height[i] >= len) {//lcp大于len
minIndex = min(minIndex, index);
maxIndex = max(maxIndex, index);
} else {
if (maxIndex - minIndex >= len) {
return true;
}
maxIndex = index;
minIndex = index;
}
}
/* int tot = 0,maxsa=sa[0],minsa=sa[0];
for (int i = 1; i < n; i++){
if (height[i] >= k){
maxsa = max(maxsa, sa[i]);
minsa = min(minsa, sa[i]);
}
else{
if (maxsa - minsa >= k){
return true;
}
maxsa = sa[i], minsa = sa[i];
}
}
if (maxsa - minsa >= k){
return true;
}
return false;*/
return (maxIndex - minIndex) >= len;
}
public static int maxRepeatSubString2(String src) {
Suff[] sa =getSa2(src);
int[] height =getHeight(src, sa);
int l = 0;
int r = height.length;
int ans = 0;
while (l <= r) {
int mid = l + ((r - l) >> 1);//check的重叠长度
if (check(height, sa, mid)) {
if (mid == height.length / 2) {
return mid;
}
l = mid + 1;
ans = mid;
// return mid;
} else {
r = mid - 1;
}
}
return ans;
}题目5:两串最大重复子串
/**
* 高度数组,是后缀数组中每两个字符串的最长公共前缀的长度
* 用于求解两个串的最长公共子串:
* 先拼起来,求后缀数组和高度数组
* 高度数组的最大值指示了两个排序接近的后缀的公共前缀的长度
* 两个字符串的最长公共子串一定就是这两条后缀的公共前缀
*/
private static String longestCommonSubString(String s1, String s2) {
String s = s1 + "$" + s2;
Match03_SuffixArray.Suff[] sa = Match03_SuffixArray.getSa2(s);
int[] height = Match03_SuffixArray.getHeight(s, sa);
int maxHeight = 0;
int index = -1;
for (int i = 0; i < height.length; i++) {
if (height[i] > maxHeight) {
int index1 = sa[i].index;
int index2 = sa[i - 1].index;
if (Math.abs(index1 - index2) >= height[i]) {
maxHeight = height[i];
index = index1;
}
}
}
return s.substring(index, index + maxHeight);
}