- 数据清洗与格式转换
- 探索性数据分析
- 特征筛选
1.数据清洗与格式转换
通过pandas来导入csv:查看一下数据的基本情况,可以看到,整个数据集有3333条数据,21个维度,最后一列是分类
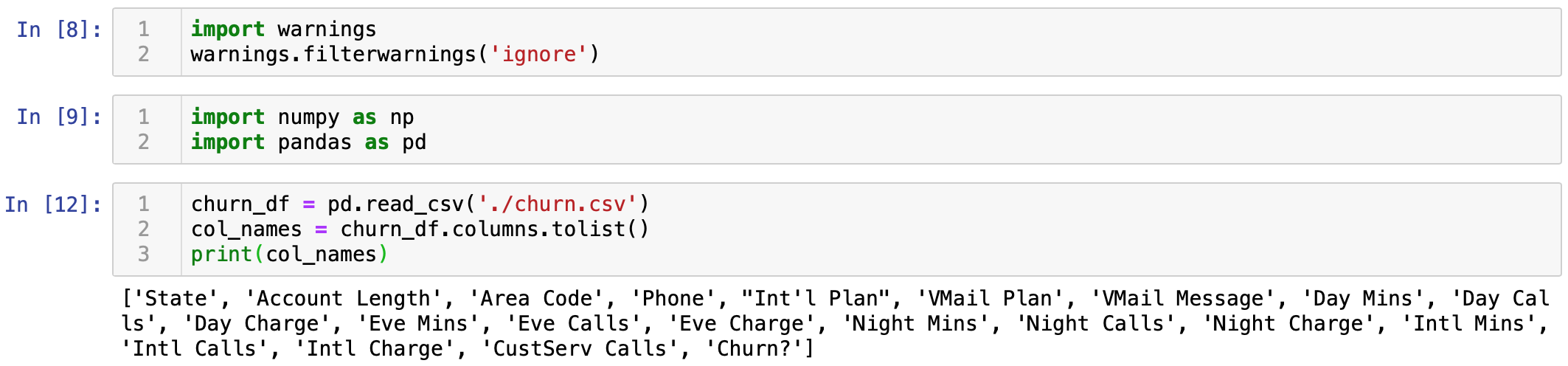
基本信息以及类型
我们可以看到
1.个人信息:州名、账号长度、区号、电话号码,这些个人信息对结果意义不大,删除
2.国际计划,语音邮箱,可能有关系,先保留
3.分别统计了白天,晚间,夜间的通话分钟、电话个数、收费情况,这是重要信息,保留
4.客服电话,客户打电话投诉会导致流失率增大,重要信息保留
5.流失与否,这是分类结果
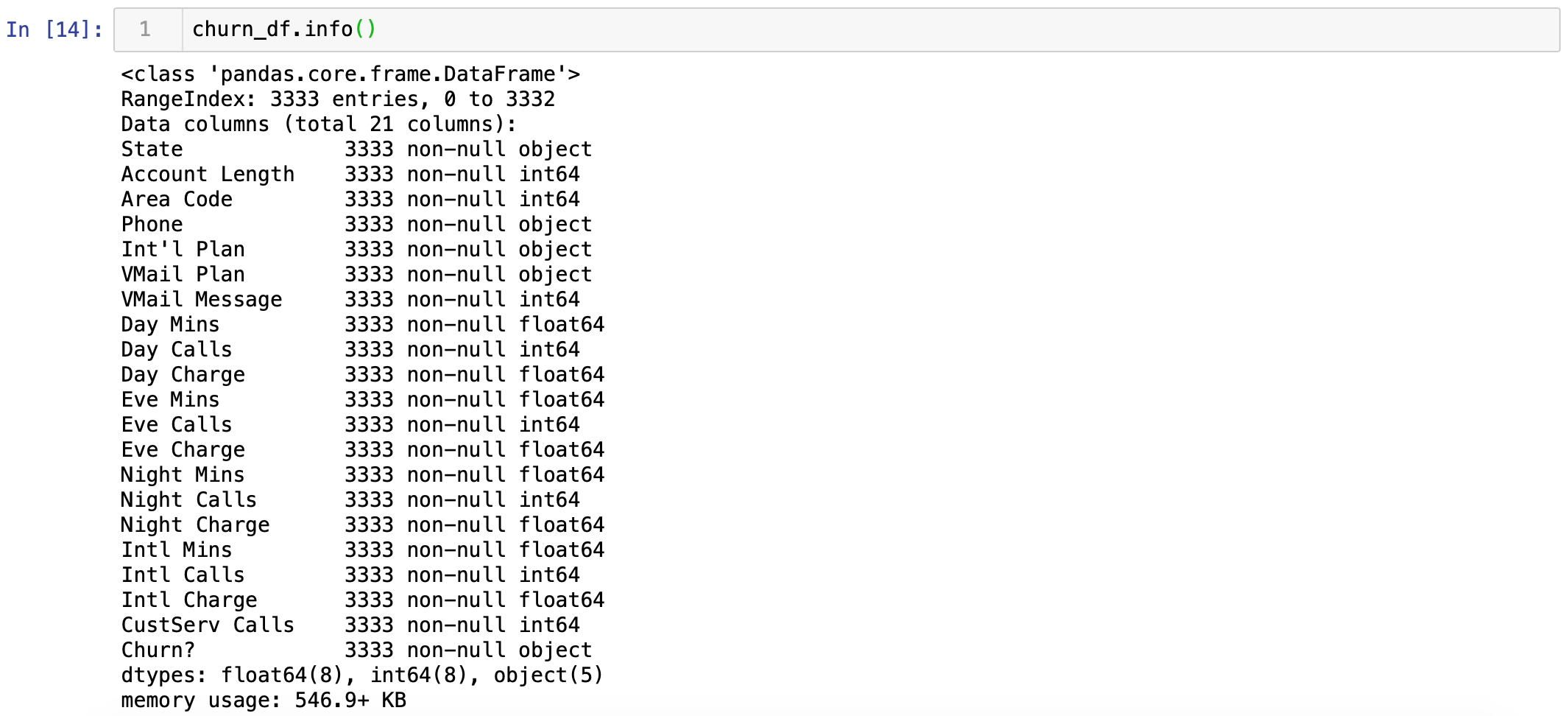
对于不是数据型的数据,后面除非决策树等算法,否则应该会转化成数据行,所以把churn?结果列转化,以及"Int'l Plan",'VMail Plan',这两个参数只有yes,no两种,也转化成0,1值
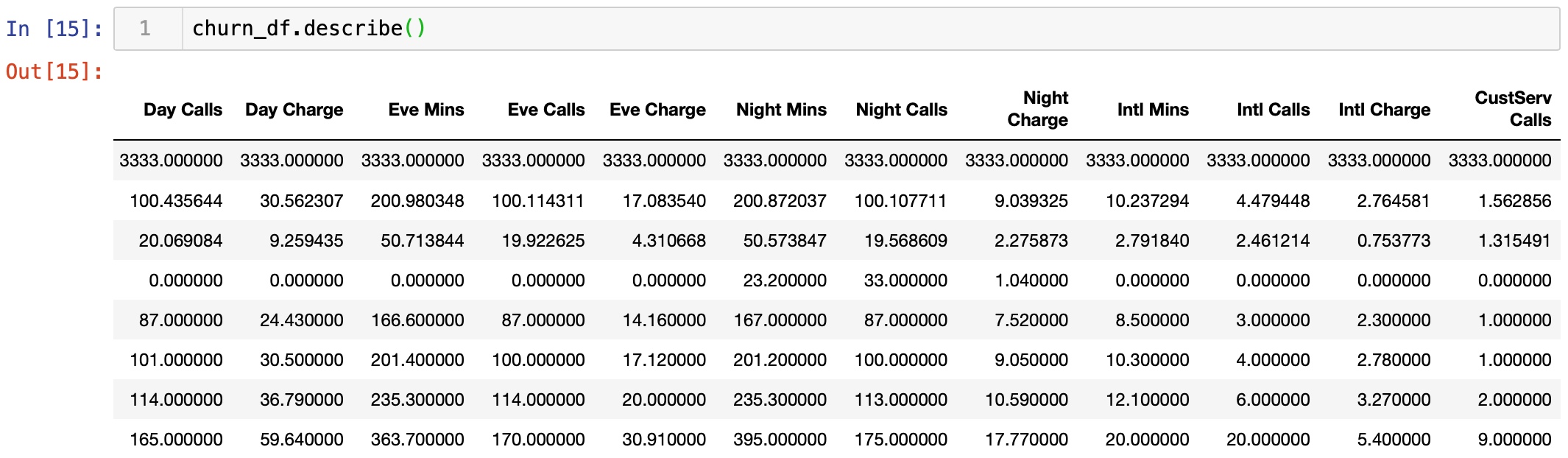
2.探索性数据分析
特征自己的信息
特征和特征之间的关系
特征和标签之间的关系
step1 :特征自己的信息
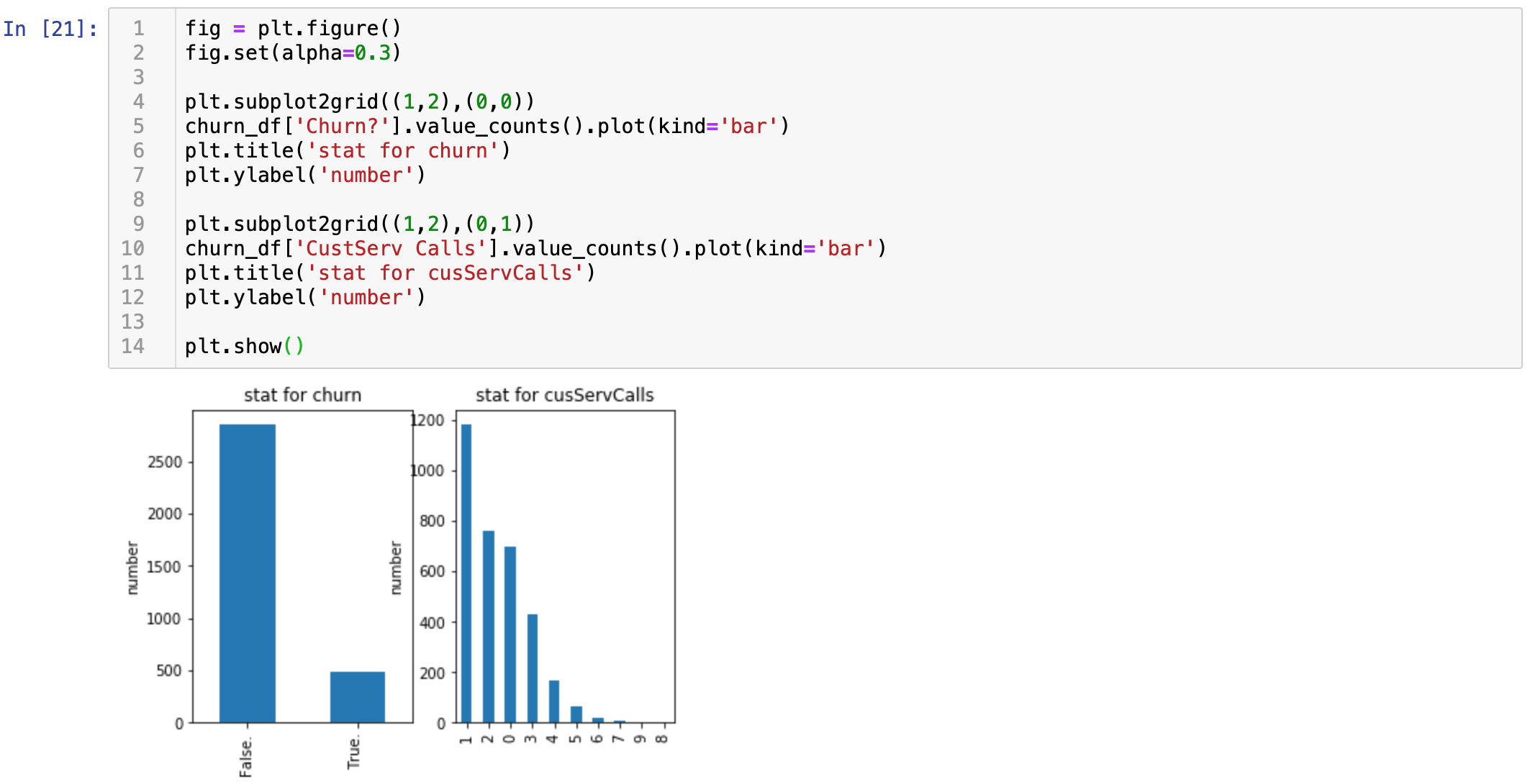
一共3333个样本,False代表没有流失2700个左右,月流失400个左右
客户打1个客服电话的有1400个左右,客户打2个客服电话的有760个左右,...,总计加起来有3333个
数据的特点是对白天、晚上、夜间,国际都有分钟数、电话数、收费三种维度,以白天为例
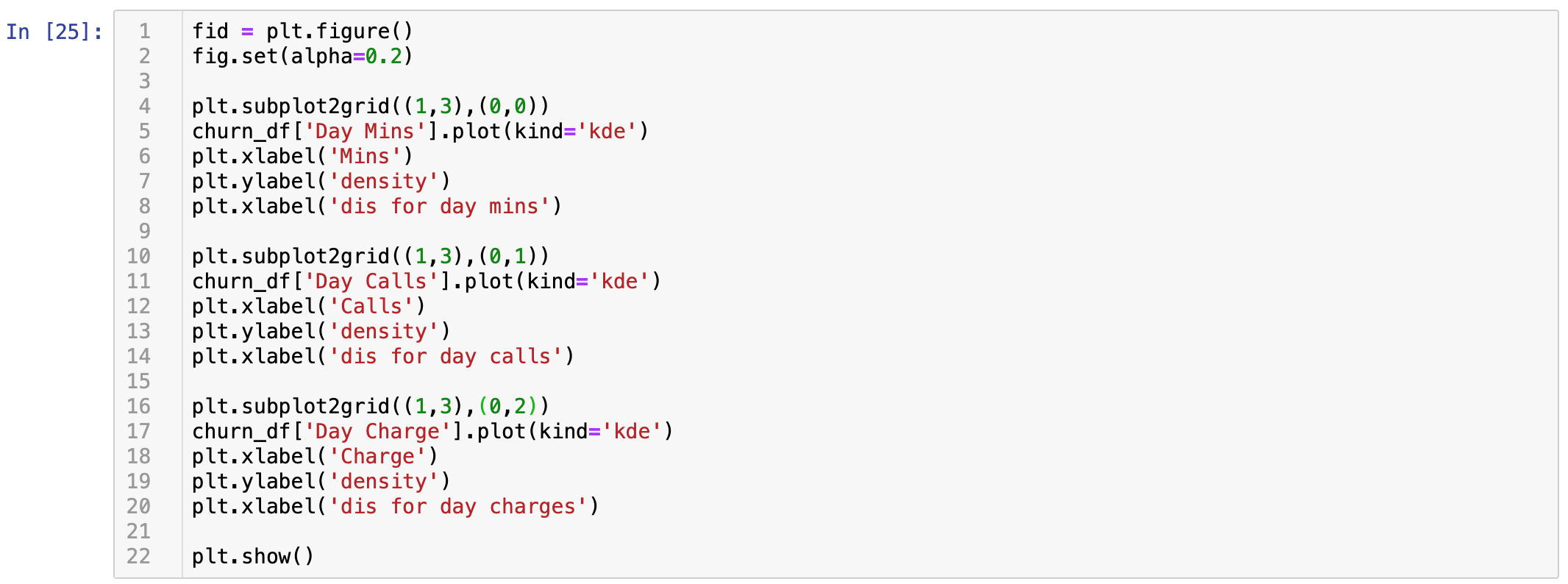
 step2:特征和类别的关联
step2:特征和类别的关联
查看国际漫游服务和结果的关联
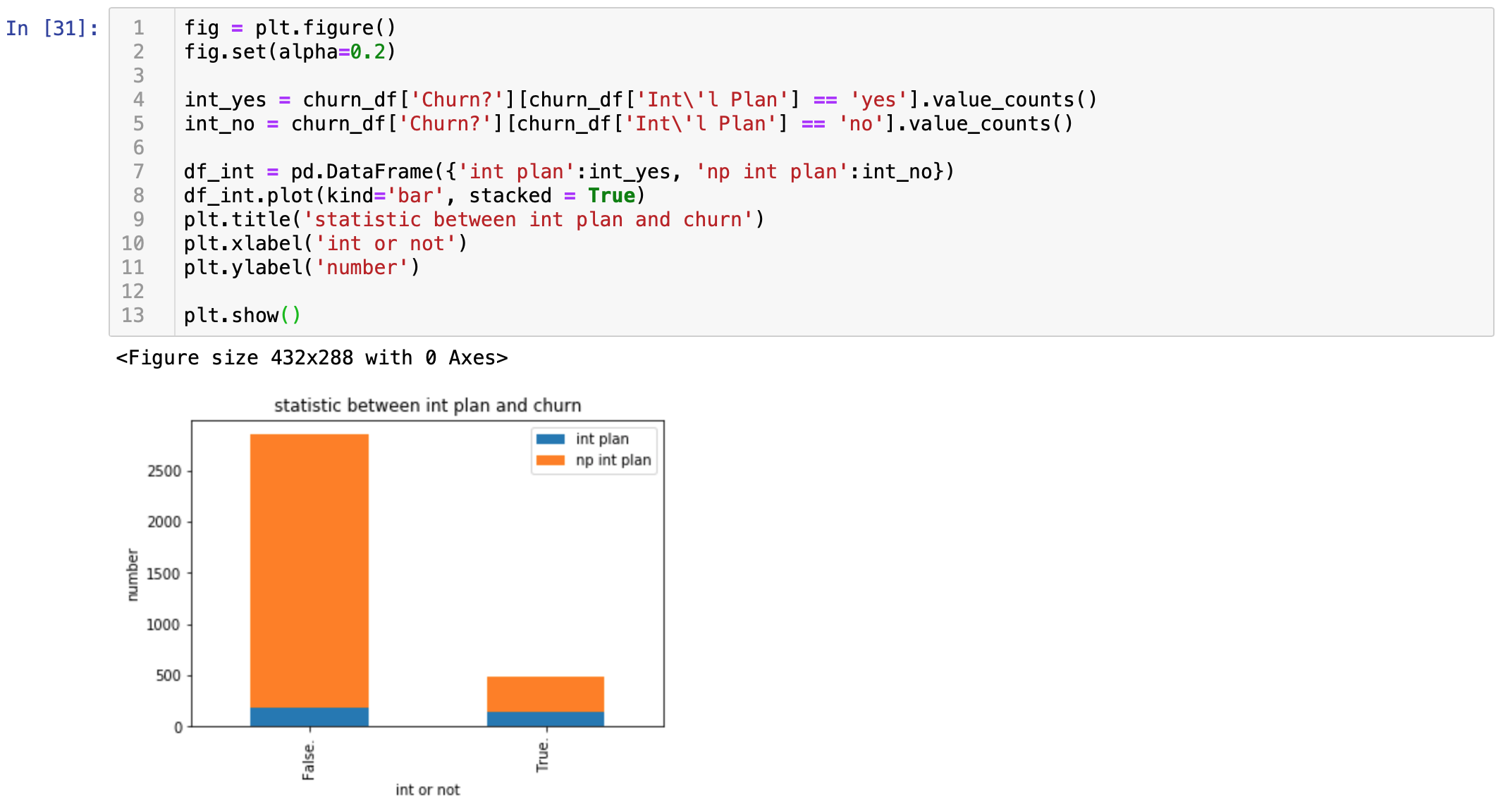
图中流失用户参与国际漫游的比例比没有流失用户中参与国际漫游的比例高,结论:有国际电话的流失比例较高
查看客户服务电话和结果的关联

基本上可以看出,打客服电话的多少和最终分类是强相关的,打电话3次以上的流失率比例急速升高,这是一个非常关键的指标