实验概述
通过本实验学会对整理后的葡萄酒化学成分数据进行分类分析。本实验借助葡萄酒的11种指标并通过线性支持向量机和逻辑回归多分类方法对不同类别的葡萄酒建立模型,检验此模型效果,以此达到通过模型可以预测葡萄酒类别的目的。本实验的源数据可以通过下载附件中的wine_classificatio.csv得到。
实验目的
1.熟练运用阿里云Dataworks大数据计算服务和PAI机器学习平台,对数据进行分类分析,查看葡萄酒的11种指标的分类情况。
2.随机拆分80%数据用来建立模型,剩余的20%数据用来预测评估,并分析模型效果。
实验架构
阿里云大数据计算服务Dataworks + 机器学习平台PAI
第 1 章:实验背景
1.1 maxcompute
请点击页面左侧的 ,在左侧栏中,查看本次实验资源信息。
maxcomputemaxcompute MAXCOMPUTE
在弹出的左侧栏中,点击 创建资源 按钮,开始创建实验资源。
资源创建过程需要1-3分钟。完成实验资源的创建后,用户可以通过 实验资源 查看实验中所需的资源信息,例如:阿里云账号等。
1.2 实验概述
通过本实验学会对整理后的葡萄酒化学成分数据进行分类分析。本实验借助葡萄酒的11种指标并通过线性支持向量机和逻辑回归多分类方法对不同类别的葡萄酒建立模型,检验此模型效果,以此达到通过模型可以预测葡萄酒类别的目的。本实验的源数据可以通过下载附件中的wine_classificatio.csv得到。
1.3 实验目的
-
熟练运用阿里云MaxCompute大数据计算服务和PAI机器学习平台,对数据进行分类分析,查看葡萄酒的11种指标的分类情况。
-
随机拆分80%数据用来建立模型,剩余的20%数据用来预测评估,并分析模型效果。
1.4 实验架构
阿里云大数据计算服务MaxCompute + 机器学习平台PAI
1.5 实验准备
背景知识
一般而言,做分类分析前,都要先对数据进行分类,除非数据种类(等级)完全贴合。然后采用对数据归一化的方法来消除数据的量纲,再对数据进行拆分,取80%数据来根据分类对各因素建立模型,再用剩下的那20%数据去检验模型的准确率。
本实验在常用的二分类方法中选取了支持向量机来对数据进行分析,因为支持向量机(SVM)是寻找稳健分类模型的一种代表性算法。支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(及对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折中,以求获得最好的推广能力。在机器学习中,支持向量机(SVM)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。除去在高维特征空间中用非线性支持向量机进行分类,支持向量机分类用线性分类较多。
本实验采用逻辑回归多分类来对数据进行分析是因为葡萄酒的数据本身带有多分类标签且简单易懂,虽然逻辑回归也可用于二分类分析,但是主要用于疾病分析较多,具体如下:
寻找危险因素:寻找某一疾病的危险因素等;
预测:根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大;
判别:实际上跟预测有些类似,也是根据模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病。
实验资源
本实验需要使用阿里云的MaxCompute资源,具体步骤如下:
【注】本实验均在Google Chrome浏览器下测试运行,为了达到最大兼容,推荐使用Windows7以上的操作系统以及Chrome浏览器进行实验。
【注】一旦开始创建资源,该实验就开始计时,并在到达实验规定的时长时,将自动结束实验并清除资源。
-
在实验的的第一章第一节,可以看到如下画面。点击右上方的我的实验资源按钮来创建MaxCompute资源。
-
- 在弹出的界面上点击创建资源按钮,等待片刻,系统会自动创建好数加子帐号资源。
-
在该页面上可以看到类似于上图的信息,并且页面上会有接下来需要使用的子用户名称与子用户密码。
-
其中点击前往控制台按钮后将在一个新页面中连接到阿里云登录界面,其中,登陆时需要子用户名称以及子用户密码。如图所示,将子用户名称复制粘贴在登陆框中的@符号前,点击下一步。
-
点击子用户密码显示按钮,将登陆密码填充进密码框中,点击登陆。
-
进入管理控制台后,本实验需要使用阿里云的DataWorks产品。在管理控制台左侧导航栏的“产品与服务”中的弹出菜单中,找到大数据(数加)下的“DataWorks”,点击它
-
在此时进入到DataWorks控制台界面, 可以看到系统已经自动创建了一个项目(项目名称是自动生成的随机值),点击”进入数据开发”即可进入到在线IDE环境中
第 2 章:实验详情
2.1 导入数据
1.下载文件
从附件中,下载到本地的csv数据如下所示,一共有4898条数据(不包括列标题):
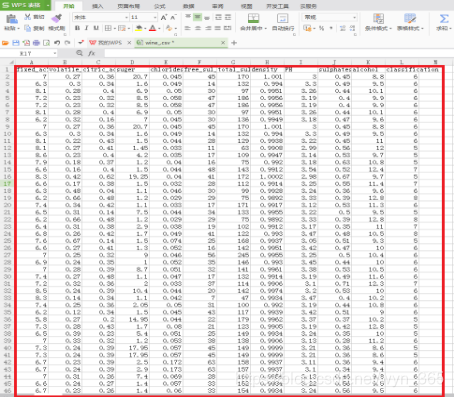
【注】wine_classification红酒数据表主要包含以下变量
固酸 fixed_acidity
挥发酸 volatile_acidity
柠檬酸 citric_acid
糖分 suger
氯化物 chlorides
游离二氧化硫 free_sul_dio
总亚硫酸 total_sul_dio
密度 density
酸碱性 ph
硫酸盐 sulphates
酒精含量 alcohol
分类 classification
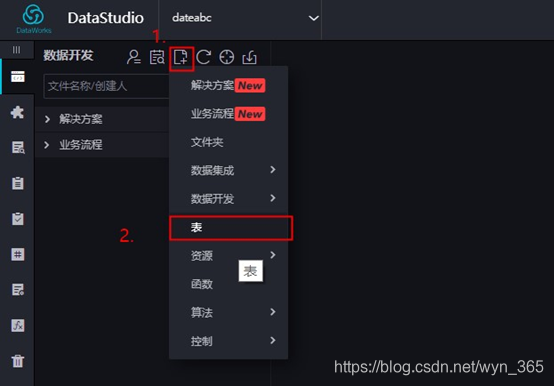
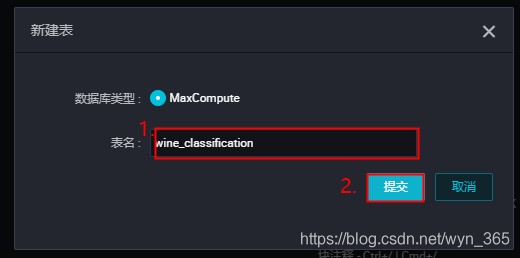
2.首先点击页面左上角的按钮,然后点击“表“。在新建表对话框中输入表名:’ wine_classification’,然后点击“提交”按钮,如下图所示:
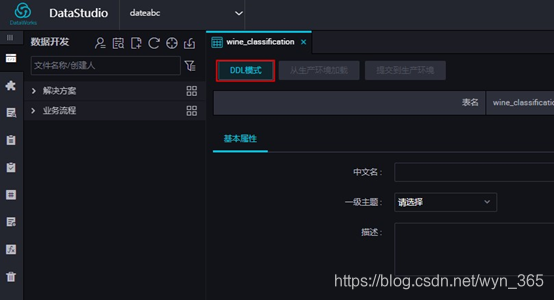
3.点击“DDL模式”,然后在对话框中输入如下建表语句,单击“生成表结构”按钮,然后在确认操作对话框中点击“确认”按钮:
CREATE TABLE wine_classification (
fixed_acidity DOUBLE,
volatile_acidity DOUBLE,
citric_acid DOUBLE,
suger DOUBLE,
chlorides DOUBLE,
free_sul_dio DOUBLE,
total_sul_dio DOUBLE,
density DOUBLE,
ph DOUBLE,
sulphates DOUBLE,
alcohol DOUBLE,
classification BIGINT
);
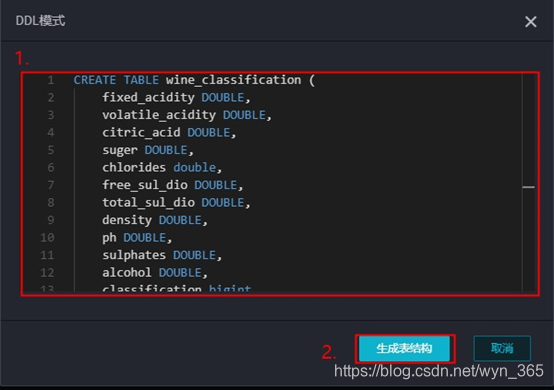
等待运行,如果出现DDL解析成功,则可以在“表结构设计”中查看相应的字段。
4.在基本属性中输入中文名:‘分类分析’,然后单击“提交到生产环境”:
在“提交生产确认“对话框中,勾选‘我已悉知风险,确认提交’,然后点击“确认”按钮:
数据表创建成功后将出现提示‘表提交成功‘:
点击“表管理”按钮即可查看创建完成的表:
5.导入数据
依次点击“数据开发”按钮和“导入”按钮:
选择从附件下载到本地的wine_classification.csv,然后单击“打开”
选择本地文件后会弹出如下对话框。确保首行设置为标题,单击“下一步”。
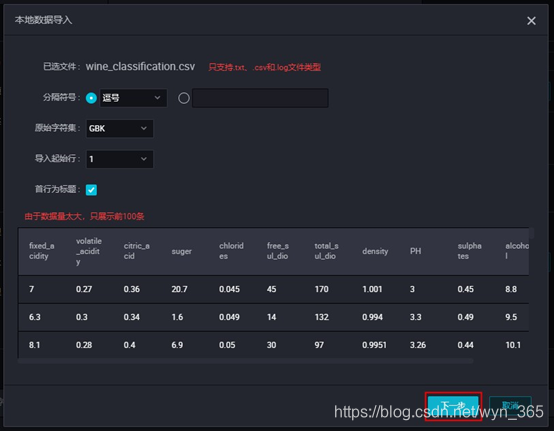
在导入至表的对话框中输入“wine_classification”
选择wine_classification,观察目标字段与源字段是否一一对应,确认无误后单击“导入”
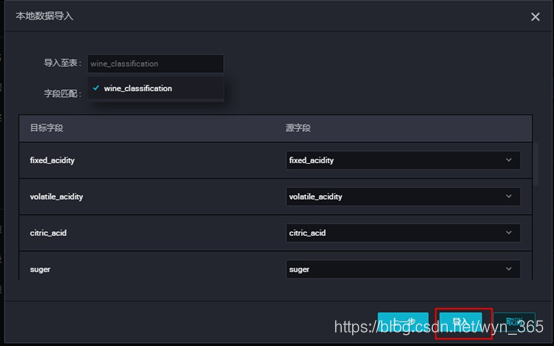
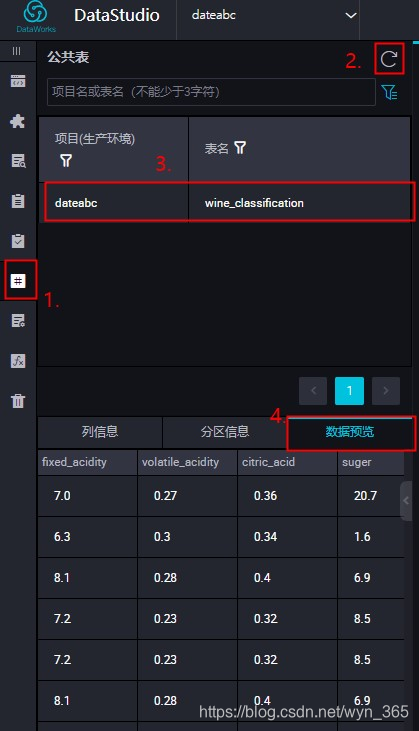
导入成功之后,依次点击“公共表”,“刷新“,”wine_classification“,”数据预览“即可查看刚才创建的表‘wine_classification’中的数据:
2.2 二分类分析
实验介绍
对原始数据上已有的标签(即classification字段,该字段有3-9共7个类别)进行分类,为消除量纲而进行归一化操作后进行切分比例为0.8的拆分,用80%的数据进行分析建模,用剩余20%的数据对建立的模型进行检验,具体通过查看这20%的数据在classification字段上的准确率(即模型预测出的类别和这葡萄酒本身的类别符合程度)的方式明确模型效果。
【注】本步骤将通过阿里云PAI机器学习平台来实现。
实验操作
1.新建实验
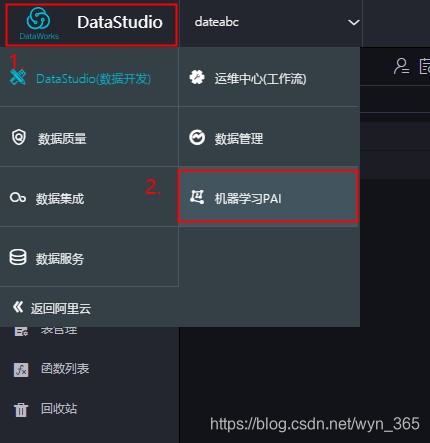
点击左上方的‘DataStuido’图标,然后点击‘机器学习PAI’即可进入机器学习界面:
选择给定项目,单击“进入机器学习”,如下所示
依次点击“新建“,“新建空白实验”,如下所示:
输入实验名称“分类分析”,单击“新建”,如下所示:
【注】本实验中的项目名称是随机生成的一个唯一值,选择可以选择的项目名称即可。
创建完实验后,可以看到窗口被划分为如下几个区域:
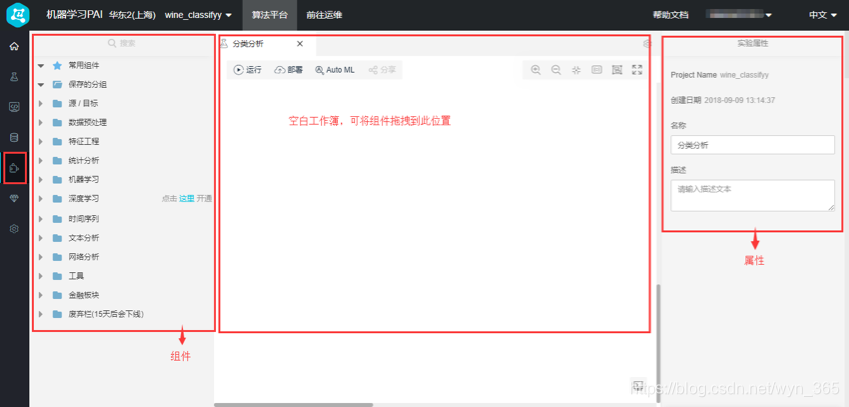
2.阿里云PAI机器学习平台组件说明
【注】本实验中只简单介绍用到的组件,详细的文档请参考https://help.aliyun.com/document_detail/42709.html?spm=5176.product30347.6.544.mOcOZ3
3.读取数据
在最左侧导航栏中单击“组件”,单击“源/目标”,拖动其中的“读数据表”组件到空白处,如下所示:
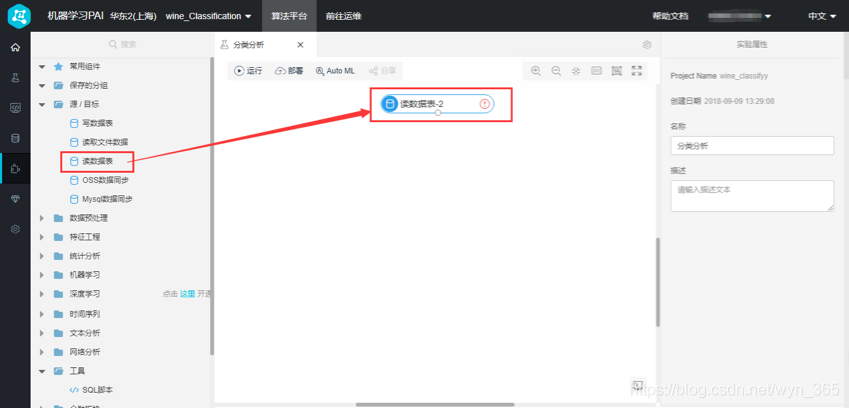
选中已经拖入的“读数据表”组件,在右侧“表选择”栏输入表名为“wine_classification”,读取项目中的wine_classification表。
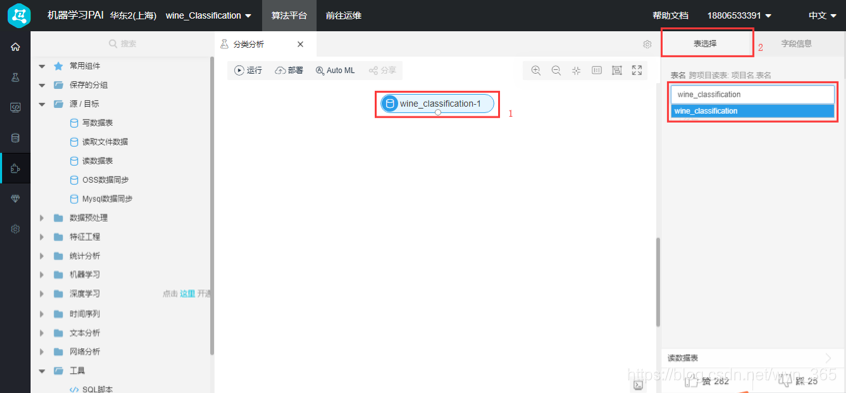
源/目标-读数据表:读取Maxcompute的表数据组件(默认读取本工程下的数据;若读取其他工程的表数据且拥有该project的操作权限,只需在表名前添加工程名,格式:工程名.表名,如:tianchi_project.weibo_data)。
当输入表名后,会自动读取表的结构数据,可点击字段信息查看。MaxCompute表字段修改后,如增加或删除某个字段,在算法平台中是无法感知的,需要用户重新设置一下MaxCompute源,reload一下这个表信息。
4.对数据分类
数据中的classification(分类)字段有3、4、5、6、7、8、9,通过Excel中的筛选可知各类的数据条数(具体操作如下图,以classification=3为例),基于分成的两大类数据数量相近,将分类字段中的3、4、5、6归为一类,7、8、9归为一类
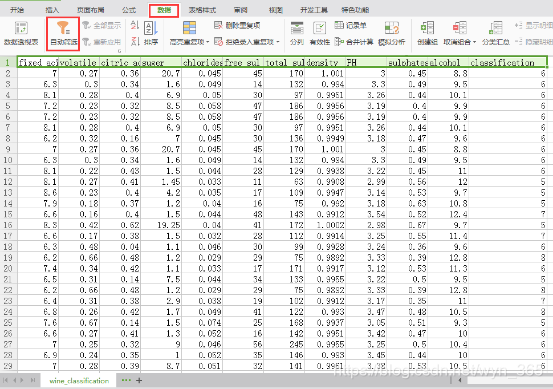
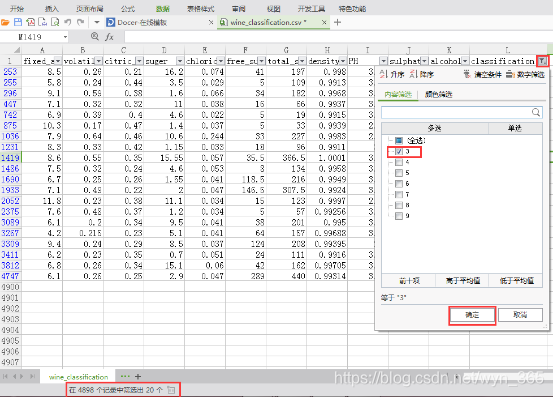
在左侧找到“工具”下的SQL脚本组件,拖入空白处
工具-SQL脚本:用户可通过SQL脚本编辑器编写SQL语句。
构建如下数据流
【注】SQL组件共有4个输入点,注意本次连的是第一个点
【注】点和点之间的连接必须按照下图中的箭头所示
【注】若连线错误可以直接选中连线,按键盘上的“DELETE”键删除
【注】选中一个组件之后可以再次拖动它,调整它的位置,连线之间最好不要交叉
将鼠标移至数据源wine_classification的输出节点
按住鼠标,拖动箭头至SQL脚本组件的输入节点
如此,构建了一个从读数据表到SQL脚本组件的数据流,之后就不再赘述。
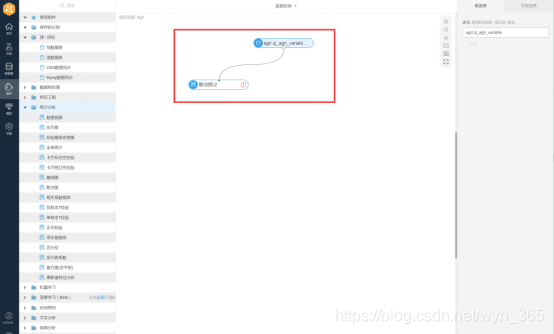
SQL脚本配置,单击SQL脚本组件,将如下代码输入SQL脚本编辑器
select
fixed_acidity,volatile_acidity,citric_acid,suger,chlorides,
free_sul_dio,total_sul_dio,density,ph,sulphates,alcohol,
(case when classification > 6 then 1 else 0 end) as grade
from ${t1}
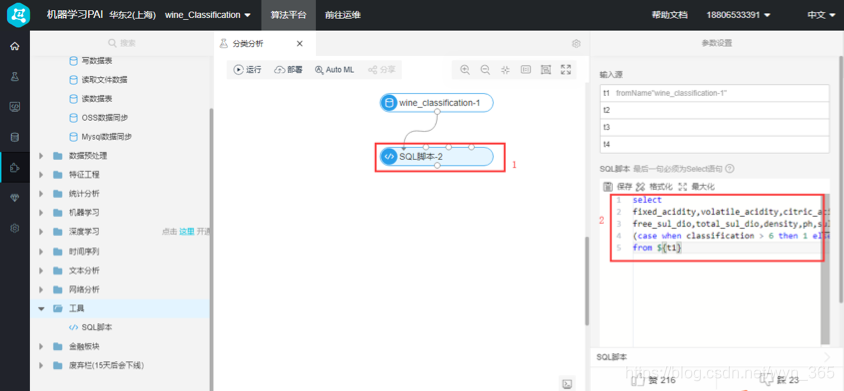
这段代码表示将classification分为3、4、5、6一类和7、8、9一类,分别标为0和1
右键单击SQL脚本组件,选择“执行到此处”,以下就不再赘述这一过程。
执行中的状态,耐心等待
执行过程中或者执行出错时,可以右键单击组件,选择“查看日志”
单击如下的连接即可跳转到日志页面(日志的说明文档参见https://help.aliyun.com/document_detail/27987.html?spm=5176.product27797.6.747.ky2HKF)
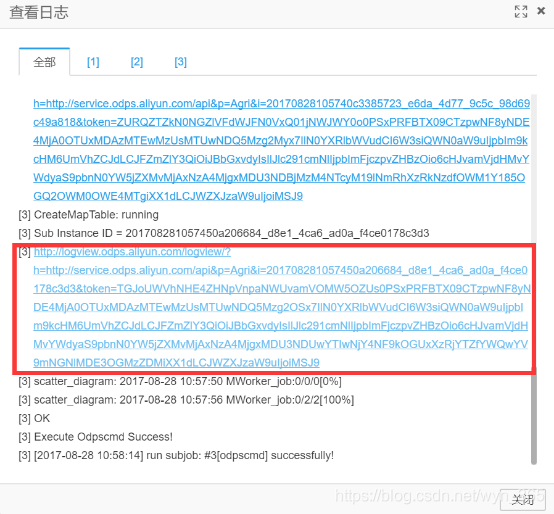
【注】日志有所差异的话是正常的
回到机器学习PAI页面,关闭日志,单击关闭
如果程序已经运行完成,鼠标移入组件,可看到执行成功的状态
右键单击“SQL脚本”组件,执行成功后单击“查看数据”
探查数据:classification已按照要求分为3、4、5、6一类和7、8、9一类,分别标为0和1。
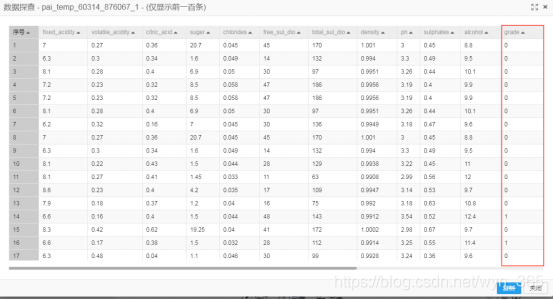
5.对数据进行消除量纲处理
拖入“数据预处理”下的“归一化”组件
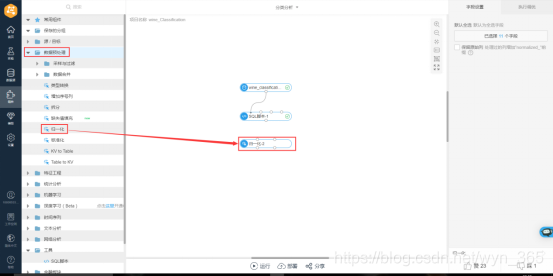
数据预处理-归一化:对一个表的某一列或多列,进行归一化处理,产生的数据存入新表中;目前支持的是线性函数转换,表达式如下:y=(x-MinValue)/(MaxValue-MinValue),MaxValue、MinValue分别为样本的最大值和最小值;归一化属性中可以选择是否保留原始列,勾选后原始列会被保留,处理过的列重命名;在设置属性中点击选择字段按钮可以选择想要归一化的列,目前支持double类型与bigint类型。
如图所示,连接SQL脚本组件与归一化组件后,单击归一化组件,在右侧的“字段设置”标签下单击“选择字段”,如图所示:
选择除grade外的所有字段,点击“确定”,如下所示:
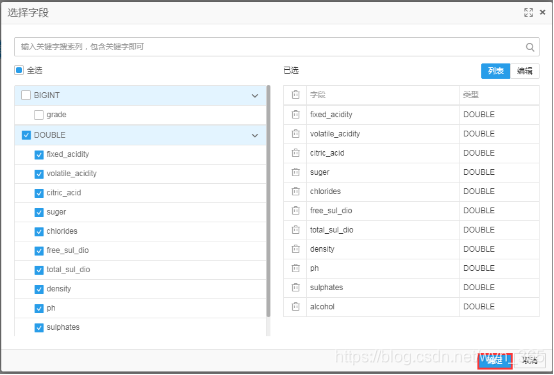
右键点击“归一化”,选择“执行到此处”,执行成功后,如图所示:
右键单击“归一化”组件,执行成功后放在“查看数据”上,单击“查看输出桩1”(或单击“查看输出桩2”)
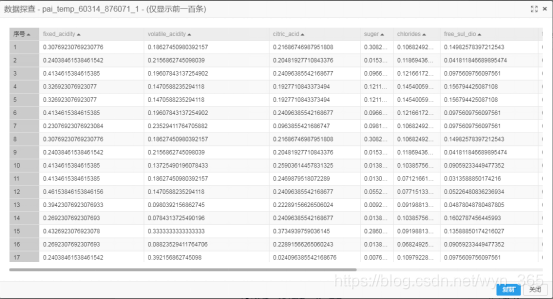
探查数据:下图为输出桩1的数据,即输出结果表,数据的值均为0到1之间。
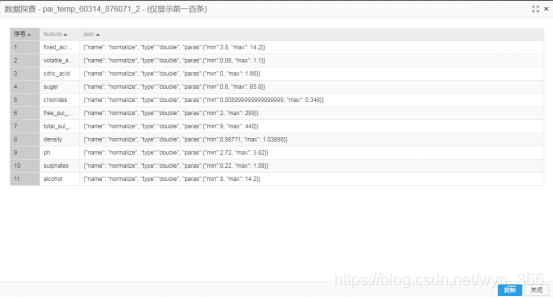
探查数据:下图为输出桩2的数据,即输出参数表,包含了11个要消除量纲的指标。
6.对数据进行拆分
拖入“数据预处理”下的“拆分”组件,并如图连接归一化组件和拆分组件
【注】单击拆分组件,可以看到右边的参数设置,切分比例0.8指所有数据中选取80%的数据来建立模型,剩余的20%数据来进行检验预测模型的准确率。
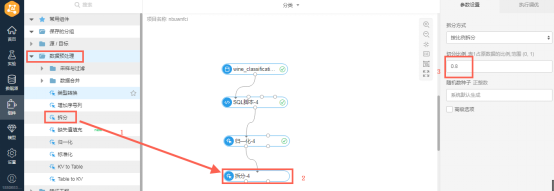
数据预处理-拆分:对输入表或分区进行按比例拆分,分别写入两张输出表。
右键点击“拆分”,选择“执行到此处”,执行成功后,如图所示:
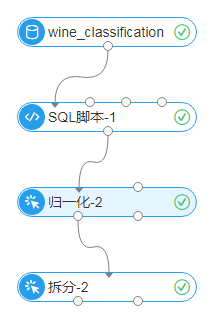
【注】拆分组件有两个输出口,左边输出口为用来建模的80%数据,右边输出口为预测的20%数据。
7.对分类数据进行线性支持向量机、预测和评估
构建如下数据流
拖入“机器学习”下“二分类”下的“线性支持向量机”组件
拖入“机器学习”下“评估”下的“混淆矩阵”组件
拖入“机器学习”下“预测”组件
并如图连接各组件
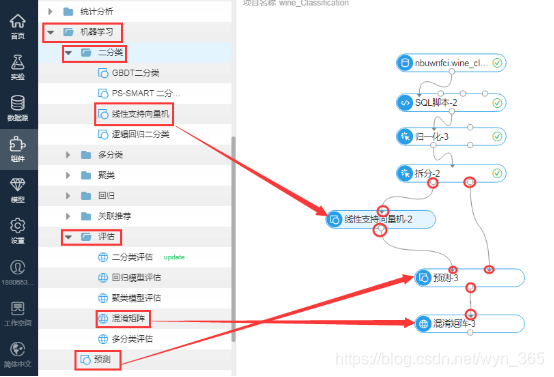
机器学习-二分类-线性支持向量机:支持向量机(SVM)是90 年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。算法的详细介绍可以参考wiki。本版线性支持向量机不是采用核函数方式实现的,具体实现理论详见:http://www.csie.ntu.edu.tw/~cjlin/papers/logistic.pdf 中的6. Trust Region Method for L2-SVM;本算法仅支持二分类。
机器学习-预测:预测组件是专门用于模型预测的组件,它有两个输入:训练模型和预测数据,它的输出为预测结果。 传统的数据挖掘算法一般都采用该组件进行预测操作。
机器学习-评估-混淆矩阵:混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
单击“线性支持向量机”组件,右侧的属性设置中
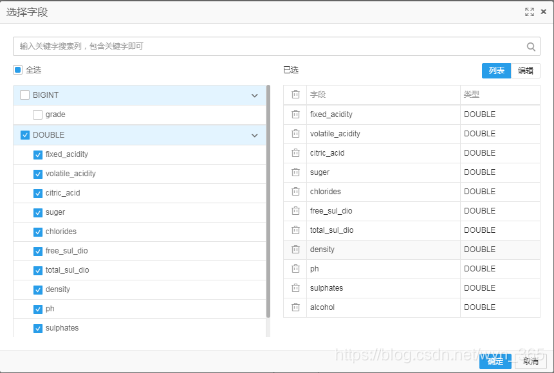
字段设置-特征列
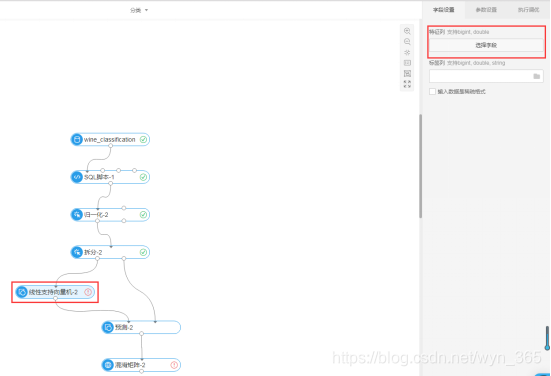
选择除grade外的所有字段,点击“确定”,如下所示:
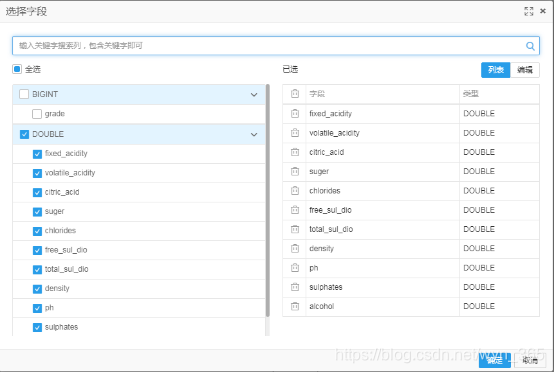
字段设置-标签列:选择grade
单击“预测”组件,右侧的属性设置中
字段设置-特征列
选择除grade外的所有字段,点击“确定”,如下所示:
单击“混淆矩阵”组件,右侧的属性设置中
字段设置-原始数据的标签列列名:选择grade
右键单击混淆矩阵组件,选择“执行到此处”,如图所示:
执行成功后,如图所示:
右键单击混淆矩阵可查看模型预测的评估报告
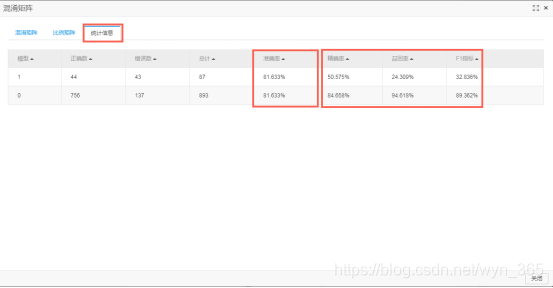
在弹出的窗口中点单击“统计信息”标签,可以看到对grade为1和0分类预测出来的准确率均为81.633%,说明模型的预测性良好,而对于精确率、召回率和F1指标,当grade=0时的模型值远大于grade=1时的模型,所以综合考虑,当grade=0时的模型效果要好于grade=1时的模型。
关闭“混淆矩阵”组件的评估报告。
对上述评估不太明确的,我们还可以拖入“评估”下的“二分类评估”组件,如图所示添加组件、连接预测组件和二分类组件、设置二分类评估组件的原始标签列列名为grade
机器学习-评估-二分类评估:评估模块支持计算AUC,KS及F1 score,同时输出数据用于画KS曲线,PR曲线,ROC曲线,LIFT chart, Gain chart,同时也支持分组评估。
右键单击二分类评估组件,选择“执行该节点”,执行完成后,右键单击二分类评估,选择“查看评估报告”可查看模型预测的评估报告,如图所示:
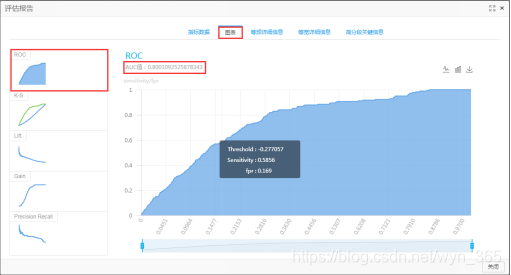
在弹出的窗口中点单击“图表”标签,单击“ROC图”,可以看到AUC值约为0.8(AUC值为ROC曲线下的面积,在0.8-1之间说明模型的预测效果很好),预测结果还是不错的。
2.3 多分类分析
- 构建多分类数据流
组件位置:
机器学习-多分类-逻辑回归多分类
机器学习-评估-多分类评估
参考步骤2中的操作方法,重新拖入所有组件,构建另一个如下数据流,并如图所示连接组件
【注】将线性支持向量机组件用逻辑回归多分类组件代替,二分类评估组件用多分类评估组件代替
机器学习-多分类-逻辑回归多分类:逻辑回归组件支持稀疏、稠密两种数据格式。 逻辑回归多分类最多支持100类。
机器学习-评估-多分类评估:基于分类模型的预测结果和原始结果,评价多分类算法模型的优劣,指标包括Accuracy, kappa, F1-Score等。
- 设置组件属性
单击“SQL脚本”组件,右侧的属性设置中
将如下代码输入SQL脚本编辑器
select
fixed_acidity,volatile_acidity,citric_acid,suger,chlorides,
free_sul_dio,total_sul_dio,density,ph,sulphates,alcohol,
(case when classification > 7 then 1
when classification < 6 then 2
else 3 end) as grade
from ${t1}
这段代码主要将classification中的3-9分成三类,根据数据条数相近,具体为3、4、5一类,6、7一类,8、9一类
执行该节点,并成功运行,如下图所示
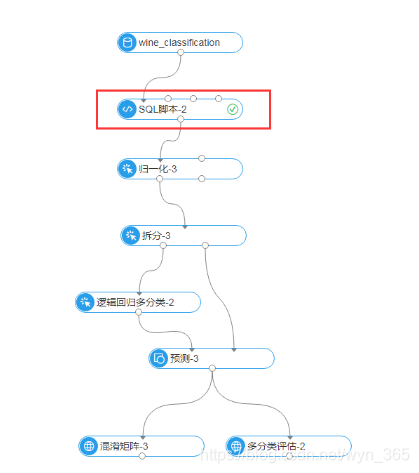
归一化组件、拆分组件的属性设置和步骤2中一致
单击“逻辑回归多分类”组件,右侧的属性设置中
字段设置-特征列
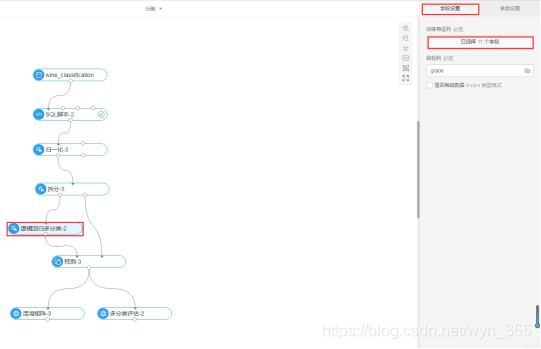
选择除grade外的所有字段,点击“确定”,如下所示:
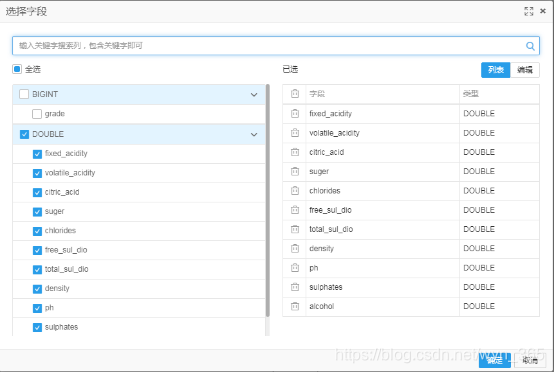
字段设置-标签列:选择grade
测组件、混淆矩阵组件的属性设置和步骤2中一致
单击“多分类评估”组件,右侧的属性设置中
字段设置-原分类结果列设置为grade
右键单击“多分类评估”组件,选择“执行到此处”,如图所示:
右键单击“多分类评估”组件,选择“执行到此处”,如图所示:
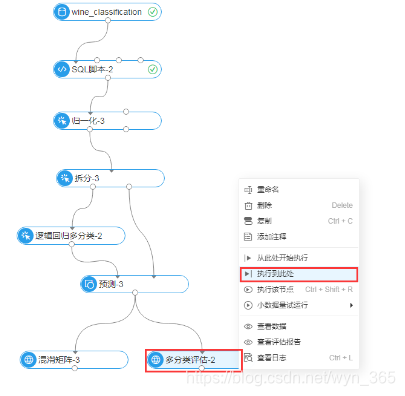
右键单击混淆矩阵组件,选择“执行此节点”,如图所示:
执行成功后,如图所示:
3. 查看评估报告
右键单击混淆矩阵可查看模型预测的评估报告
在弹出的窗口中点单击“统计信息”标签,可以看到对grade为1预测出的准确率为95.918%,grade为2预测出来的准确率为75.714%,grade为3预测出的准确率为71.633%,但是grade=1时模型预测的正确数、错误数均为0,而对于精确率、召回率和F1指标,当grade=3时的模型值大于grade=1和grade=2时的模型,所以综合来看grade=2时的模型预测效果最好,grade=3时次之。
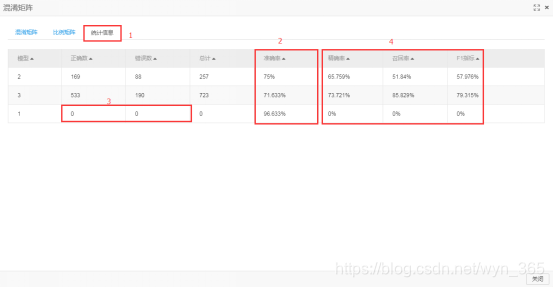
关闭“混淆矩阵评估”组件。
右键单击“多分类评估”组件,选择“查看评估报告”可查看模型预测的评估报告,在弹出的窗口中点单击“统计信息”标签,可以看到结果数据与混淆矩阵的一样,如下图所示:
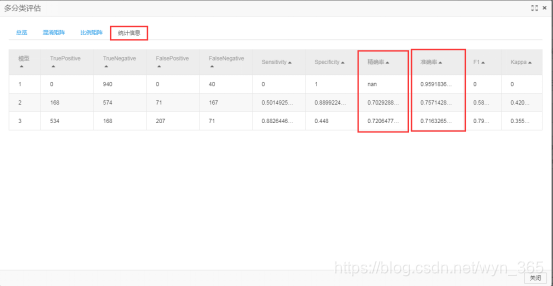
第 3 章:思考与讨论
3.1 思考与讨论
1.如果在对wine_classification数据进行二分类的时候用3、4、5一类和6、7、8、9一类,效果是否会更好?
参考答案
不是,因为这样分类数据量相差有些大,第一类只有1640条数据,而第二类有3258条数据,并且通过PAI上的实验预测出模型的准确率下降了,只有73.061%,所以在对wine_classification数据进行二分类的时候用3、4、5一类和6、7、8、9一类时,效果变差了。
2.支持向量机中除了稳健性外,还能解决什么问题?
参考答案
可以用来解决在高维特征空间中非线性问题。即将低维空间映射到高维空间,在高维空间构造线性边界,再还原到低维空间,从而解决非线性边界问题,即内核上的总和可以被用于测量各个测试点的对数据点始发于一个或者另一个集合中的要被鉴别的相对接近程度。