实验概述
本实验在阿里云PAI机器学习平台上,对一组农业数据进行基本的统计分析,包括观察数据的分布情况,对农民的收入和其他变量的相关性进行分析,对不同区域的农民收入进行分组分析和对比分析,以探讨不同地区的农民之间是否存在收入差异。
实验目标
理解基本统计分析的一些概念的原理和使用方法,运用阿里云PAI机器学习平台上的基本统计分析组件,包括数据视图、相关系数矩阵、箱线图、正态检验、全表统计和双样本T检验等。
实验架构
阿里云大数据计算服务MaxCompute + 大数据开发套件DataIDE+ 机器学习平台PAI
第 1 章:实验背景
1.1 maxcompute
请点击页面左侧的 ,在左侧栏中,查看本次实验资源信息。
maxcomputemaxcompute MAXCOMPUTE
在弹出的左侧栏中,点击 创建资源 按钮,开始创建实验资源。
资源创建过程需要1-3分钟。完成实验资源的创建后,用户可以通过 实验资源 查看实验中所需的资源信息,例如:阿里云账号等。
1.2 实验概述
本实验在阿里云PAI机器学习平台上,对一组农业数据进行基本的统计分析,包括观察数据的分布情况,对农民的收入和其他变量的相关性进行分析,对不同区域的农民收入进行分组分析和对比分析,以探讨不同地区的农民之间是否存在收入差异。
1.3 实验目的
理解基本统计分析的一些概念的原理和使用方法,运用阿里云PAI机器学习平台上的基本统计分析组件,包括数据视图、相关系数矩阵、箱线图、正态检验、全表统计和双样本T检验等。
1.4 实验架构
阿里云大数据计算服务MaxCompute + 大数据开发套件Dataworks+ 机器学习平台PAI
1.5 实验准备
背景知识
统计学研究的对象是客观事物的数量关系和数量特征,是关于数据收集、整理、归纳和分析的方法论科学,是实证研究的一种最重要方法。统计方法广泛地运用于各个领域,起着信息功能、咨询功能、监督功能、辅助决策功能的作用。各个部门要做出决策、执行计划、检查监督、宏观调控等都需要以充分、灵通、可靠的统计资料为基础。
实验资源
本实验需要使用阿里云的MAXCOMPUTE资源,具体步骤如下:
【注】本实验均在Google Chrome浏览器下测试运行,为了达到最大兼容,推荐使用Windows7以上的操作系统以及Chrome浏览器进行实验。
【注】一旦开始创建资源,该实验就开始计时,并在到达实验规定的时长时,将自动结束实验并清除资源。
- 在实验的的第一章第一节,可以看到如下画面。点击右上方的我的实验资源按钮来创建MaxCompute资源。
- 在弹出的界面上点击创建资源按钮,等待片刻,系统会自动创建好数加子帐号资源。
- 在该页面上可以看到类似于下图的信息,包括接下来需要使用的子用户名称与子用户密码。
- 点击前往控制台按钮后将在一个新页面中连接到阿里云登录界面,登陆时需要子用户名称以及子用户密码。如图所示,将子用户名称复制粘贴在登陆框中的@符号前,点击下一步。
- 点击子用户密码显示按钮,将登陆密码填充进密码框中,点击登陆。
进入控制台的界面后,接下来的实验需要进入机器学习平台。在管理控制台左侧导航栏的“产品与服务”中的弹出菜单中,找到大数据(数加)下的“机器学习”,点击它 - 在指定地域下,可以看到系统已经自动创建了一个项目(项目名称是自动生成的随机值),单击【进入机器学习】,如下所示

第 2 章:实验详情
2.1 导入数据
实验步骤
- 新建实验
单击【实验】,再单击【新建实验】,如下所示

单击【新建空白实验】,输入实验名称“基本统计分析”,单击【新建】,如下所示:

【注】 本实验中的项目名称是随机生成的一个唯一值,忽略上图中的“Ecommerce”,选择可以选择的项目名称即可。
创建完实验后,可以看到窗口被划分为如下几个区域:

【注】本实验中只介绍用到的组件,更多详细介绍请参考阿里云官方文档
https://help.aliyun.com/document_detail/42709.html
- 读取数据
【注】本实验将会使用PAI上的公共数据表[pai_online_project].[farm_claim_process]
在最左侧导航栏中单击【数据源】,将【公共表】下的“farm_claim_process”拖入到工作簿的空白处,如下所示:

数据集介绍
具体字段如下

该数据集的原背景:很多农民因为缺乏资金,在每年耕种前会向相关机构申请贷款来购买种地需要的物资,等丰收之后偿还。农业贷款发放问题是一个典型的数据挖掘问题。贷款发放人通过往年的数据,包括贷款人的年收入、种植的作物种类、历史借贷信息等特征来构建经验模型,通过这个模型来预测受贷人的还款能力。
本实验利用机器学习PAI强大的统计分析能力,探索不同地区的农民年收入的分布情况,不同地区的年收入之间是否有区别以及地区与年收入之间的相关性。故claimtype(贷款类型)和claimvalue(贷款金额)这两个字段在本实验中可以不用关心。
2.2 观察分布
这一步将会使用PAI统计分析中的两个组件
【SQL脚本】组件:可通过SQL脚本编辑器编写SQL语句。
【数据视图】组件:可视化了解特征取值分布,特征与标签列的分布情况,了解特征特点方便后续数据分析。
实验步骤
1 数据抽取
这一步需要将之后用到的特征和目标字段从原表中抽取出来,不需要抽取claimtype(贷款类型)和claimvalue(贷款金额)。
点击【组件】,拖入【工具】文件夹下的【SQL脚本】组件

单击该组件,在右侧属性栏中输入如下SQL代码
select id
,region
,farmsize
,rainfall
,landquality
,farmincome
,maincrop
from ${t1}

【注】输入数据会自动映射成t1~t4,使用方式如:select * from ${t1}
连接【ODPS源的输出】和左侧第一个【SQL脚本的输入】,如下图

【注】【SQL脚本】组件共有4个输入点,需要连的是最左侧的第一个点,对应t1。连接错误会导致执行出错。
右键单击【SQL脚本】组件,选择【执行到此处】

进入运行状态

运行成功右键单击【SQL脚本】组件,运行成功时单击【查看数据】
探查数据:region和maincrop明显是字符串特征,而在数值字段中,landquality应该是一个枚举特征,其他则是连续特征

如果运行失败,单击【查看日志】
点击【全部】标签下的最后一段链接即可跳转到日志页面

【注】日志有所差异的话是正常的,日志的详细说明文档参见https://help.aliyun.com/document_detail/27987.html?spm=5176.product27797.6.747.ky2HKF
2 数据转换和透视
从【统计分析】下拖入一个【数据视图】组件,并与【SQL脚本】组件连接,
单击【数据视图】,在右侧的【字段设置】标签下选择farmsize、rainfall、farmincome、region、maincrop作为特征列,landquality作为枚举特征

选择特征列

枚举特征

右键单击【数据视图】选择【执行到此处】,完成后右键单击【数据视图】选择【查看分析报告】

可以看到我们之前选择的5个特征已经通过可视化的方式展现了分布的情况,可以在【字段】列选择查看不同的特征

【数据视图】有两个数据输出表,第一个是数据表,第二个是输出映射表
【数据视图】会对String类字符串做一个统计计算并映射成数字(转换成整数,方便机器学习识别和训练,某种程度有数据格式转换的功能)

右键单击【数据视图】选择【查看数据】,点击【查看输出桩1】可以在数据表中看到,region和maincrop被自动转换

关闭该窗口,右键单击【数据视图】选择【查看数据】,点击【查看输出桩2】可以在输出映射表中看到映射关系

2.3 相关性分析
这一步将会使用PAI统计分析中的一个组件
【相关系数矩阵】组件:相关系数算法用于计算一个矩阵中每一列之间的相关系数,范围在[-1,1]之间。
相关系数是最早由统计学家卡尔·皮尔逊设计的统计指标,是研究变量之间线性相关程度的量,一般用字母 r 表示。由于研究对象的不同,相关系数有多种定义方式,较为常用的是皮尔逊相关系数。
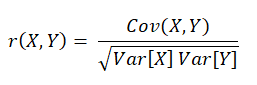
其中,Cov(X,Y)为X与Y的协方差,Var[X]为X的方差,Var[Y]为Y的方差
实验步骤
从【统计分析】下拖入一个【相关系数矩阵】组件
并与【数据视图】组件的输出节点连接,单击【相关系数矩阵】,在右侧的【字段设置】标签下选择farmsize、rainfall、landquality、farmincome、region、maincrop这6个字段


右键单击【相关系数矩阵】选择【执行到此处】,完成后单击【查看数据分析报告】,勾选【显示相关系数】。

在farmincome所在的那一行(所在的行可能不同),可以看到farmincome和farmsize、rainfall 、landquality的相关系数为0.5左右,和region的相关系数只有0.09左右,而和maincrop的相关系数为-0.02。一般来说,取绝对值后,相关系数0-0.09为没有相关性,0.1-0.3为弱相关,0.3-0.5为中等相关,0.5-1.0为强相关。这说明农民的收入和农场的大小、降水量和土地质量有不错的线性正相关关系,和地区与种植的作物基本没有线性相关关系。
2.4 分组分析
这一步将使用PAI统计分析中的【箱线图】,可视化不同地区的农民年收入、降雨量和土地质量,观察数据的偏态和异常值。
箱线图(Boxplot)也称箱须图(Box-whisker Plot),是利用数据中的五个统计量:最小值、第一四分位数、中位数、第三四分位数与最大值来描述数据的一种方法,它也可以粗略地看出数据是否具有有对称性,分布的分散程度等信息,特别可以用于对几个样本的比较。
箱线图主要包含六个数据节点,将一组数据从大到小排列,分别计算出他的上边缘,上四分位数(或第三四分位数)Q3,中位数Q2,下四分位数(或第一四分位数)Q1,下边缘,还有一个异常值。

第三四分位数与第一四分位数的差距又称四分位间距(Inter Quartile Range,IQR)。
四分位间距框的顶部线条是第三四分位数的位置,即Q3,表示有75%的数据小于等于此值。底部线条是第一四分位数的位置,即Q1,表示有25%的数据小于此值。整个四分位间距框所代表的是数据集中50%(即75%-25%)的数据,四分位间距框的高度就是这些数据涉及的范围,能够表现出数据的集中程度。Q2是数据中位数的位置。
箱形图的作用
1 识别数据异常值:一批数据中的异常值值得关注,忽视异常值的存在是十分危险的,不加剔除地把异常值包括进数据的计算分析过程中,对结果会带来不良影响;重视异常值的出现,分析其产生的原因,常常成为发现问题进而改进决策的契机。
2 比较几批数据的形状:同一数轴上,几批数据的箱形图并行排列,几批数据的中位数、尾长、异常值、分布区间等形状信息便一目了然。
箱线图的局限
1 不能提供关于数据分布偏态和尾重程度的精确度量
2 对于批量比较大的数据批,反应的形状信息更加模糊
3 用中位数代表总体评价水平有一定的局限性
实验步骤
从【统计分析】下拖入一个【箱线图】组件并与【数据视图】组件的输出节点连接,单击【箱线图】,在右侧选择farmsize、rainfall、landquality、farmincome这4个变量作为连续类型特征,选择region作为枚举类型特征

选择连续类型特征

右键单击【箱线图】选择【执行到此处】,完成后单击【查看分析报告】

以farmincome为例, 按照region分成了4组,并显示了每组中的数据分布情况。整体上看,4个地区的收入中位数和下边缘都比较接近,其中1和2地区的下四分位数比较低一点,3和4地区的下四分位数稍高一些。但是上四分位数和上边缘就有差距了,2和3的上四分位数和上边缘比较高一些。总体而言,2和3地区的收入分布相对1和4地区比较分散一些,最高收入也高一些。
2.5 对比分析
使用PAI统计分析中的【正态检验】组件,检验不同地区的农民年收入是否符合正态分布。如果符合,使用PAI统计分析中的【全表统计】组件计算地区的年收入方差,然后用F检验确定不同地区的年收入方差没有显著性差异之后,最后用【双样本T检验】检验不同地区的农民年收入均值是否存在显著性差异。
【正态检验】组件:检验观测值是否服从正态分布,本组件由三种检验方法组成,包括Anderson-Darling Test,Kolmogorov-Smirnov Test以及QQ图,用户可以自选某一种或多种检验方法。原假设H0:观测值服从正态分布,H1:观测值不服从正态分布(KS的p值计算方法采用渐进计算KS分布的CDF,无论样本量多大都采用的是该方法。QQ图在样本量>1000时,会采样进行计算和画图输出,因此图中的数据点不一定覆盖所有样本)
【全表统计】组件:对一个存在的表,进行全表基本统计,或者仅对选中的列做统计。输出统计结果的全部字段如下

【双样本T检验】组件:T检验分为单样本检验和双样本检验。
单样本T检验是检验一个样本平均数与一个已知的总体平均数的差异是否显著。
双样本T检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。
双样本T检验又分为两种情况,一是独立样本T检验,一是配对样本T检验。
独立样本T检验就是根据样本数据对两个样本来自的两个独立总体的均值是否有显著差异进行推断;进行独立样本T检验的条件是,两个样本的总体相互独立且符合正态分布。
配对样本是指对同一样本进行两次测试所获得的两组数据,或对两个完全的样本在不同条件下进行测试所得到的两组数据;配对样本T检验的前提条件:两样本是配对的(数量一样,顺序不能变),服从正态分布。
T检验的前提:
1.来自正态分布总体
2.随机样本
3.均数比较时,要求俩总体方差相等,即具有方差齐性(需要使用F检验)
F检验
F检验又叫方差齐性检验,在双样本T检验中要用到F检验。从两总体中随机抽取样本,要对这两个样本进行比较的时候,首先要判断两总体方差是否相同,即方差齐性。
若两总体方差相等,则直接用T检验,若不等,可采用T’检验或变量变换或秩和检验等方法。
F检验法是英国统计学家Fisher提出的,主要通过比较两组数据的方差V,以确定他们的精密度是否有显著性差异。
F检验的计算方法:
F检验的原假设总是假设两个方差是相等的。
步骤1:写出假设陈述
H0:方差无显著差异。
H1:方差有显著差异。
步骤2:计算的F临界值
把大的方差作为分子,小的方差作为分母,相除得到F临界值
步骤3:计算自由度
表中的自由度是样本大小- 1
步骤4:选择alpha大小
使用0.05的alpha(默认情况下),双尾检验需要减半,所以使用0.025。
步骤5:使用以下这张表格找到F临界值(这张表只适用于alpha=0.025)
横坐标df1是大方差(分子)的自由度,纵坐标df2是小方差(分母)的自由度。有很多个表,所以请确保在alpha = 0.025表中查找。
步骤6:比较计算值(步骤2)和表值(步骤5)
如果计算值高于表值,则可以拒绝原假设。

本实验比较1和4地区的收入是否有显著差异,将采用独立样本T检验,需要两个样本满足正态分布和方差齐性。
实验步骤
从【工具】文件夹下拖入一个【SQL脚本】组件,连接【数据视图】组件的输出,并在右侧属性栏中输入如下SQL代码
select * from ${t1} where region = 1

右键单击【SQL脚本】选择【执行到此处】,完成后单击【查看数据】

从【统计分析】下拖入一个【正态检验】组件, 与【SQL脚本】组件的输出连接,在右侧的【字段设置】标签下选择farmincome作为字段列

选择字段列

右键单击【正态检验】选择【执行到此处】,完成后单击【查看分析报告】

【注】本实验用Kolmogorov-Smirnov Test来判断样本是否符合正态分布
KS Test的p-value大于0.05,不能拒绝原假设H0(观测值服从正态分布),所以地区1的收入服从正态分布。
从【统计分析】下拖入一个【全表统计】组件, 与【SQL脚本】组件的输出连接,在右侧的【字段设置】标签下选择farmincome作为输入列

选择输入列

右键单击【全表统计】选择【执行到此处】,完成后单击【查看数据】,找到“variance”列,将鼠标移入数据

地区1的收入方差为93141790665.90714
按住键盘上的【CONTROL】键,选中【SQL脚本】、【正态检验】和【全表统计】这三个组件,在其中的任意一个组件上右键单击,选择【复制】(注意选中的三个节点会变成淡蓝色)

在工作簿空白处右键单击,选择【粘贴节点】,连接【数据视图】的输出和【SQL脚本】的左侧第一个输入,在【SQL脚本】的参数设置中,将SQL语句修改为如下语句
select * from ${t1} where region = 4

右键单击【SQL脚本】,选择【从此处开始执行】

执行完成后,右键单击【正态检验】,选择【查看分析报告】
KS Test的p-value大于0.05,不能拒绝原假设H0(观测值服从正态分布),所以地区4的收入也服从正态分布。
右键单击【全表统计】,选择【查看数据】,找到方差

地区4的收入方差为87874342403.63077
之前计算得到的地区1的收入方差为93141790665.90714
【注】接下去用F检验(方差齐性检验)来判断方差是否有显著性差异,原假设为两个地区的方差没有显著差异。
右键单击两个【全表统计】,选择【查看数据】,找到两组数据的样本数
地区1共93个样本

地区4共43个样本
F 计算值= 93141790665.90714 / 87874342403.63077 = 1.06
查看双尾检验查alpha等于0.025的表,横坐标为大方差的自由度为42,纵坐标为小方差的自由度为92
42介于40到60之间,92介于60到120之间,F表值为1.53 到 1.74之间。
F 计算值= 1.06 < F表值,不能拒绝原假设,所以两组数据的方差没有显著差异
为了防止下一步产生交错的数据连线,可以调整一下组件的位置
从【统计分析】下拖入一个【双样本T检验】组件,与两个【SQL脚本】组件的输出连接,并在右侧的【字段设置】标签下选择farmincome作为样本1和样本2所在列,在【参数设置】标签下选择【置信度】为0.95,【两总体方差是否相等】为tru
参数设置
右键单击【双样本T检验】选择【执行到此处】,完成后单击【查看数据】
回顾一下假设
H0:两个样本均值的差等于0
H1:两个样本均值的差不等于0
【双样本T检验】的结果中可以看到p value是0.39,大于alpha(0.05),不能拒绝原假设H0,所以地区1和地区4的收入均值没有显著性差异。
附:最终的任务流图

第 3 章:思考与讨论
3.1 思考与讨论
- 分组分析和对比分析有哪些应用场景?
参考答案
A/B test:将某一个度量按照一个离散的维度分组之后,取其中的两组,一组是控制组,保持原有策略不变;另一组为实验组,采取新的策略。实验后收集两组的数据并进行对比分析,看实验组结果是否显著优于对照组。如果有,则证明策略有效。
- 如何判断某一个服从正态分布的样本平均值是否小于一个已知的总体平均数?
参考答案
先判断方差是否相等,然后使用单样本T检验,假设类型为单尾
- 独立样本T检验和配对样本T检验的差异在哪里?
参考答案
前者要求两样本相互独立,后者要求两样本相互配对;
前者需要考虑方差相等或不等两种情况,而后者方差通常是不等的。
- 通过相关系分析之后发现,两个变量之间有很高的相关性,是否能说明这两个变量之间有因果关系?
参考答案
不能。相关性分析只能说明变量之间存在关联性,但关联性不等于因果关系。可能是其他没有被考虑进来的变量同时影响了这两个变量。举个例子,A的年龄和B的年龄都同时在增长,具有非常高的相关性,但是这两个变量之间毫无因果关系,只不过都是受了时间的影响。
总之,如果两个变量之间存在相关关系,则意味着当一个变量发生系统性变化时,另一个变量也会发生系统的变化,可以是正的或负的。
如果一个变量与另一个变量同时增加,则存在正相关关系,即一个变量的高数值与另一个变量的高数值有关。
如果一个变量在另一个变量增加时减小,那么一个变量的高数值与另一个变量的低数值有关。