F-PointNets
论文:《Frustum PointNets for 3D Object Detection from RGB-D Data》
Abstract
利用RGB-D进行目标检测。尽管之前的方法集中在图像或者3D体素上,常常掩盖自然3D模式和3D数据的不变体,但是我们通过RGB-D扫面直接操作原始点云。但是,这个方法的关键在于如何在大范围扫描(区域候选框)的点云中高效的局部化物体。相比于单独依赖于3D候选区域,我们的方法利用预训练好的2D目标检测器和先进的3D深度学习来进行目标局部化,达到即使是对于小目标而言也是高效和高召回率的。
Introduction
关键问题:如何在3D空间中高效地推出目标的可能位置。
- 直接使用3D RPN网络,但是对于3D来说,这个计算量巨大,不适用于自动驾驶的实时场景;
- 我们提出了减少搜索空间的方法:我们首先利用成熟的2D目标检测网络获取2D 候选区域,利用矩阵转换得到3D 边界视锥图。利用修剪后的3D空间,我们通过PointNet网络的两个变体(3D实力分割网络和3D边界框评估网络)获取3D目标实例分割和3D边界框回归。
Related Work
RGB-D数据的目标检测的方法:
-
基于前视图的方法
-
基于鸟瞰图的方法
- MV3D就是将3D激光雷达投影到鸟瞰图,并为获取3D边界候选框训练RPN网络。该方法在检测行人和自行车等小物体上表现不足,而且在垂直方向上有多物体时,表现也不理想。
-
基于3D的方法
- 《Sliding shapes for 3d object detection in depth images》在通过点云中抽取的手动设计的几何特征上利用SVM训练3D目标分类器,之后利用滑动窗口搜索定位目标;
- 《Fast object detection in 3d point clouds using efficient convolutional neural networks》利用体素的3D网格进行3D CNN替换上述的SVM,进行分类;
- 《Three-dimensional object detection and layout prediction using clouds of oriented gradients》设计新的几何特征用于预测点云的3D目标检测;
- 《 Deep sliding shapes for amodal 3d object detection in rgb-d images》将整个场景的点云转换为体积网格和使用3D CNN进行目标推荐和分类。
Problem Definition
给定RGB-D数据作为输入,我们的目标是对3D空间的目标进行分类和定位。
深度数据是通过激光雷达或者室内深度传感器获取,通过点云在RGB相机的坐标中展示。投影矩阵也是已知的,所以我们能够从2D图像区域获取3D视锥图。每个目标都是通过一类(预定义的k类)和3D边界框展示。即使物体的一部分被遮挡或者截断,也是可以通过边界框完全展示的。
3D边界框的参数如下:
高宽长: h , w , l h, w, l h,w,l
中心点: c x , c y , c z c_x, c_y, c_z cx,cy,cz
方向: θ , ϕ , ψ \theta, \phi, \psi θ,ϕ,ψ
在操作中,我们只需要考虑围绕向上坐标轴的 θ \theta θ角即可。
3D Detection with Frustum PointNets
目标检测由以下三部分组成:Frustum Proposal, 3D Instance Segmentation, Amodal 3D Box Estimation

思路:
首先输入RGB图像,利用2D检测网络提取2d region proposal,之后通过和输入的点云进行矩阵转换,得到Frustum Proposal。之后再frustum中利用PointNet网络进行3D语义分割,缩小proposal的3d空间,最后利用T-Net对坐标进行归一化,并再使用PointNet网络,评估3D bounding box参数。

Frustum Proposal
根据已知的相机投影矩阵,一个2D的边界框能够推广到一个锥视图(通过深度传感器的范围指定的近距离和远距离的平面)。我们之后利用锥视图收集所有的点形成一个锥视图点云。锥视图可能朝向不同的方向,这将会导致点云位置较大的变化,如图(a)所示。因此我们通过将它们朝向一个中心点视角进行旋转,进而归一化锥视图,以便于锥视图的中心轴正交于图像平面,如图(b)所示。归一化有利于提升算法的旋转不变性。这个过程成为frustum proposal generation。
2D region proposal是基于FPN模型,采用的是在ImageNet分类和COCO目标检测数据集的预训练参数,并在KITTI的2D目标检测数据上进行微调,达到分类和预测2D边界框的目的。
3D Instance Segmentation
由于在3D上进行分割要比图像上更加自然,因为在像素上距离较远的位置,在点云上比较近。基于这个原因,我们提出对3D点云进行实例分割,而不是2D图像或者是深度映射。类似于Mask-RCNN,它在图像领域对像素进行二分类进而达到实例分割,我们利用基于PointNets网络对锥视图的点云进行3D实例分割。
基于3D实例分割,我们能够达到基于残差的3D定位。我们预测了局部坐标系系统的3D边界框中心—3D mask coordiantes,如上图©所示。
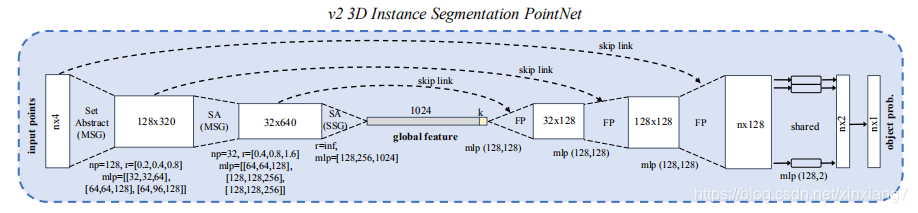
3D Instance Segmentation PointNet
这个网络取锥视图中的一个点云,并预测每个点的可能分数,这个表示有多大可能这个点属于感兴趣的目标。需要注意的是每个锥视图只包含一个感兴趣的目标。和2D实例分割一样,在一个锥视图的目标点可能在另外一个锥视图中被遮挡或者混乱。因此,我们的分割PointNet学习遮挡和混乱模式以及识别某一类目标的几何体。
经过3D实例分割,分类为感兴趣物体的点云被提取出来(如图中的masking)。之后将进一步归一化它的坐标来提升算法的平移不变性。在我们的操作中,我们利用质心减去XYZ坐标值进而将点云平移到局部坐标系中。如图©所示。需要注意的是,我们不缩放点云,因为部分点云的边界球尺寸会受到视角的巨大影响,而且点云的真实大小有利于边界框的尺寸评估。
在实验中,我们发现坐标平移,比如上述以及之前的锥视图旋转对于3D目标检测的结果起到了关键的作用。如下表所示:

v1和v2版本的网络结构如下图所示:

Amodal 3D Box Estimation
给定分割的目标点云(在3D mask coordinate),这个模型利用带有预训练的transformer网络的边界框回归PointNet评估目标的3D边界框。
利用T-Net进行基于学习的3D对齐
尽管我们根据它们的中心位置,已经对齐了分割的目标点,但是我们发现掩码坐标框架的初始点(Fig.©)和模型的边界框中心相差较远。
因此,我们提出了利用轻权重的回归PointNet(T-Net)来评估全部目标的真实中心,之后再平移坐标,使得预测的中心点成为初始点(Fig.(d))。
这个结构和我们的T-Net网络的训练类似于文章中的《Pointnet: Deep learning on point sets for 3d classification and segmentation》的T-Net,可以看成是一种特殊的STN网络。
T-Net网络如下图所示:

3D 边界框评估的PointNet
在3D目标坐标系中(fig.(d))中给定一个目标点云,边界框评估网络预测边界框(对于整个物体,包括看不见的部分)。这个网络类似于目标分类,但是输出不再是目标类的分数,而是3D边界框的参数。
如上述所说, 我们的3D边界框的参数有中心点 ( c x , c y , c z ) (c_x, c_y, c_z) (cx,cy,cz),尺寸 ( h , w , l ) (h,w,l) (h,w,l)基于前进的旋转角 ( θ ) (\theta) (θ)。对于边界框的中心评估,我们采用了残差法。由边界框预测网络预测的中心残差结合了之前的由T-Net得到的中心残差和编码的中心,进而得到完全的中心。公式如下:
C p r e d = C m a s k + △ C t − n e t + △ C b o x − n e t C_{pred} = C_{mask} + \triangle C_{t-net} + \triangle C_{box-net} Cpred=Cmask+△Ct−net+△Cbox−net
对于边界框的尺寸和前进角,我们采用了之前的网络,使用分类和回归方程的混合。具体来说,我们预先定义了一个NS大小的模板和NH等分角箱。我们的模型对那些预先定义的分类进行尺寸和heading分类(NS对尺寸打分,NH对heading打分),同时对每个种类的残差数量(对高、宽和长度的3xNS残差方向,heading的NH残差角度)。最后,这个网络总的输出数量为3+4xNS + 2xNH.
边界框评估网络的PointNet:


Training with Multi-task Losses
我们同时优化3个网络涉及多任务损失。
3个网络:
3D 实例分割PointNet;
T-Net;
边界框评估PointNet.
L m u l t i − t a s k = L s e g + λ ( L c 1 − r e g + L c 2 − r e g + L h − c l s + L h − r e g + L s − c l s + L s − r e g + γ L c o r n e r ) L_{multi-task} = L_{seg} + \lambda(L_{c1-reg}+L_{c2-reg}+L_{h-cls}+L_{h-reg}+L_{s-cls}+L_{s-reg}+\gamma L_{corner}) Lmulti−task=Lseg+λ(Lc1−reg+Lc2−reg+Lh−cls+Lh−reg+Ls−cls+Ls−reg+γLcorner)

其中 L c 1 − r e g L_{c1-reg} Lc1−reg是T-Net;
L c 2 − r e g L_{c2-reg} Lc2−reg是边界框评估网络中心点回归损失;
L h − c l s L_{h-cls} Lh−cls和 L h − r e g L_{h-reg} Lh−reg是前进角预测的损失;
L s − c l s L_{s-cls} Ls−cls和 L s − r e g L_{s-reg} Ls−reg是边界框尺寸;
S o f t m a x Softmax Softmax用于所有的分类任务, s m o o t h − L 1 smooth-L1 smooth−L1损失用于所有的回归任务中。
边界框参数的联合优化的角损失
当我们的3D边界框参数是紧实和完整的,对于最终的3D边界框准确率的学习并不是最优的,中心点、尺寸和前进方向有分开的损失项。假设这样一种情况,中心点和尺寸都准确的预测到了,而前进角偏差较大,这个和真实边界框的3D IoU将会被角度偏差而主导。理想情况下,三项(center, size, heading)应该联合优化以便于得到最优的3D边界框评估(在IoU指标下)。为了解决这个问题,我们提出了一个新颖的正则化损失,corner loss:

这个corner loss是预测框和真实边界框的八个角的距离和。因为角的位置取决于center,size,heading的联合作用,所以corner loss可以正则化这些参数的多任务训练。
为了计算corner loss,我们首先从所有尺寸的模板和前进角箱中构建NS * NH个锚定。之后将锚定平移到评估边界框的中心。我们将锚定边界框的角标定为 P k i j P_k^{ij} Pkij,i,j,k分别表示尺寸类,前进角类和(预定义的)角的类别。为了避免反转前进评估较大的惩罚,我们进一步计算了翻转真实边界框的角的距离( P ∗ ∗ k P^**_k P∗∗k),并且使用原始和翻转的情况的最小值。 δ i j \delta_{ij} δij表示真实尺寸/前进类和0的其中一种,是一个用于选择我们关心的距离项的二维掩码。
Experiment
实验主要分为三个部分:
- 对比在KITTI数据集和SUN-RGBD数据集上3D目标检测最好的方法;
- 验证我们设计选择的深度分析;
- 量化结果,并讨论方法的优缺点;
和当前最好的方法进行对比
KITTI
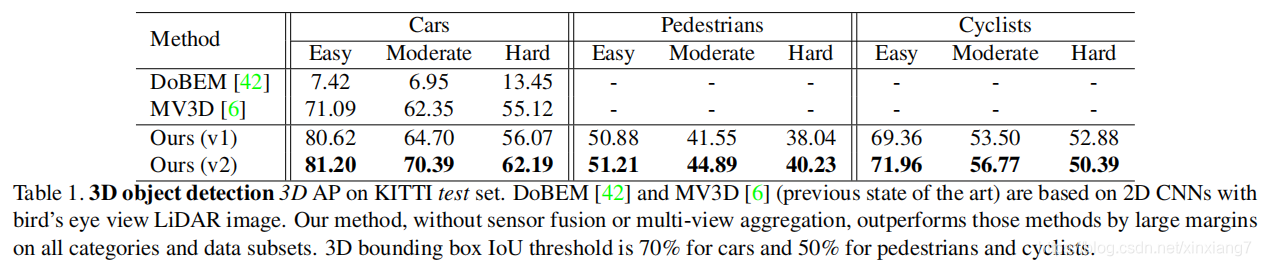
比MV3D 高出很多,而且我们的方法基于PointNet(v1)和PointNet++(v2)的backbone更为干净。而且相信进行传感器融合能够更进一步提升结果。
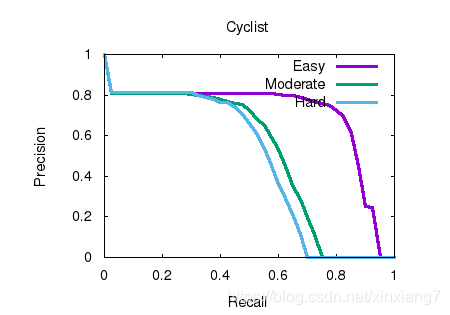
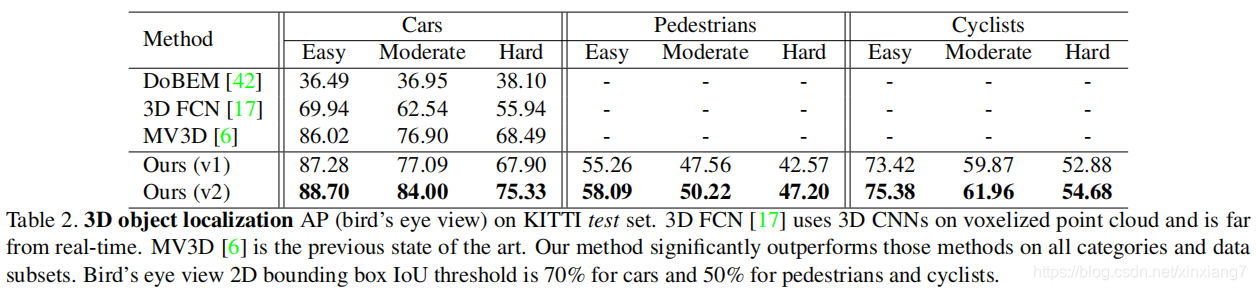
通过3D目标定位(BEV)也是遥遥领先:
结构设计分析
Comparing with alternative approaches for 3D detection
不同数据对比:

2D mask与3D mask对比如下图所示:

由上图可知3D mask 这个阶段起到了非常重要的作用。而2D+3D反而将2D中较大的误差加入到3D中,所以误差比只使用3D mask的准确率更低。
Effects of point cloud normalization

由上表可以看出frustum rotation、mask centralizaion起到了关键作用,目标中心点的平移也能有助于提升准确率。
Effects of regression loss formulation and corner loss

上图可以看到各类损失对于提升准确率的作用。
量化结果和讨论
优点:
- 在没有遮挡,而且合适的距离的情况下,我们的模型输出显著准确的3D实例分割掩码和3D边界框;
- 我们的模型甚至能够预测只有部分数据的3D边界框;
- 对于在2D图像中重叠的目标,在3D空间中,变得容易定位。
缺点:
- 在稀疏点云中(有些情况是少于5个点)常常由于不准确的姿势和尺寸导致常识性的错误。我们认为图像特征可以提供很大的帮助。因为我们可以接触到高清晰的图像块,即使是在较远距离的目标;
- 在一个锥视图中的同一类的多个实例(比如两个站在一起的人)。因为我们假定的是一个锥视图有单一的兴趣目标,当有多个实例出现时,就会产生困惑,因此输出混合的分割结果。如果我们能够提出一个锥视图可以有多个3D边界框,这个问题就可以得到缓解。
- 有时候我们的2D检测器没有检测到目标,因为较暗的光线或者较强的遮挡。因为我们的锥视图推举是基于候选区域,没有给定2D目标检测就没法进行3D检测。
测试结果
| Benchmark | easy | moderate | hard |
|---|---|---|---|
| Car (Detection) | 96.482544 | 90.305161 | 87.626389 |
| Car (3D Detection) | 83.960136 | 69.317223 | 62.751877 |
| Car (Bird’s Eye View) | 87.790451 | 82.268562 | 74.436012 |
| Pedestrian (Detection) | 84.555908 | 76.389679 | 72.438660 |
| Pedestrian (3D Detection) | 66.706535 | 55.950409 | 48.960270 |
| Pedestrian (Bird’s Eye View) | 71.108696 | 61.005306 | 53.808998 |
| Cyclist (Detection) | 88.994469 | 72.703659 | 70.610924 |
| Cyclist (3D Detection) | 69.160477 | 51.361362 | 47.442177 |
| Cyclist (Bird’s Eye View) | 74.139236 | 56.213768 | 53.002541 |
2D object detection results
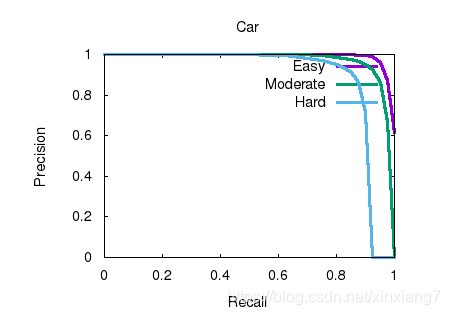
3D object detection results
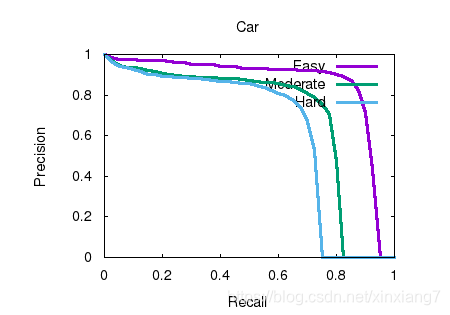
Bird’s eye view results
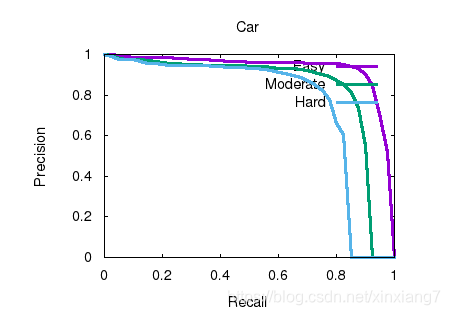
2D object detection results

3D object detection results
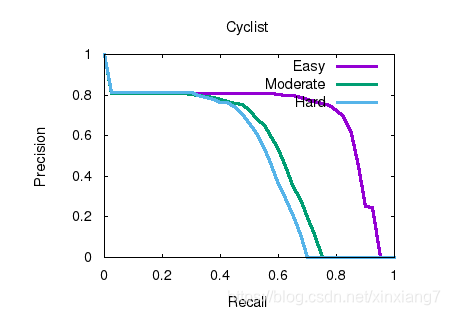
Bird’s eye view results